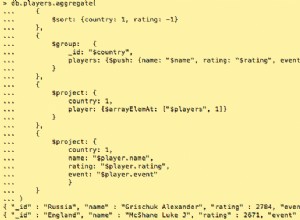
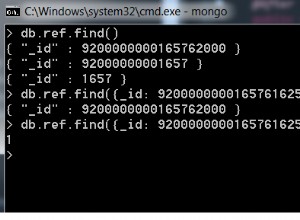
Corrigé :
sudo sysctl net.ipv4.tcp_tw_reuse=1
Ensuite, redémarrez mongo.
Alternativement, vous pouvez l'ajouter à /etc/sysctl.conf (il sera donc exécuté au redémarrage) :
net.ipv4.tcp_tw_reuse=1
Ensuite, exécutez ceci pour recharger (sans avoir à redémarrer)
sudo sysctl -p /etc/sysctl.conf
Ce "correctif" désactivera l'état d'attente pour les sockets TCP (à l'échelle du serveur). Donc, ce n'est vraiment pas une solution du tout. Cependant, jusqu'à ce que mongo réduise son état d'attente à l'aide de SO_LINGER, un grand nombre de sockets de serveur se regrouperont dans l'état TIME_WAIT et resteront inutilisables pour les nouvelles connexions. Vous pouvez voir le nombre de connexions dans TIME_WAIT avec ceci :
netstat -an | grep TIME_WAIT | wc -l
Avec cela, j'ai pu le voir échouer à environ 28 000 connexions TIME_WAIT. En utilisant cet indicateur de noyau :
sysctl net.ipv4.ip_local_port_range="18000 65535"
Le serveur tombe en panne à 45 000 connexions. Ainsi, pour reproduire l'erreur plus facilement, vous pouvez réduire la plage à 200 ou quelque chose de petit.
Donc, le résultat de ceci était une question de programmation après tout (comme vous pouvez le voir sur le dernier lien):
Option TCP SO_LINGER (zéro ) - quand c'est nécessaire
https://alas.matf.bg.ac.rs /manuals/lspe/snode=105.html