Sauvegardes - l'une des choses les plus importantes à prendre en compte lors de la gestion des bases de données. On dit qu'il existe deux types de personnes - celles qui sauvegardent leurs données et celles qui sauvegardent leurs données. Dans cet article de blog, nous discuterons des bonnes pratiques concernant les sauvegardes et vous montrerons comment créer un système de sauvegarde fiable à l'aide de ClusterControl.
Nous verrons comment ClusterControl vous offre une gestion centralisée des sauvegardes pour MySQL, MariaDB, MongoDB et PostgreSQL. Il vous fournit des sauvegardes à chaud de grands ensembles de données, une récupération ponctuelle, un chiffrement des données au repos et en transit, l'intégrité des données via la vérification automatique de la restauration, des sauvegardes dans le cloud (AWS, Google et Azure) pour la reprise après sinistre, des politiques de rétention pour assurer la conformité , ainsi que des alertes et des rapports automatisés.
Types de sauvegarde
Il existe deux principaux types de sauvegarde que nous pouvons effectuer dans ClusterControl :
- Sauvegarde logique :la sauvegarde des données est stockée dans un format lisible par l'homme comme SQL
- Sauvegarde physique :la sauvegarde contient des données binaires
Les deux se complètent - la sauvegarde logique vous permet (plus ou moins facilement) de récupérer jusqu'à une seule ligne de données. Les sauvegardes physiques nécessiteraient plus de temps pour accomplir cela, mais, d'un autre côté, elles vous permettent de restaurer un hôte entier très rapidement (ce qui peut prendre des heures, voire des jours lors de l'utilisation de la sauvegarde logique).
ClusterControl prend en charge la sauvegarde pour MySQL/MariaDB/Percona Server, PostgreSQL et MongoDB.
Planifier la sauvegarde
Le démarrage d'une sauvegarde dans ClusterControl est simple et efficace grâce à un assistant. La planification d'une sauvegarde offre une convivialité et une accessibilité à d'autres fonctionnalités telles que le chiffrement, le test/la vérification automatique de la sauvegarde ou l'archivage dans le cloud.
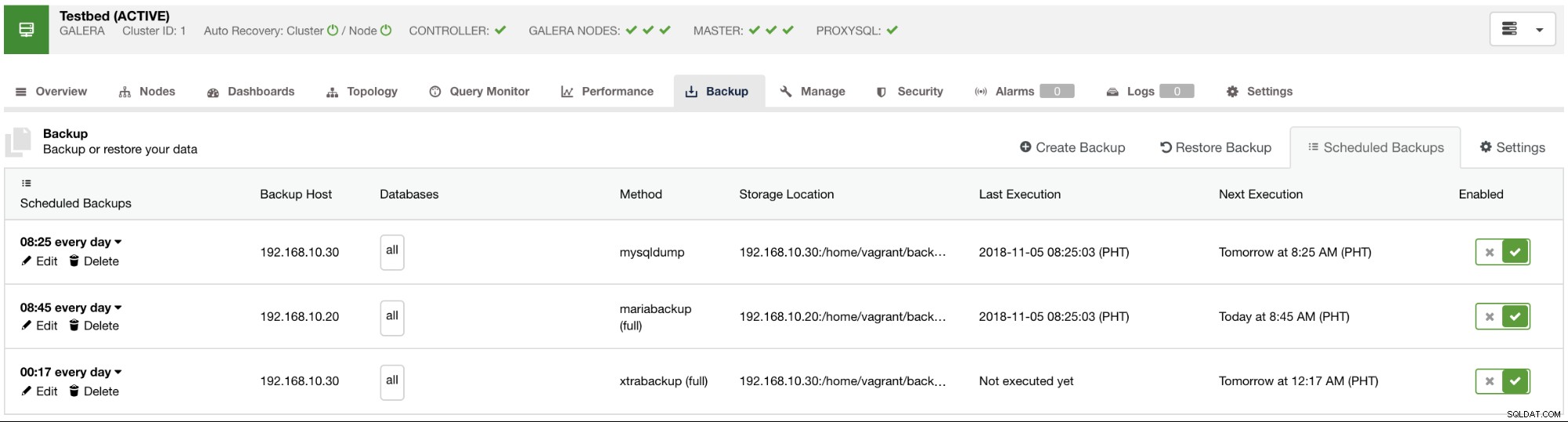
Les sauvegardes planifiées disponibles seront répertoriées dans l'onglet Sauvegardes planifiées, comme illustré dans l'image ci-dessous :
En tant que bonne pratique pour planifier une sauvegarde, vous devez déjà avoir défini votre rétention de sauvegarde et une sauvegarde quotidienne est recommandée. Cependant, cela dépend également des données dont vous avez besoin, du trafic auquel vous pouvez vous attendre et de la disponibilité des données chaque fois que vous en avez besoin, en particulier lors de la récupération de données où des données ont été accidentellement supprimées ou une corruption de disque - qui sont inévitables. Il existe également des situations où la perte de données est reproductible ou peut être dupliquée manuellement, comme par exemple la génération de rapports, les vignettes ou les données mises en cache. Bien que la question repose sur la rapidité avec laquelle vous en avez besoin chaque fois qu'une catastrophe se produit; dans la mesure du possible, vous souhaiterez effectuer quotidiennement des sauvegardes mysqldump et xtrabackup pour MySQL en tirant parti de la disponibilité des sauvegardes logiques et physiques. Pour couvrir encore plus de bases, vous pouvez planifier plusieurs exécutions xtrabackup incrémentielles par jour. Cela pourrait économiser de l'espace disque, des E/S disque ou même des E/S CPU plutôt que d'effectuer une sauvegarde complète.
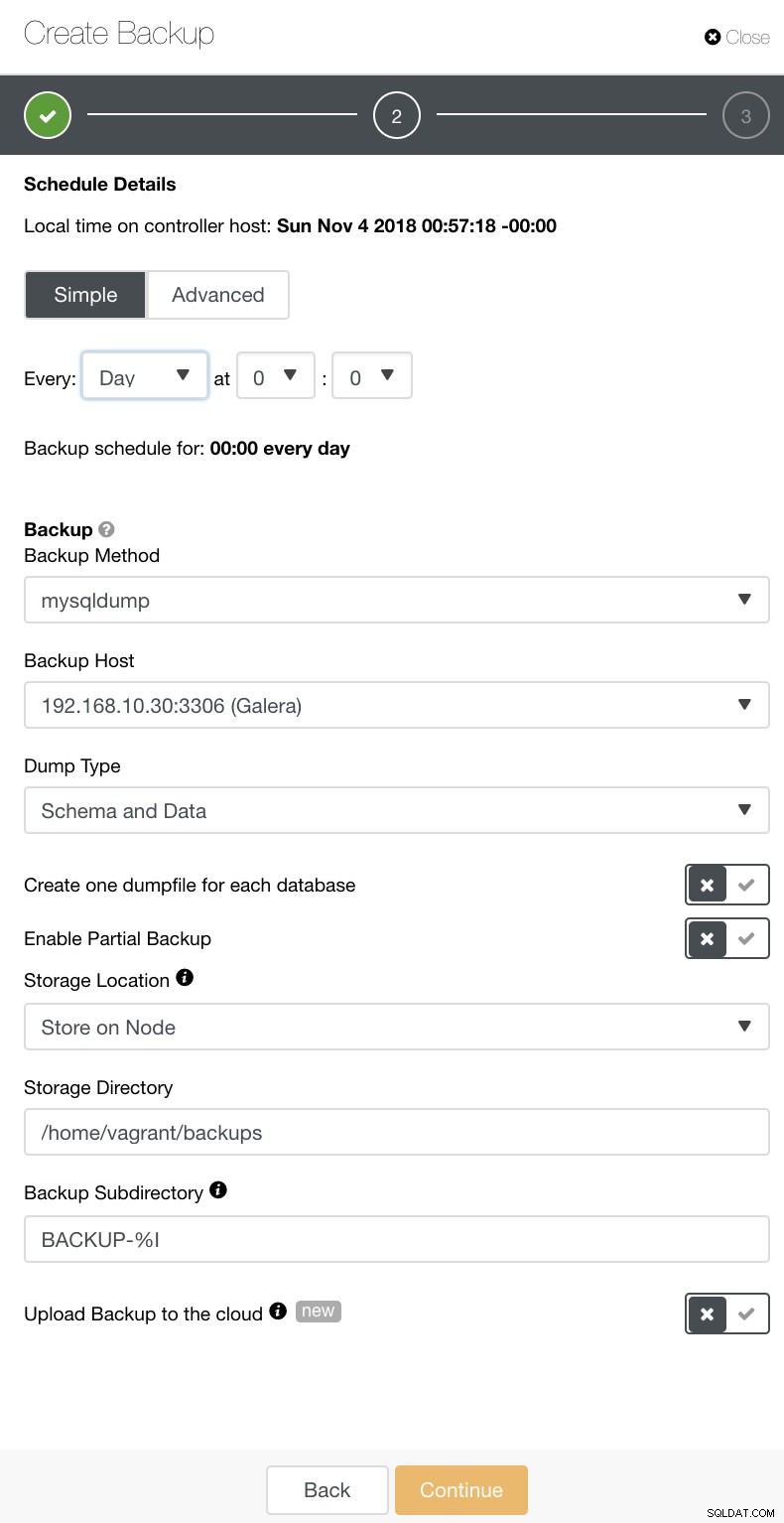
Dans ClusterControl, vous pouvez facilement planifier ces différents types de sauvegardes. Il y a quelques paramètres à décider. Vous pouvez stocker une sauvegarde sur le contrôleur ou localement, sur le nœud de base de données où la sauvegarde est effectuée. Vous devez décider de l'emplacement dans lequel la sauvegarde doit être stockée et des bases de données que vous souhaitez sauvegarder - ensemble de données ou schémas séparés ? Voir l'image ci-dessous :
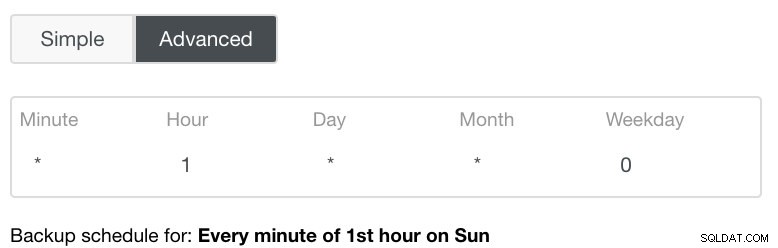
Le paramètre Avancé tirerait parti d'une configuration de type cron pour plus de granularité. Voir l'image ci-dessous :
Chaque fois qu'un échec se produit, ClusterControl gère ces problèmes efficacement et produit des journaux pour un diagnostic plus approfondi de l'échec de la sauvegarde.
Selon le type de sauvegarde que vous avez choisi, il existe des paramètres distincts à configurer. Pour Xtrabackup et Galera Cluster, vous pouvez avoir la possibilité de choisir les paramètres que votre sauvegarde physique appliquera lors de son exécution. Voir ci-dessous :
- Utiliser la compression
- Niveau de compression
- Désynchroniser le nœud pendant la sauvegarde
- Verrouillages de sauvegarde
- Verrouiller DDL par table
- Threads de copie parallèle Xtrabackup
- Taux d'accélération du streaming réseau (Mo/s)
- Utiliser PIGZ pour gzip parallèle
- Activer le chiffrement
- Rétention
Vous pouvez voir, dans l'image ci-dessous, comment vous pouvez marquer les options en conséquence et il y a des icônes d'info-bulle qui fournissent plus d'informations sur les options que vous souhaitez exploiter pour votre politique de sauvegarde.
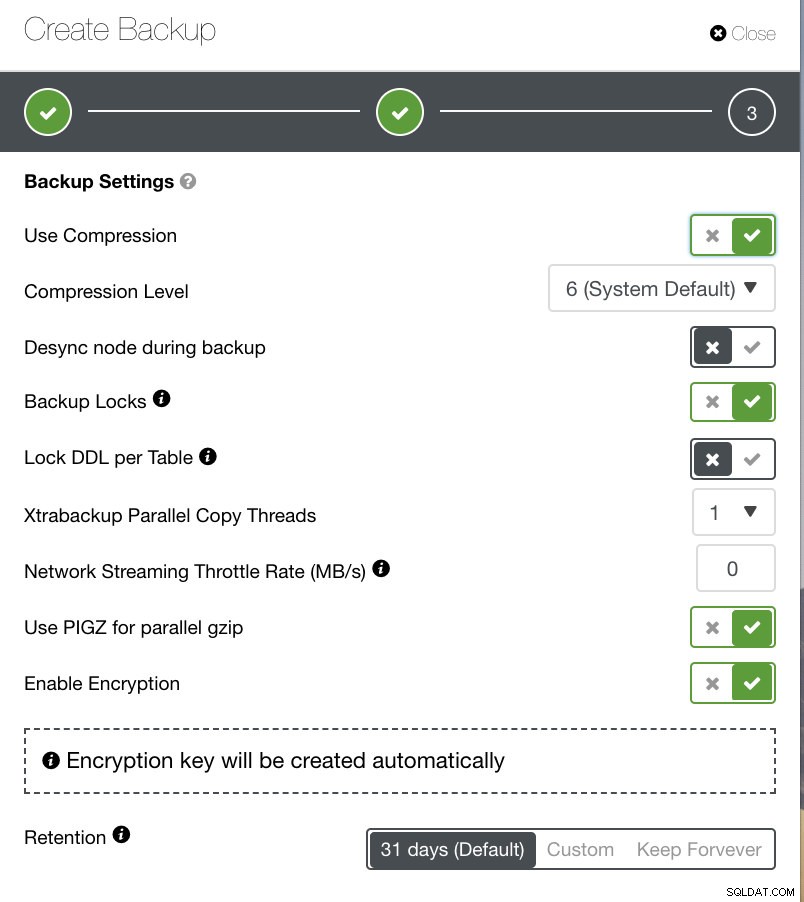
En fonction de votre politique de sauvegarde, ClusterControl peut être adapté conformément aux meilleures pratiques pour mettre à jour vos sauvegardes disponibles. Lors de la définition de votre politique de sauvegarde, il est prévu que votre configuration requise soit disponible du matériel au logiciel en passant par le cloud, la durabilité, la haute disponibilité ou l'évolutivité.
Lorsque vous effectuez des sauvegardes sur un cluster Galera, il est recommandé de définir le nœud Galera wsrep_desync=ON pendant l'exécution de la sauvegarde. Cela empêchera le nœud de participer au contrôle de flux et protégera l'ensemble du cluster contre les retards de réplication, en particulier si vos données à sauvegarder sont volumineuses. Dans ClusterControl, gardez à l'esprit que cela peut également supprimer votre nœud de sauvegarde cible de l'ensemble d'équilibrage de charge. Cela est particulièrement vrai si vous utilisez des proxys HAProxy, ProxySQL ou MaxScale. Si vous avez configuré le gestionnaire d'alertes au cas où le nœud serait désynchronisé, vous pouvez le désactiver pendant la période où la sauvegarde a été déclenchée.
Un autre moyen populaire de minimiser l'impact d'une sauvegarde sur un cluster Galera ou un maître de réplication consiste à déployer un esclave de réplication, puis à l'utiliser comme source de sauvegardes - de cette façon, Galera Cluster ne sera affecté à aucun moment car la sauvegarde sur le l'esclave est découplé du cluster.
Vous pouvez déployer un tel esclave en quelques clics à l'aide de ClusterControl. Voir l'image ci-dessous :
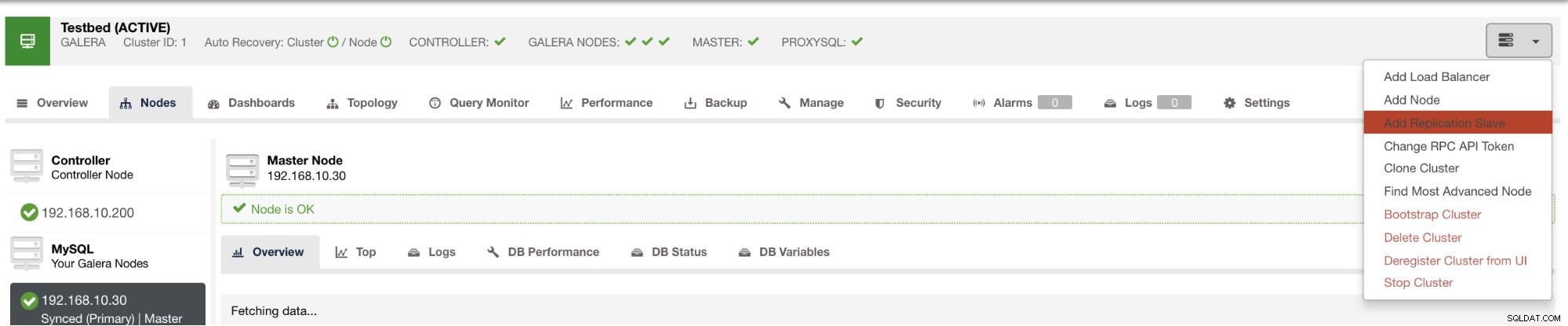
et une fois que vous avez cliqué sur ce bouton, vous pouvez sélectionner les nœuds sur lesquels configurer un esclave. Assurez-vous que la journalisation binaire des nœuds est activée. L'activation du journal binaire peut également être effectuée via ClusterControl, ce qui ajoute plus de faisabilité pour l'administration de votre maître souhaité. Voir l'image ci-dessous :
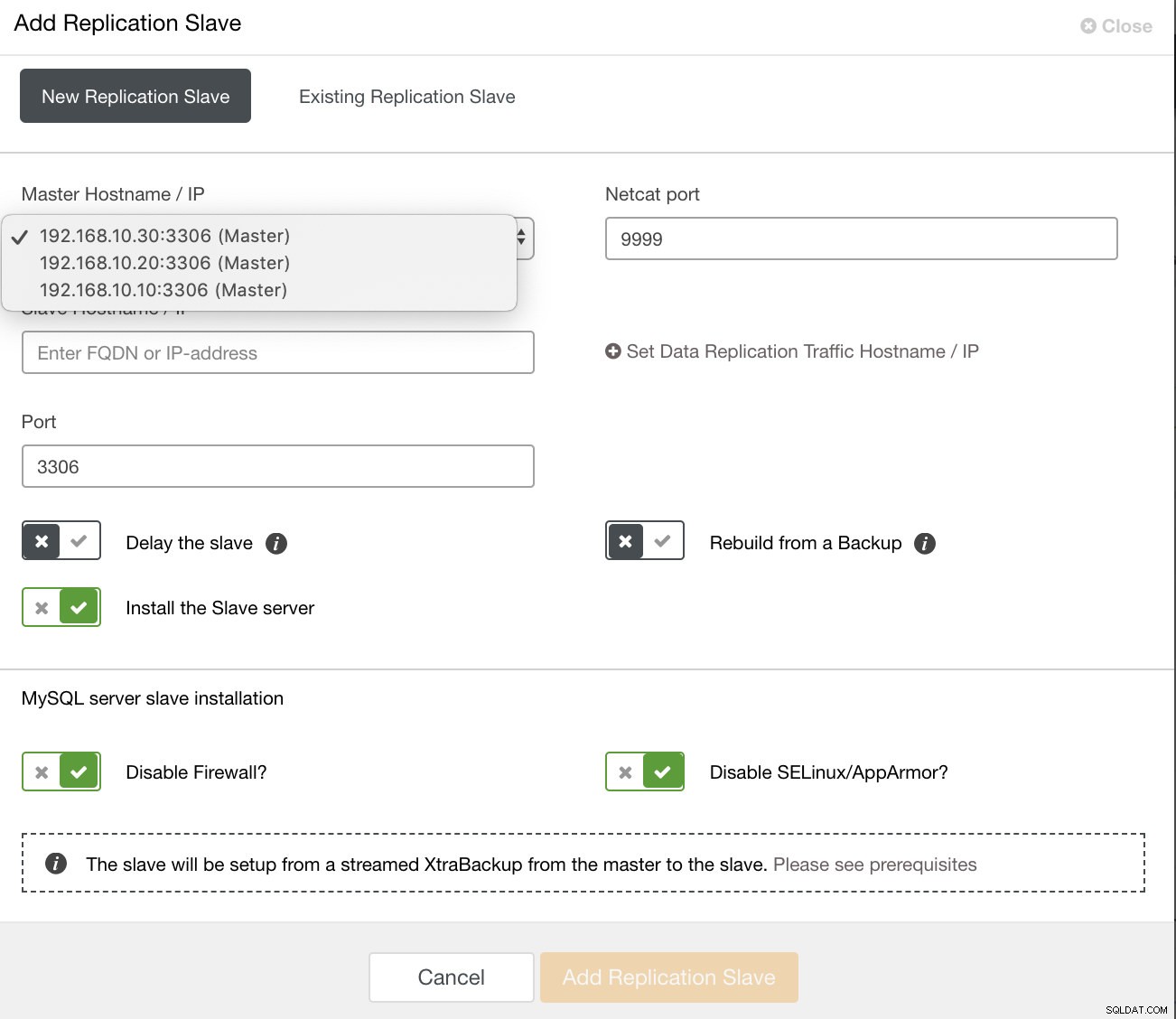
et vous pouvez également configurer un esclave de réplication existant,
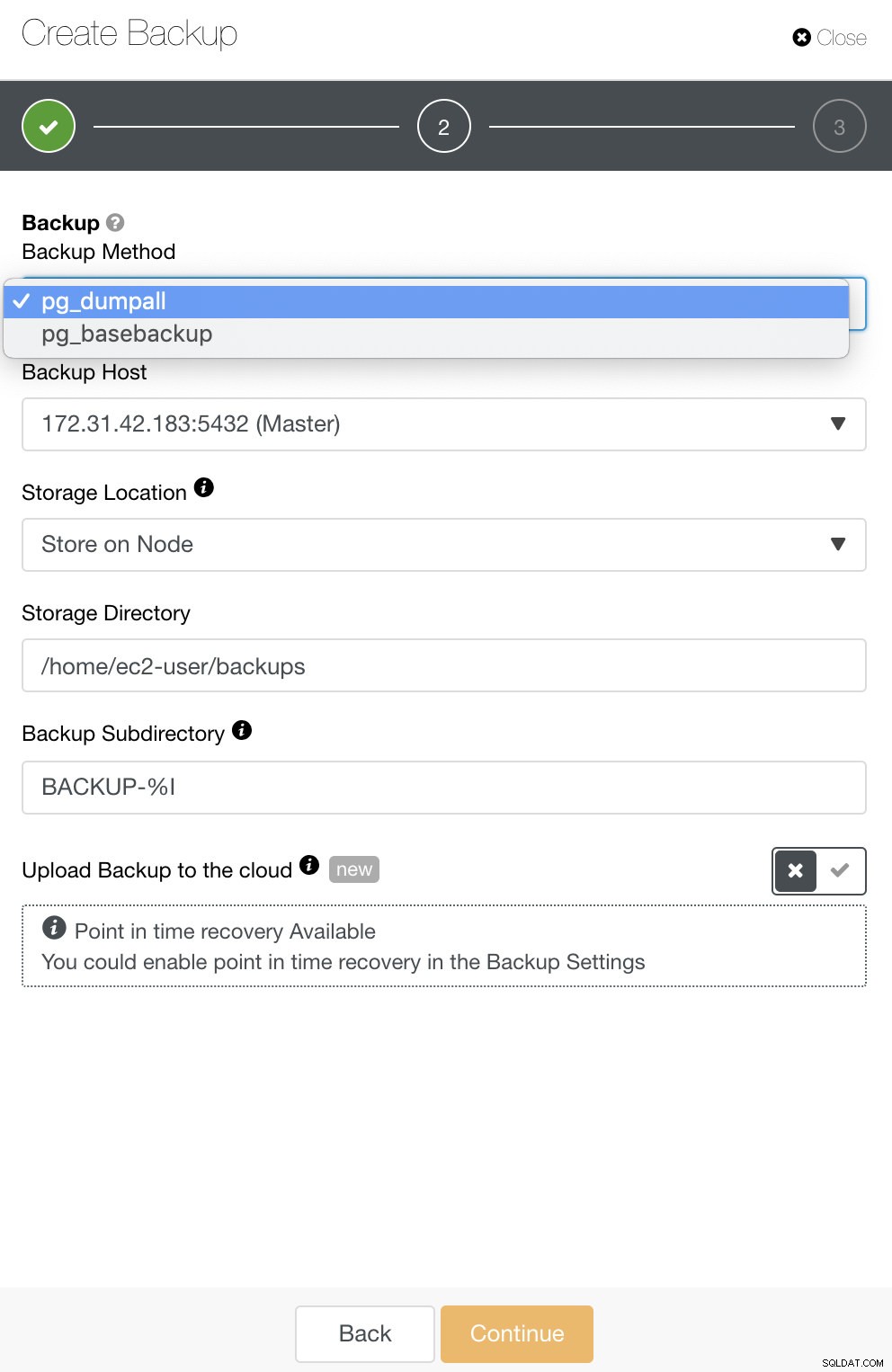
Pour PostgreSQL, vous avez la possibilité de sauvegarder des sauvegardes logiques ou physiques. Dans ClusterControl, vous pouvez exploiter vos sauvegardes PostgreSQL en sélectionnant pg_dump ou pg_basebackup. pg_basebackup ne fonctionnera pas pour les versions antérieures à 9.3.
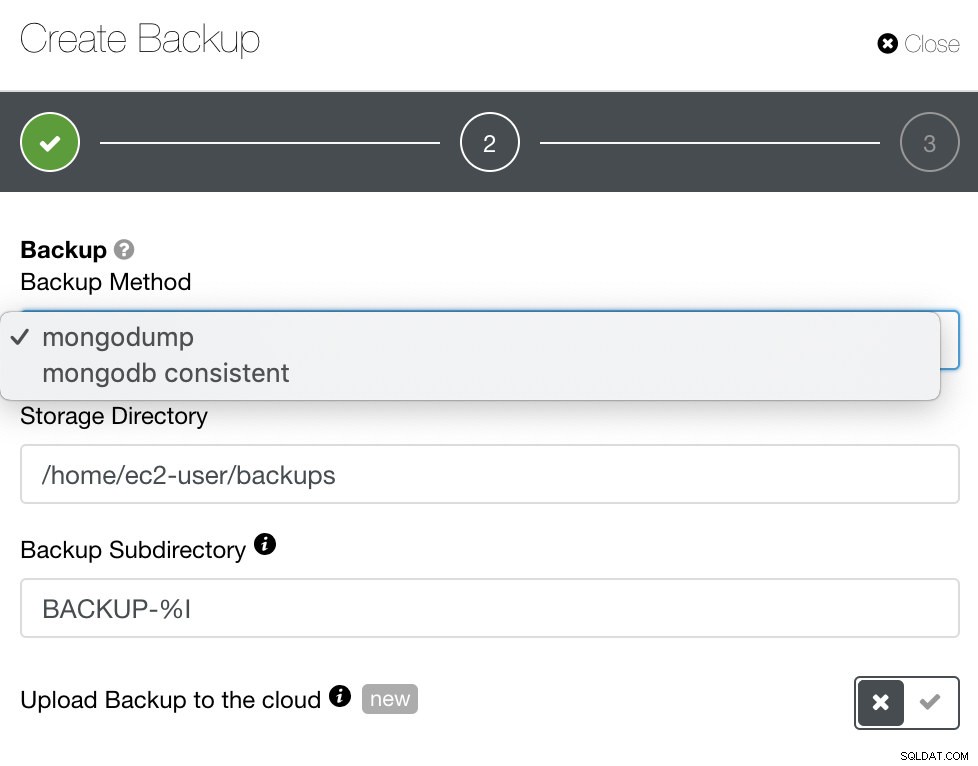
Pour MongoDB, ClusterControl propose mongodump ou mongodb cohérent. Vous devrez peut-être noter que mongodb consistent ne prend pas en charge RHEL 7, mais vous pourrez peut-être l'installer manuellement.
Par défaut, ClusterControl listera un rapport pour toutes les sauvegardes qui ont été prises, celles qui ont réussi ou celles qui ont échoué. Voir ci-dessous :
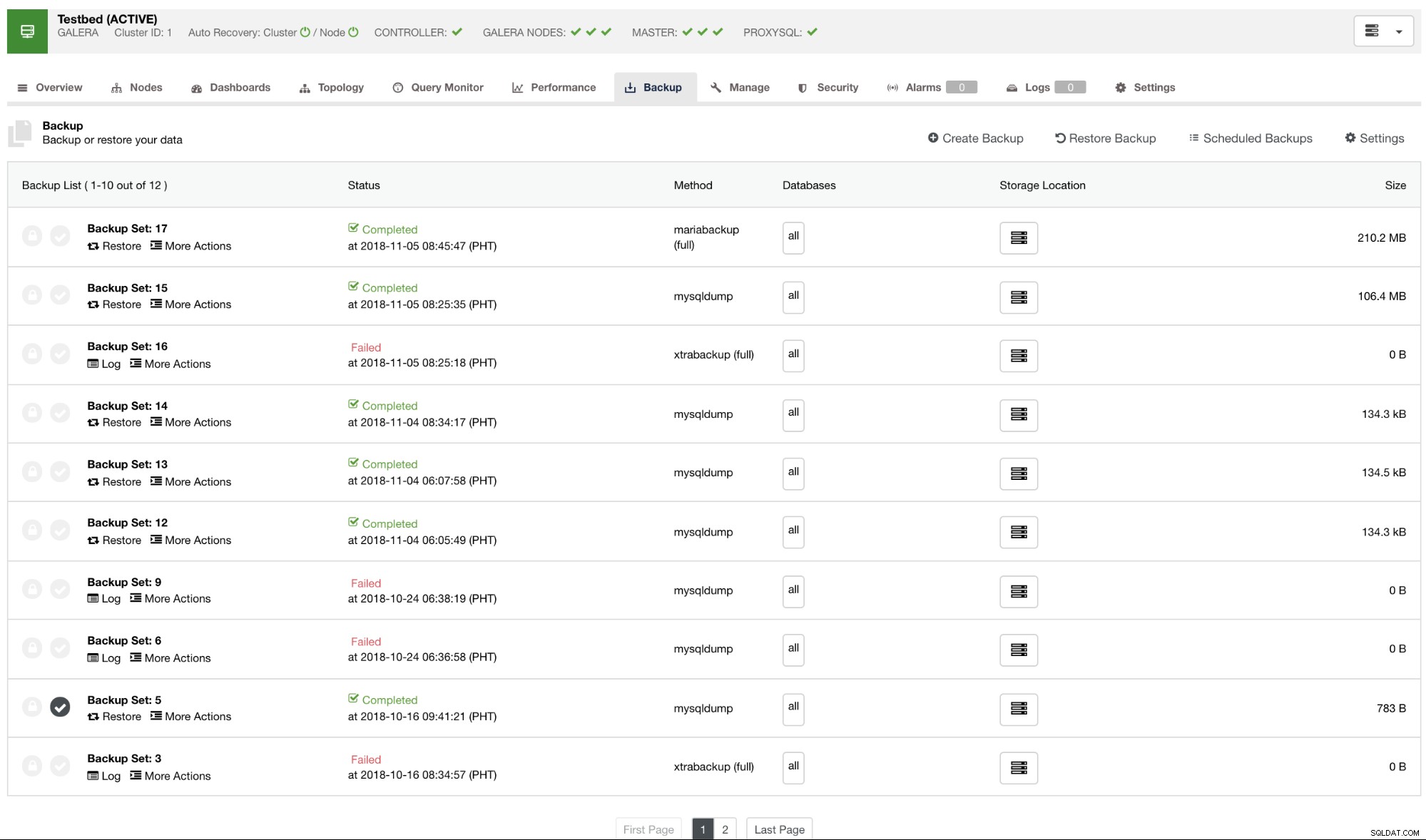
Vous pouvez consulter la liste des rapports de sauvegarde qui ont été créés ou planifiés à l'aide de ClusterControl. Dans la liste, vous pouvez afficher les journaux pour une enquête et un diagnostic plus approfondis. Par exemple, si la sauvegarde s'est terminée correctement selon la politique de sauvegarde souhaitée, si la compression et le chiffrement sont correctement définis ou si la taille des données de sauvegarde souhaitée est correcte. C'est un bon moyen d'effectuer une vérification rapide :si votre jeu de données a une taille d'environ 1 Go, il est impossible qu'une sauvegarde complète soit aussi petite que 100 Ko ; quelque chose a dû mal tourner à un moment donné.
Reprise après sinistre
Le stockage des sauvegardes dans le cluster (soit directement sur un nœud de base de données, soit sur l'hôte ClusterControl) est pratique lorsque vous souhaitez restaurer rapidement vos données :tous les fichiers de sauvegarde sont en place et peuvent être décompressés et restaurés rapidement. En ce qui concerne la reprise après sinistre (DR), ce n'est peut-être pas la meilleure option. Différents problèmes peuvent survenir - les serveurs peuvent tomber en panne, le réseau peut ne pas fonctionner de manière fiable, même des centres de données entiers peuvent ne pas être accessibles en raison d'une sorte de panne. Cela peut arriver si vous travaillez avec un petit fournisseur de services avec un seul centre de données ou un fournisseur mondial comme Amazon Web Services. Il n'est donc pas sûr de conserver tous vos œufs dans un seul panier - vous devez vous assurer d'avoir une copie de votre sauvegarde stockée dans un emplacement externe. ClusterControl prend en charge Amazon S3, Google Storage et Azure Cloud Storage .
Pour ceux qui souhaitent mettre en œuvre leurs propres politiques DR, les sauvegardes de ClusterControl sont stockées dans un répertoire bien structuré. Vous avez également la possibilité de télécharger votre sauvegarde sur le cloud. Voir l'image ci-dessous :
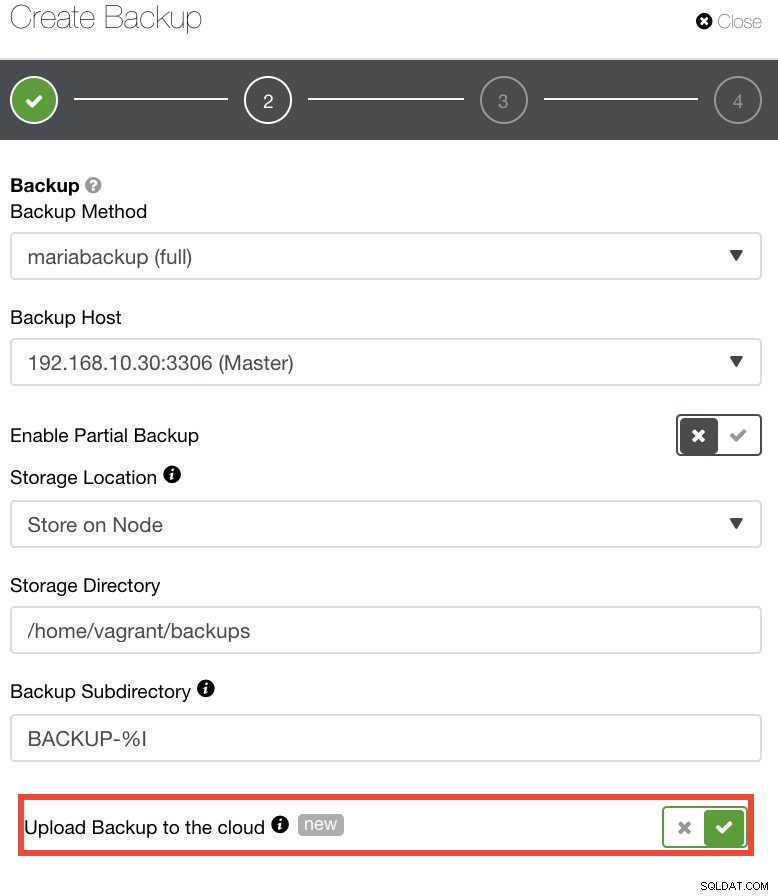
Vous pouvez sélectionner et télécharger sur Amazon Web Services, Google Cloud et Microsoft Azure. Voir l'image ci-dessous :
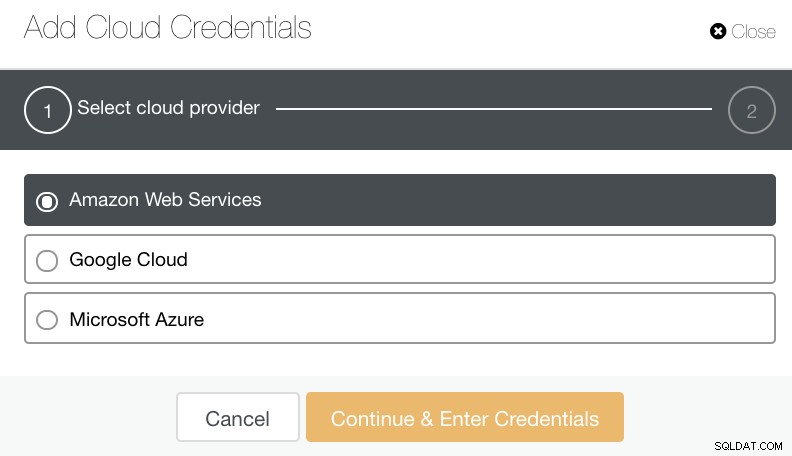
Comme bonne pratique lors de l'archivage de vos sauvegardes de base de données, assurez-vous que votre destination cloud cible est basée sur la même région que vos serveurs de base de données, ou au moins la plus proche. Assurez-vous qu'il offre une disponibilité, une durabilité et une évolutivité élevées ; car vous devez tenir compte de la fréquence et de l'immédiat besoin de vos données.
Outre la création d'une sauvegarde logique ou physique pour votre DR, la création d'un instantané complet de vos données (par exemple, à l'aide d'un instantané LVM, d'instantanés Amazon EBS ou d'instantanés de volume si vous utilisez le système de fichiers Veritas) sur le nœud particulier peut augmenter votre récupération de sauvegarde. Vous pouvez également utiliser WAL (pour Postgres) pour votre Point In Time Recovery (PITR) ou vos journaux binaires MySQL pour votre PITR. Ainsi, vous devez considérer que vous devrez peut-être créer votre propre archivage pour votre PITR. Il est donc tout à fait acceptable de créer et de déployer votre propre ensemble de scripts et de gérer la reprise après sinistre en fonction de vos besoins précis.
Un autre excellent moyen de mettre en œuvre une politique de récupération après sinistre consiste à utiliser un esclave de réplication asynchrone - quelque chose que nous avons mentionné plus tôt dans ce billet de blog. Vous pouvez déployer un tel esclave asynchrone dans un emplacement distant, un autre centre de données peut-être, puis l'utiliser pour effectuer des sauvegardes et les stocker localement sur cet esclave. Bien sûr, vous souhaiterez effectuer une sauvegarde locale de votre cluster pour l'avoir localement si vous avez besoin de récupérer le cluster. Le déplacement des données entre les centres de données peut prendre beaucoup de temps, donc avoir des fichiers de sauvegarde disponibles localement peut vous faire gagner du temps. Si vous perdez l'accès à votre cluster de production principal, vous pouvez toujours avoir accès à l'esclave. Cette configuration est très flexible - d'abord, vous avez un hôte MySQL en cours d'exécution avec vos données de production, il ne devrait donc pas être trop difficile de déployer votre application complète sur le site DR. Vous disposerez également de sauvegardes de vos données de production que vous pourrez utiliser pour faire évoluer votre environnement DR.
Enfin et surtout, une sauvegarde qui n'a pas été testée reste une sauvegarde non vérifiée, alias Schroedinger Backup. Pour vous assurer que vous disposez d'une sauvegarde fonctionnelle, vous devez effectuer un test de récupération. ClusterControl offre un moyen de vérifier et de tester automatiquement votre sauvegarde.
Nous espérons que cela vous donnera suffisamment d'informations pour créer une procédure de sauvegarde sûre et fiable pour vos bases de données open source.



