ClusterControl 1.6 est livré avec une intégration plus étroite avec AWS, Azure et Google Cloud, il est donc désormais possible de lancer de nouvelles instances et de déployer MySQL, MariaDB, MongoDB et PostgreSQL directement depuis l'interface utilisateur de ClusterControl. Dans ce blog, nous allons vous montrer comment déployer un cluster sur Amazon Web Services.
Notez que cette nouvelle fonctionnalité nécessite deux modules appelés clustercontrol-cloud et clustercontrol-clud . Le premier est un démon d'assistance qui étend la capacité CMON de communication cloud, tandis que le second est un client de gestionnaire de fichiers pour télécharger et télécharger des fichiers sur des instances cloud. Les deux packages sont des dépendances du package d'interface utilisateur clustercontrol, qui sera installé automatiquement s'il n'existe pas. Consultez la page de documentation des composants pour plus de détails.
Identifiants cloud
ClusterControl vous permet de stocker et de gérer vos identifiants cloud sous Intégrations (menu latéral) -> Fournisseurs Cloud :
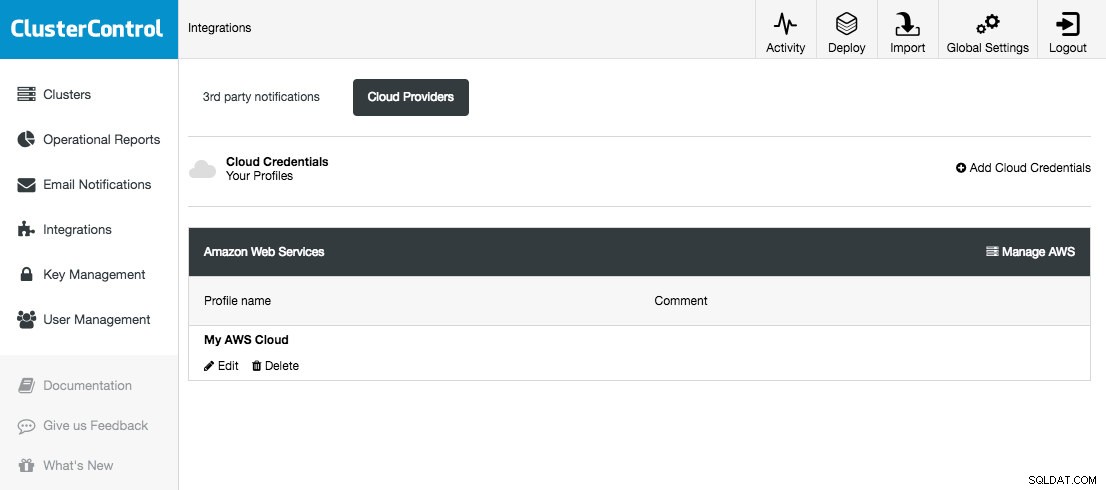
Les plates-formes cloud prises en charge dans cette version sont Amazon Web Services, Google Cloud Platform et Microsoft Azure. Sur cette page, vous pouvez ajouter de nouveaux identifiants cloud, gérer ceux qui existent déjà et également vous connecter à votre plateforme cloud pour gérer les ressources.
Les informations d'identification qui ont été configurées ici peuvent être utilisées pour :
- Gérer les ressources cloud
- Déployer des bases de données dans le cloud
- Télécharger la sauvegarde sur le stockage cloud
Voici ce que vous verriez si vous cliquiez sur le bouton « Gérer AWS » :
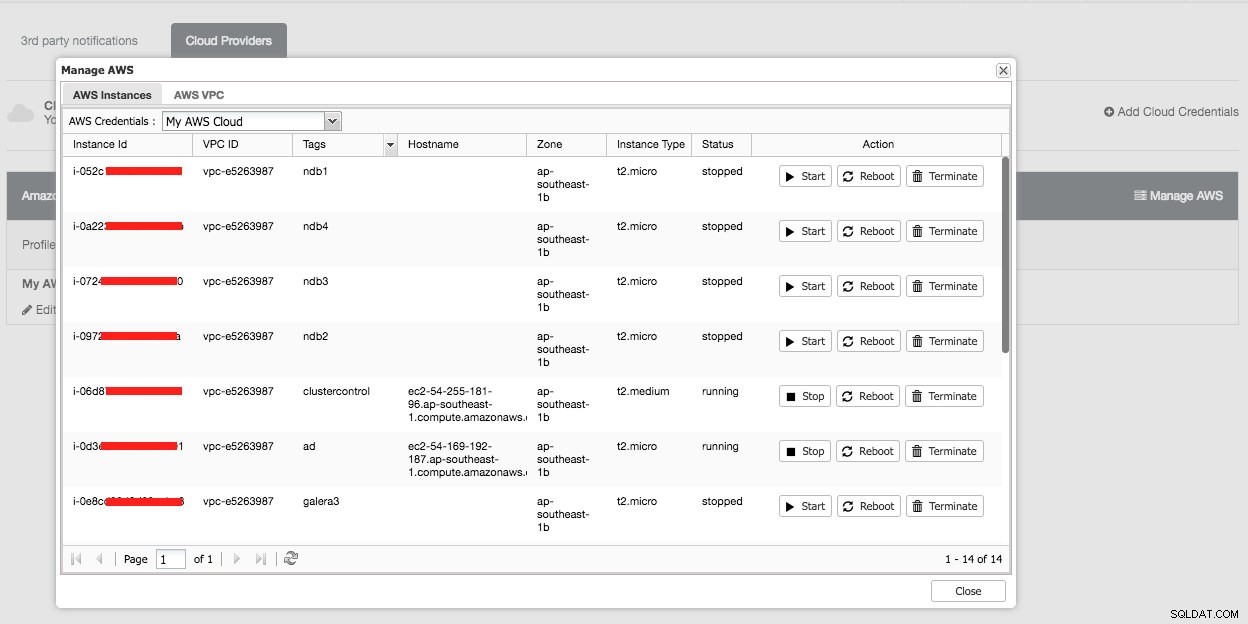
Vous pouvez effectuer des tâches de gestion simples sur vos instances cloud. Vous pouvez également vérifier les paramètres VPC sous l'onglet "AWS VPC", comme illustré dans la capture d'écran suivante :
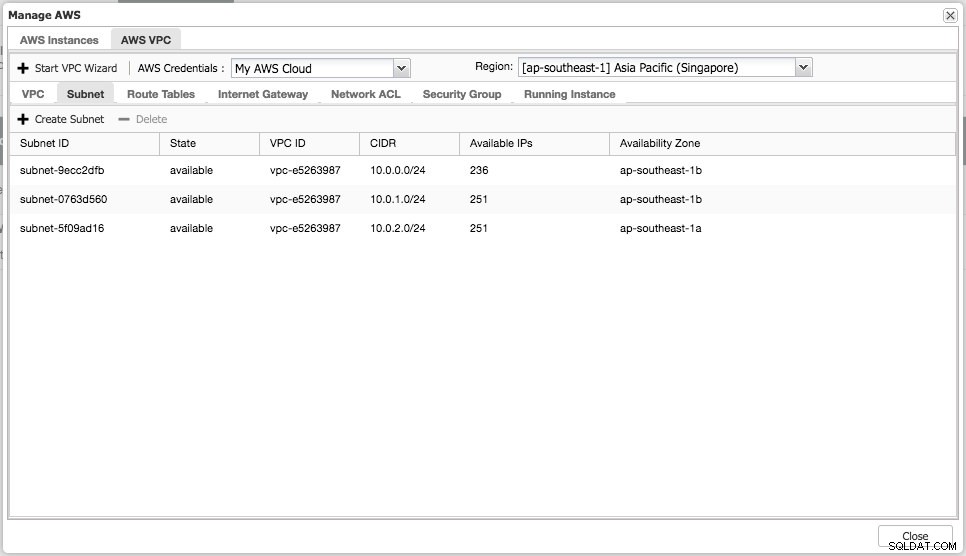
Les fonctionnalités ci-dessus sont utiles comme référence, en particulier lors de la préparation de vos instances cloud avant de commencer les déploiements de bases de données.
Déploiement de la base de données sur le cloud
Dans les versions précédentes de ClusterControl, le déploiement de la base de données sur le cloud était traité de la même manière que le déploiement sur des hôtes standard, où vous deviez créer les instances cloud au préalable, puis fournir les détails de l'instance et les informations d'identification dans l'assistant "Déployer le cluster de bases de données". La procédure de déploiement ignorait toute fonctionnalité et flexibilité supplémentaires dans l'environnement cloud, telles que l'attribution dynamique d'adresses IP et de noms d'hôtes, l'adresse IP publique NAT, l'élasticité du stockage, la configuration du réseau de cloud privé virtuel, etc.
Avec la version 1.6, il vous suffit de fournir les identifiants cloud, qui peuvent être gérés via l'interface "Cloud Providers" et de suivre l'assistant de déploiement "Deploy in the Cloud". Dans l'interface utilisateur de ClusterControl, cliquez sur Déployer et les options suivantes vous seront présentées :
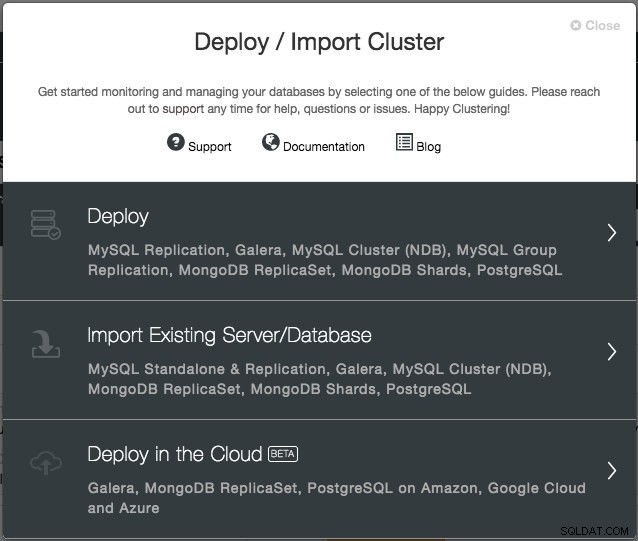
À l'heure actuelle, les fournisseurs de cloud pris en charge sont les trois principaux acteurs - Amazon Web Service (AWS), Google Cloud et Microsoft Azure. Nous allons intégrer davantage de fournisseurs dans la future version.
Dans la première page, les options Détails du cluster vous seront présentées :
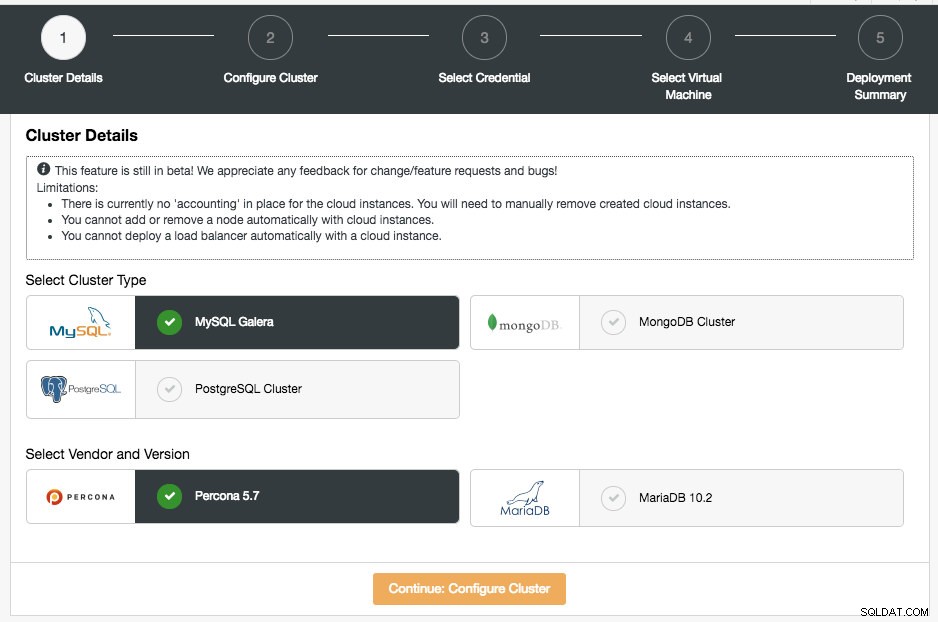
Dans cette section, vous devrez sélectionner le type de cluster pris en charge, MySQL Galera Cluster, MongoDB Replica Set ou PostgreSQL Streaming Replication. L'étape suivante consiste à choisir le fournisseur pris en charge pour le type de cluster sélectionné. Pour le moment, les fournisseurs et versions suivants sont pris en charge :
- Cluster MySQL Galera – Percona XtraDB Cluster 5.7, MariaDB 10.2
- Cluster MongoDB :MongoDB 3.4 par MongoDB, Inc et Percona Server pour MongoDB 3.4 par Percona (ensemble de réplicas uniquement).
- Cluster PostgreSQL - PostgreSQL 10.0 (réplication en continu uniquement).
À l'étape suivante, la boîte de dialogue suivante s'affichera :
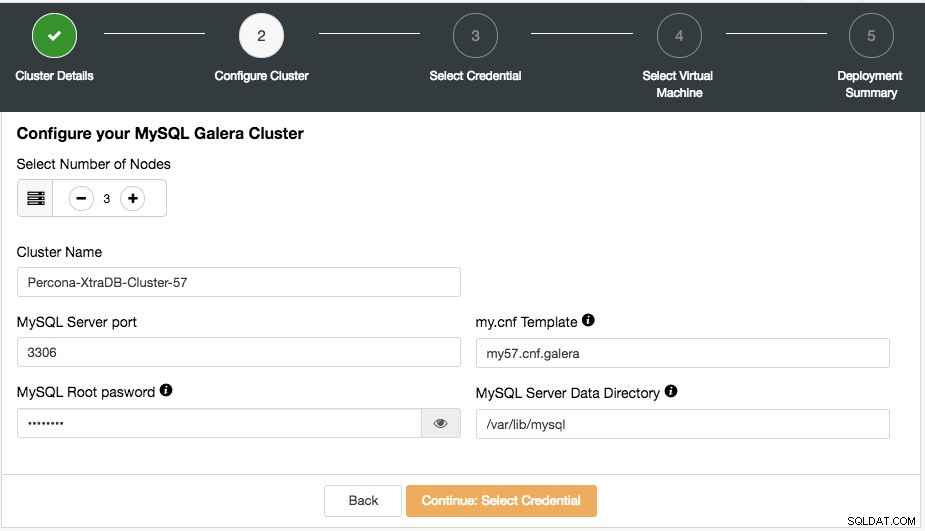
Ici, vous pouvez configurer le type de cluster sélectionné en conséquence. Choisissez le nombre de nœuds. Le nom du cluster sera utilisé comme balise d'instance, afin que vous puissiez facilement reconnaître ce déploiement dans le tableau de bord de votre fournisseur de cloud. Aucun espace n'est autorisé dans le nom du cluster. My.cnf Template est le modèle de fichier de configuration que ClusterControl utilisera pour déployer le cluster. Il doit être situé sous /usr/share/cmon/templates sur l'hôte ClusterControl. Les autres champs sont assez explicites.
La boîte de dialogue suivante consiste à sélectionner les informations d'identification cloud :
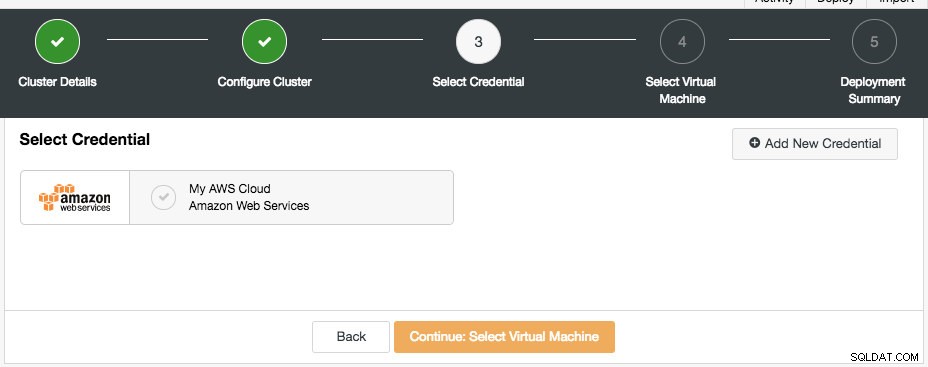
Vous pouvez choisir les identifiants cloud existants ou en créer un nouveau en cliquant sur le bouton "Ajouter un nouvel identifiant". L'étape suivante consiste à choisir la configuration de la machine virtuelle :
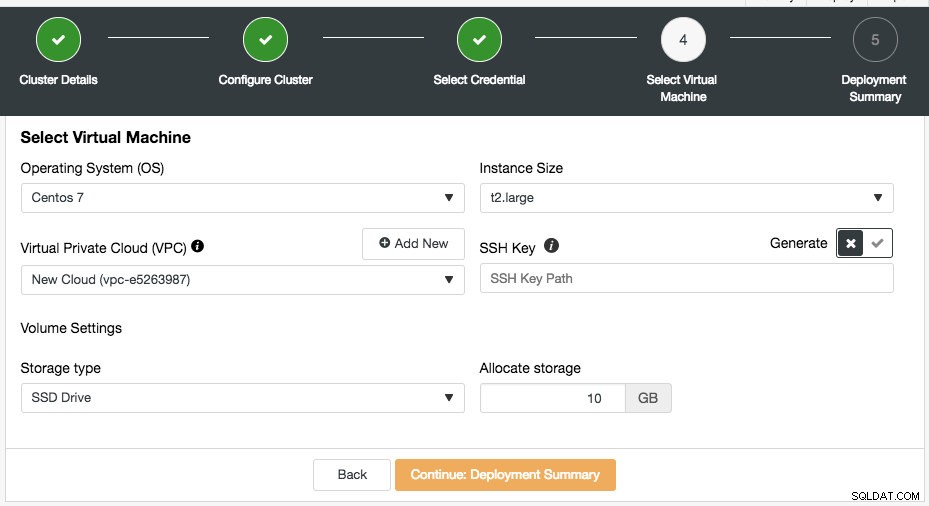
La plupart des paramètres de cette étape sont renseignés dynamiquement à partir du fournisseur de cloud par les informations d'identification choisies. Vous pouvez configurer le système d'exploitation, la taille de l'instance, le paramètre VPC, le type et la taille de stockage et également spécifier l'emplacement de la clé SSH sur l'hôte ClusterControl. Vous pouvez également laisser ClusterControl générer une nouvelle clé spécifiquement pour ces instances. Lorsque vous cliquez sur le bouton "Ajouter un nouveau" à côté de Virtual Private Cloud, un formulaire vous sera présenté pour créer un nouveau VPC :
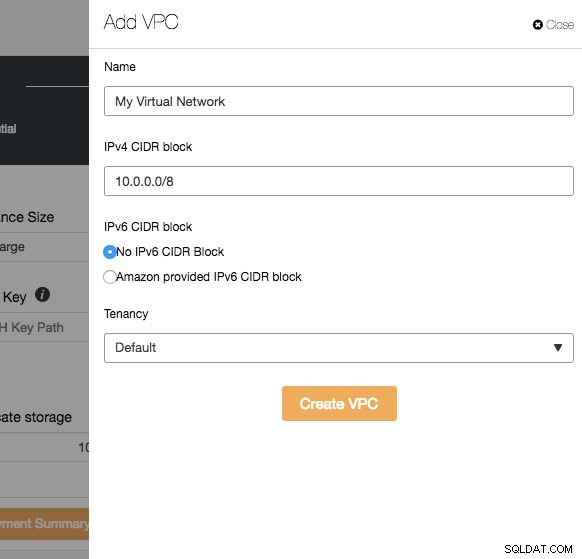
Le VPC est une infrastructure de réseau logique que vous avez au sein de votre plate-forme cloud. Vous pouvez configurer votre VPC en modifiant sa plage d'adresses IP, créer des sous-réseaux, configurer des tables de routage, des passerelles réseau et des paramètres de sécurité. Il est recommandé de déployer votre infrastructure de base de données dans ce réseau pour l'isolement, la sécurité et le contrôle du routage.
Lors de la création d'un nouveau VPC, spécifiez le nom du VPC et le bloc d'adresse IPv4 avec le sous-réseau. Ensuite, choisissez si IPv6 doit faire partie du réseau et l'option de location. Vous pouvez ensuite utiliser ce réseau virtuel pour votre infrastructure de base de données.
La dernière étape est le résumé du déploiement :
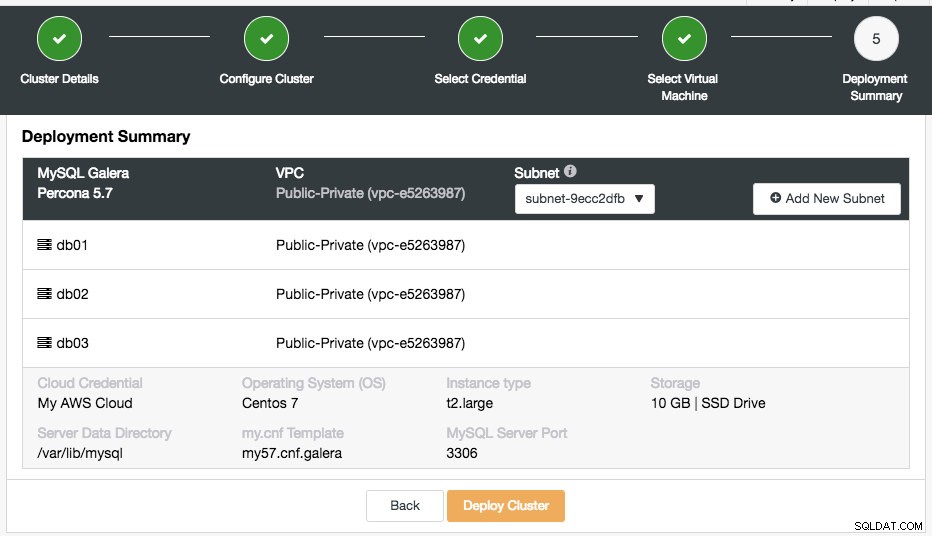
À cette étape, vous devez choisir le sous-réseau du réseau virtuel choisi sur lequel vous souhaitez que la base de données s'exécute. Notez que le sous-réseau choisi DOIT avoir une adresse IPv4 publique à attribution automatique activée. Vous pouvez également créer un nouveau sous-réseau sous ce VPC en cliquant sur le bouton "Ajouter un nouveau sous-réseau". Vérifiez si tout est correct et cliquez sur le bouton "Déployer le cluster" pour démarrer le déploiement.
Vous pouvez ensuite surveiller la progression en cliquant sur l'Activité -> Tâches -> Créer un cluster -> Détails complets de la tâche :
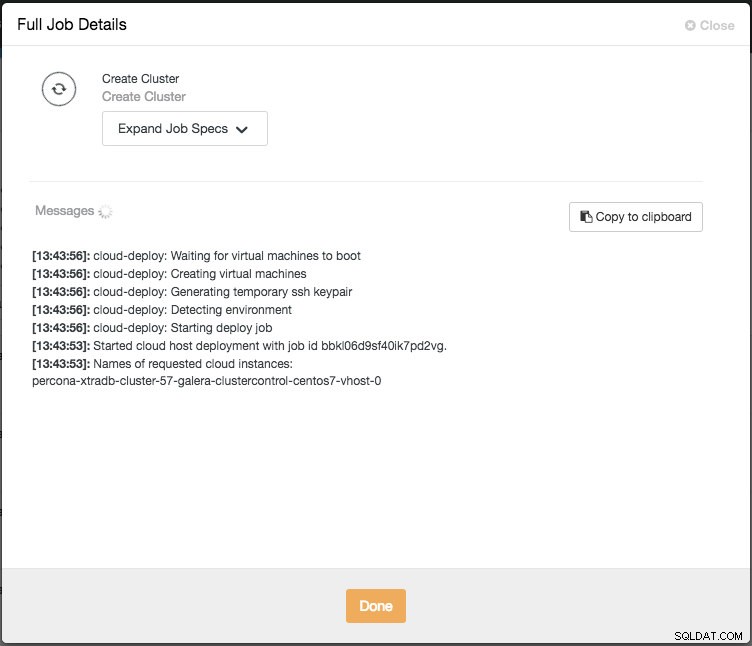
Selon les connexions, cela peut prendre 10 à 20 minutes. Une fois cela fait, vous verrez un nouveau cluster de base de données répertorié sous le tableau de bord ClusterControl. Pour le cluster de réplication en continu PostgreSQL, vous devrez peut-être connaître les adresses IP maître et esclave une fois le déploiement terminé. Allez simplement dans l'onglet Nœuds et vous verrez les adresses IP publiques et privées sur la liste des nœuds à gauche :
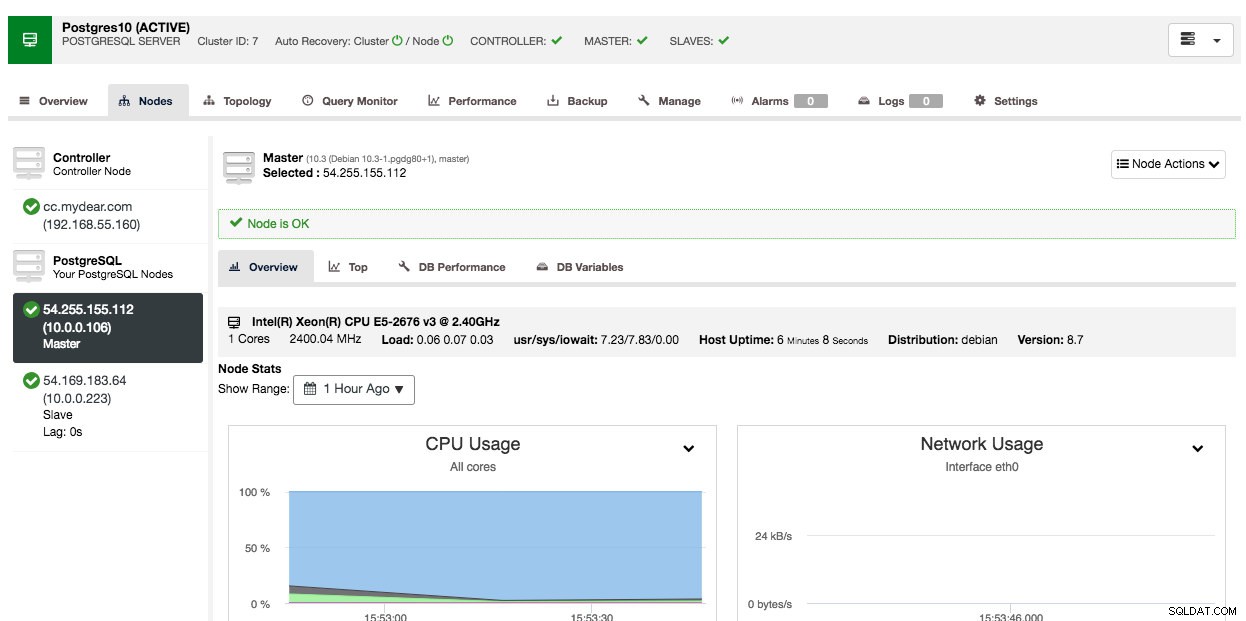
Votre cluster de base de données est maintenant déployé et en cours d'exécution sur AWS.
Pour le moment, la mise à l'échelle fonctionne de manière similaire à l'hôte standard, où vous devez créer une instance cloud manuellement au préalable et spécifier l'hôte sous ClusterControl -> choisissez le cluster -> Ajouter un nœud.
Sous le capot, le processus de déploiement effectue les opérations suivantes :
- Créer des instances cloud
- Configurer les groupes de sécurité et la mise en réseau
- Vérifiez la connectivité SSH de ClusterControl à toutes les instances créées
- Déployer la base de données sur chaque instance
- Configurer les liens de clustering ou de réplication
- Enregistrer le déploiement dans ClusterControl
Notez que cette fonctionnalité est toujours en version bêta. Néanmoins, vous pouvez utiliser cette fonctionnalité pour accélérer votre environnement de développement et de test en contrôlant et en gérant le cluster de bases de données dans différents fournisseurs de cloud à partir d'une seule interface utilisateur.
Sauvegarde de la base de données sur le cloud
Cette fonctionnalité existe depuis ClusterControl 1.5.0, et maintenant nous avons ajouté la prise en charge d'Azure Cloud Storage. Cela signifie que vous pouvez désormais charger et télécharger la sauvegarde créée sur les trois principaux fournisseurs de cloud (AWS, GCP et Azure). Le processus de téléchargement se produit juste après la création de la sauvegarde (si vous activez "Télécharger la sauvegarde sur le cloud") ou vous pouvez cliquer manuellement sur le bouton de l'icône du cloud de la liste de sauvegarde :
Vous pouvez ensuite télécharger et restaurer des sauvegardes à partir du cloud, au cas où vous perdriez votre stockage de sauvegarde local ou si vous deviez réduire l'utilisation de l'espace disque local pour vos sauvegardes.
Limites actuelles
Il existe certaines limitations connues pour la fonctionnalité de déploiement dans le cloud, comme indiqué ci-dessous :
- Il n'y a actuellement aucune "comptabilité" en place pour les instances cloud. Vous devrez supprimer manuellement les instances cloud si vous supprimez un cluster de bases de données.
- Vous ne pouvez pas ajouter ou supprimer un nœud automatiquement avec des instances cloud.
- Vous ne pouvez pas déployer un équilibreur de charge automatiquement avec une instance cloud.
Nous avons largement testé la fonctionnalité dans de nombreux environnements et configurations, mais il y a toujours des cas particuliers que nous aurions pu manquer. Pour plus d'informations, veuillez consulter le journal des modifications.
Bonne mise en cluster dans le cloud !



