Dans cet article, nous allons créer un grattoir pour un réel concert indépendant où le client souhaite qu'un programme Python récupère les données de Stack Overflow pour saisir de nouvelles questions (titre de la question et URL). Les données récupérées doivent ensuite être stockées dans MongoDB. Il convient de noter que Stack Overflow dispose d'une API, qui peut être utilisée pour accéder à l'exact mêmes données. Cependant, le client voulait un grattoir, donc un grattoir est ce qu'il a obtenu.
Bonus gratuit : Cliquez ici pour télécharger un squelette de projet Python + MongoDB avec le code source complet qui vous montre comment accéder à MongoDB à partir de Python.
Mises à jour :
- 03/01/2014 - Refactorisation de l'araignée. Merci, @kissgyorgy.
- 18/02/2015 – Ajout de la partie 2.
- 09/06/2015 - Mise à jour vers la dernière version de Scrapy et PyMongo - bravo !
Comme toujours, assurez-vous de consulter les conditions d'utilisation/service du site et de respecter le robots.txt fichier avant de commencer tout travail de grattage. Assurez-vous de respecter les pratiques de grattage éthiques en évitant d'inonder le site de nombreuses demandes sur une courte période. Traitez tout site que vous grattez comme s'il s'agissait du vôtre .
Installation
Nous avons besoin de la bibliothèque Scrapy (v1.0.3) avec PyMongo (v3.0.3) pour stocker les données dans MongoDB. Vous devez également installer MongoDB (non couvert).
Scrapy
Si vous utilisez OSX ou une version de Linux, installez Scrapy avec pip (avec votre virtualenv activé) :
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Si vous êtes sur une machine Windows, vous devrez installer manuellement un certain nombre de dépendances. Veuillez vous référer à la documentation officielle pour des instructions détaillées ainsi qu'à cette vidéo Youtube que j'ai créée.
Une fois Scrapy configuré, vérifiez votre installation en exécutant cette commande dans le shell Python :
>>>>>> import scrapy
>>>
Si vous n'obtenez pas d'erreur, vous êtes prêt à partir !
PyMongo
Ensuite, installez PyMongo avec pip :
$ pip install pymongo
$ pip freeze > requirements.txt
Nous pouvons maintenant commencer à créer le robot d'exploration.
Projet Scrapy
Commençons un nouveau projet Scrapy :
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Cela crée un certain nombre de fichiers et de dossiers qui incluent un passe-partout de base pour vous permettre de démarrer rapidement :
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Spécifier les données
Le items.py est utilisé pour définir des "conteneurs" de stockage pour les données que nous prévoyons de récupérer.
Le StackItem() la classe hérite de Item (docs), qui contient essentiellement un certain nombre d'objets prédéfinis que Scrapy a déjà créés pour nous :
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Ajoutons quelques éléments que nous voulons réellement collecter. Pour chaque question, le client a besoin du titre et de l'URL. Alors, mettez à jour items.py comme ça :
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Créer l'araignée
Créez un fichier appelé stack_spider.py dans le répertoire "spiders". C'est là que la magie se produit - par exemple, où nous dirons à Scrapy comment trouver le exact données que nous recherchons. Comme vous pouvez l'imaginer, c'est spécifique à chaque page Web individuelle que vous souhaitez récupérer.
Commencez par définir une classe qui hérite du Spider de Scrapy puis en ajoutant des attributs si nécessaire :
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
Les premières variables sont explicites (documents) :
namedéfinit le nom de l'araignée.allowed_domainscontient les URL de base des domaines autorisés à explorer par l'araignée.start_urlsest une liste d'URL à partir desquelles l'araignée doit commencer à explorer. Toutes les URL suivantes commenceront à partir des données que l'araignée télécharge à partir des URL dansstart_urls.
Sélecteur XPath
Ensuite, Scrapy utilise des sélecteurs XPath pour extraire des données d'un site Web. En d'autres termes, nous pouvons sélectionner certaines parties des données HTML en fonction d'un XPath donné. Comme indiqué dans la documentation de Scrapy, "XPath est un langage de sélection de nœuds dans des documents XML, qui peut également être utilisé avec HTML."
Vous pouvez facilement trouver un XPath spécifique à l'aide des outils de développement de Chrome. Inspectez simplement un élément HTML spécifique, copiez le XPath, puis modifiez (si nécessaire) :
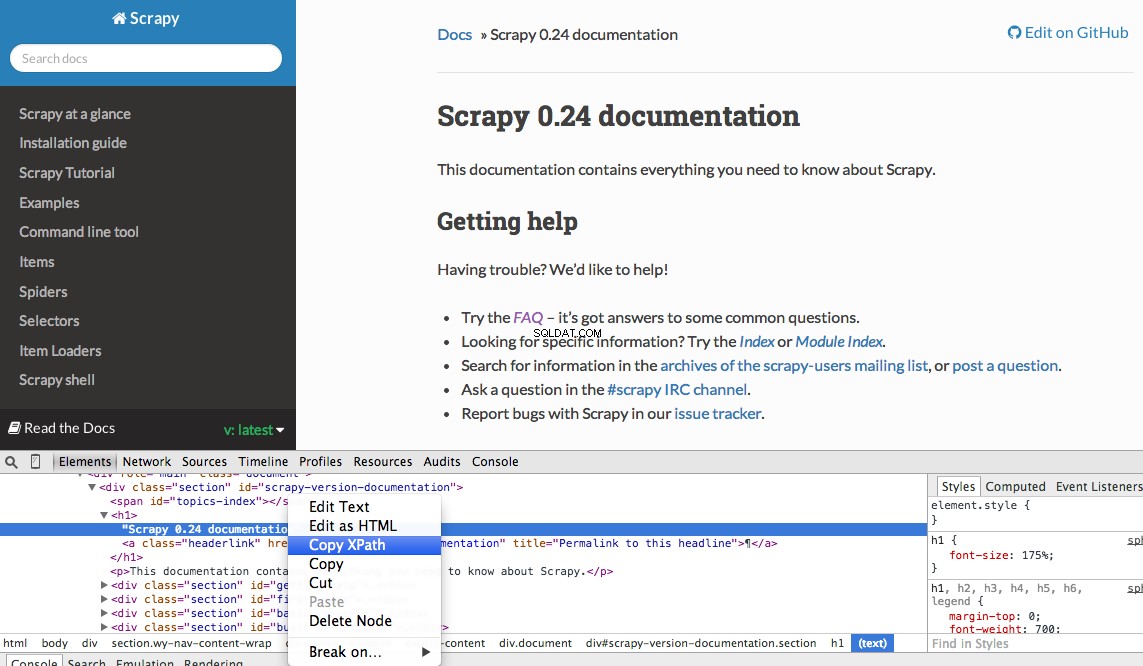
Les outils de développement vous permettent également de tester les sélecteurs XPath dans la console JavaScript en utilisant $x - c'est-à-dire $x("//img") :
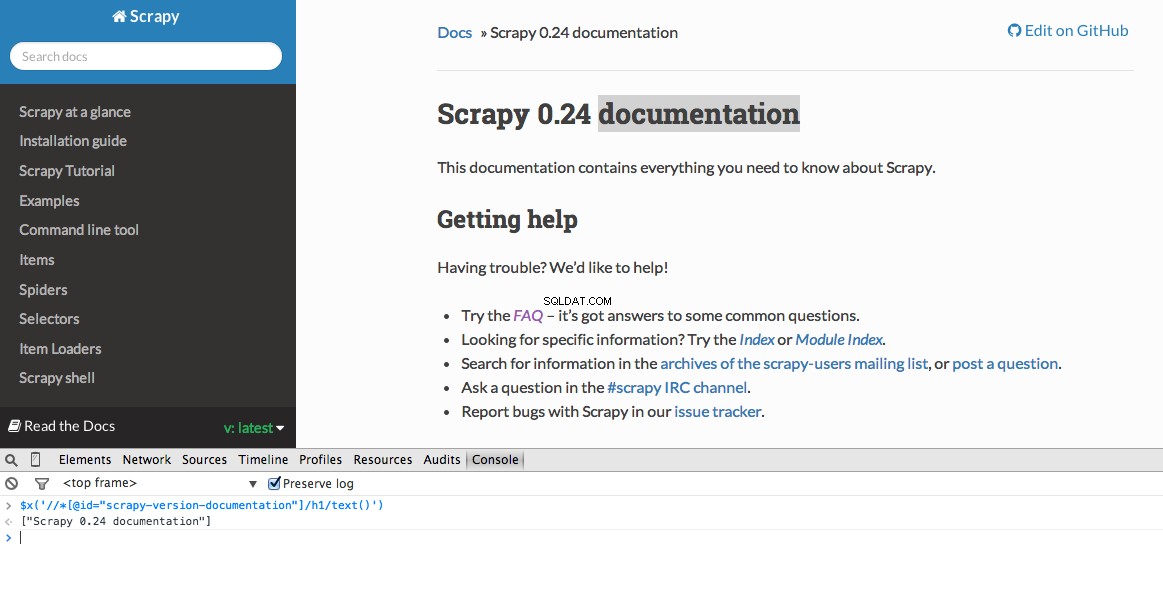
Encore une fois, nous indiquons essentiellement à Scrapy où commencer à rechercher des informations basées sur un XPath défini. Naviguons vers le site Stack Overflow dans Chrome et trouvons les sélecteurs XPath.
Faites un clic droit sur la première question et sélectionnez "Inspecter l'élément":
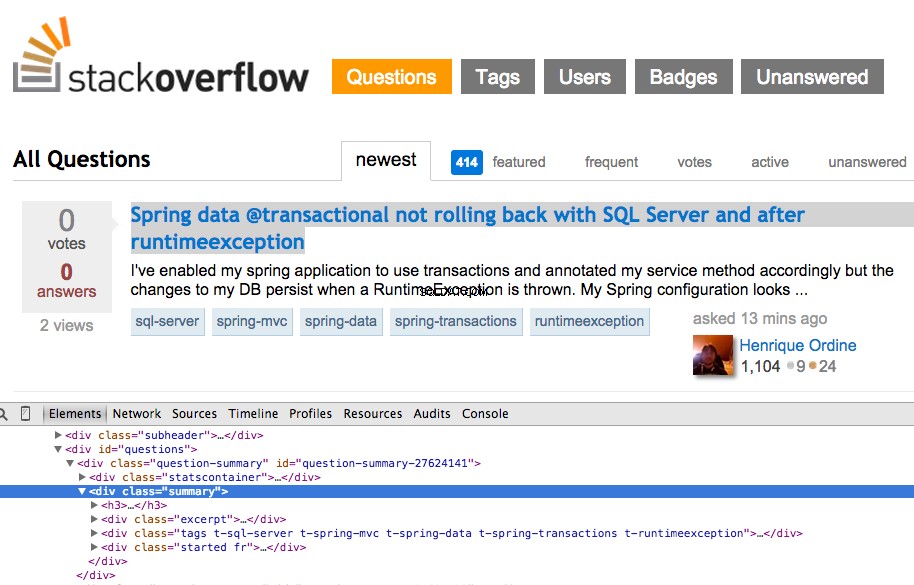
Saisissez maintenant le XPath pour le <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] , puis testez-le dans la console JavaScript :
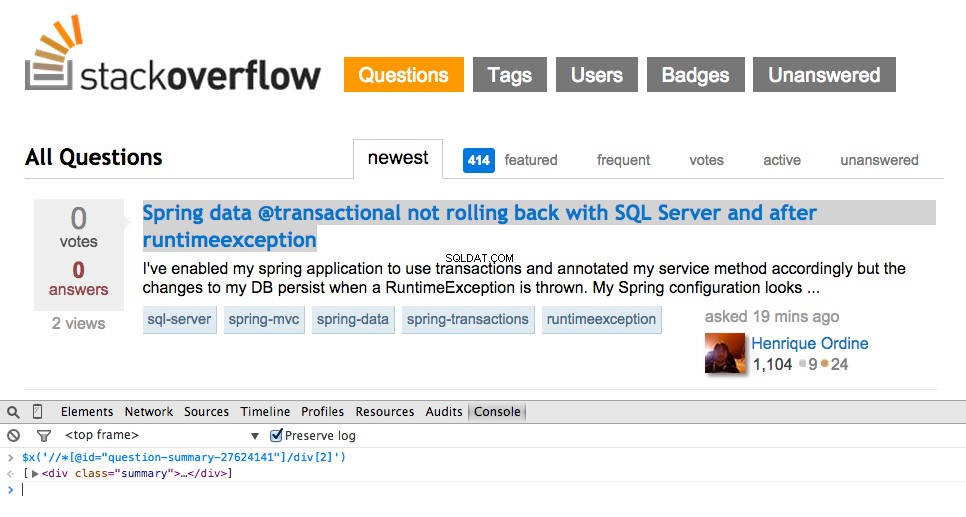
Comme vous pouvez le constater, il sélectionne simplement celui-là un question. Nous devons donc modifier le XPath pour saisir tout des questions. Des idées? C'est simple ://div[@class="summary"]/h3 . Qu'est-ce que ça veut dire? Essentiellement, ce XPath indique :Prenez tout <h3> les éléments enfants d'un <div> qui a une classe summary . Testez ce XPath dans la console JavaScript.
Remarquez que nous n'utilisons pas la sortie XPath réelle des outils de développement Chrome. Dans la plupart des cas, la sortie n'est qu'un aparté utile, qui vous oriente généralement dans la bonne direction pour trouver le XPath fonctionnel.
Maintenant, mettons à jour le stack_spider.py script :
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Extraire les données
Nous devons encore analyser et extraire les données que nous voulons, qui relèvent de <div class="summary"><h3> . Encore une fois, mettez à jour stack_spider.py comme ça :
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
En plus de la trace de la pile Scrapy, vous devriez voir 50 titres de questions et URL générés. Vous pouvez afficher la sortie dans un fichier JSON avec cette petite commande :
$ scrapy crawl stack -o items.json -t json
Nous avons maintenant implémenté notre Spider sur la base des données que nous recherchons. Nous devons maintenant stocker les données récupérées dans MongoDB.
Stocker les données dans MongoDB
Chaque fois qu'un article est retourné, nous souhaitons valider les données, puis l'ajouter à une collection Mongo.
La première étape consiste à créer la base de données que nous prévoyons d'utiliser pour enregistrer toutes nos données explorées. Ouvrez settings.py et spécifiez le pipeline et ajoutez les paramètres de la base de données :
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Gestion des pipelines
Nous avons configuré notre araignée pour explorer et analyser le HTML, et nous avons configuré nos paramètres de base de données. Nous devons maintenant connecter les deux ensemble via un pipeline dans pipelines.py .
Se connecter à la base de données
Tout d'abord, définissons une méthode pour se connecter réellement à la base de données :
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Ici, nous créons une classe, MongoDBPipeline() , et nous avons une fonction constructeur pour initialiser la classe en définissant les paramètres Mongo puis en nous connectant à la base de données.
Traiter les données
Ensuite, nous devons définir une méthode pour traiter les données analysées :
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Nous établissons une connexion à la base de données, décompressons les données, puis les enregistrons dans la base de données. Nous pouvons maintenant tester à nouveau !
Tester
Encore une fois, exécutez la commande suivante dans le répertoire "stack" :
$ scrapy crawl stack
REMARQUE :Assurez-vous d'avoir le démon Mongo -
mongod- s'exécutant dans une autre fenêtre de terminal.
Hourra ! Nous avons réussi à stocker nos données explorées dans la base de données :
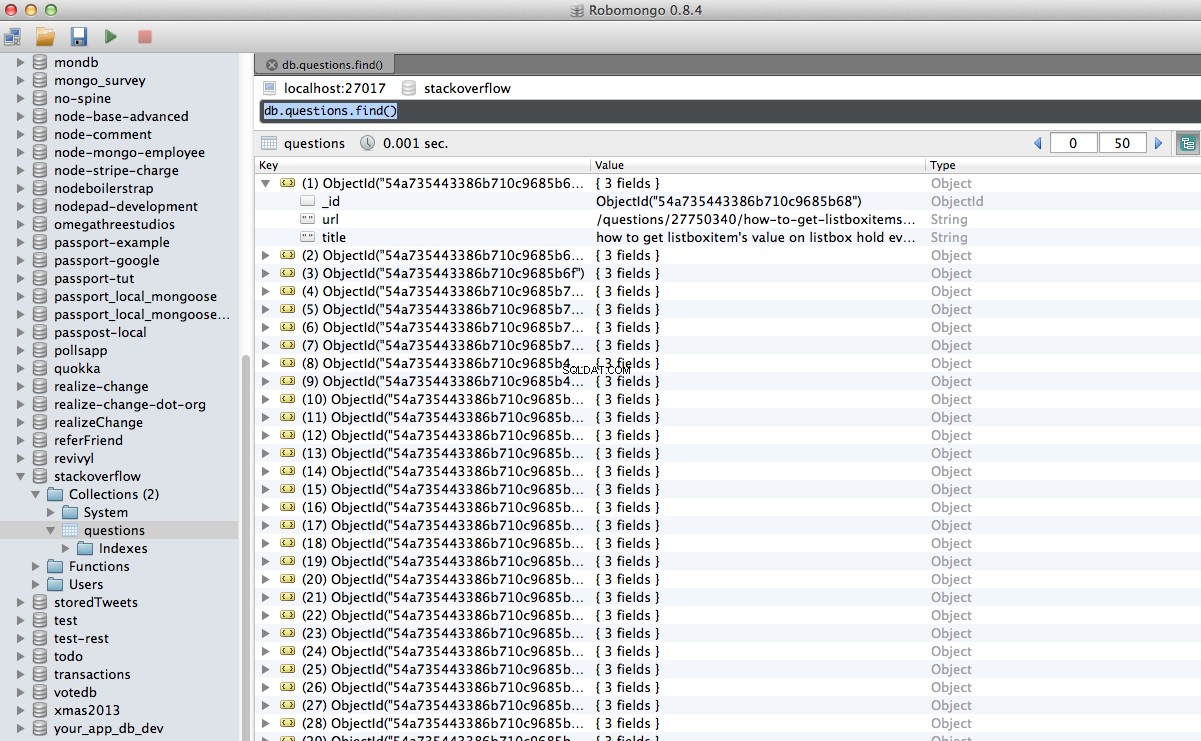
Conclusion
Ceci est un exemple assez simple d'utilisation de Scrapy pour explorer et gratter une page Web. Le projet indépendant actuel nécessitait que le script suive les liens de pagination et récupère chaque page à l'aide de CrawlSpider (docs), qui est super facile à mettre en œuvre. Essayez de l'implémenter par vous-même et laissez un commentaire ci-dessous avec le lien vers le référentiel Github pour une révision rapide du code.
Besoin d'aide? Commencez par ce script, qui est presque terminé. Consultez ensuite la partie 2 pour la solution complète !
Bonus gratuit : Cliquez ici pour télécharger un squelette de projet Python + MongoDB avec le code source complet qui vous montre comment accéder à MongoDB à partir de Python.
Vous pouvez télécharger l'intégralité du code source à partir du référentiel Github. Commentez ci-dessous avec des questions. Merci d'avoir lu !



