Vous vous interrogez sur Comment puis-je calculer quelles sont les villes les plus proches ? Par exemple. Si je regardais la ville 1 (Paris), les résultats devraient être :Londres (2), New York (3) et sur la base de votre ensemble de données fourni, il n'y a qu'une seule chose à relier, à savoir les balises communes entre les villes, de sorte que les villes qui partagent les balises communes seraient les plus proches ci-dessous est la sous-requête qui trouve les villes (autre que celle qui est fournie à trouver ses villes les plus proches) qui partage les balises communes
SELECT * FROM `cities` WHERE id IN (
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Travailler
Je suppose que vous saisirez l'un des identifiants ou noms de ville pour trouver le plus proche dans mon cas "Paris" a l'identifiant
SELECT tag_id FROM `cities_tags` WHERE city_id=1
Il trouvera tous les tags id dont paris dispose alors
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Il récupérera toutes les villes sauf paris qui ont les mêmes balises que paris a aussi
Voici votre Violon
En lisant sur la similitude/indice Jaccard trouvé des choses à comprendre sur ce que sont réellement les termes prenons cet exemple, nous avons deux ensembles A et B
Avancez maintenant vers votre scénario
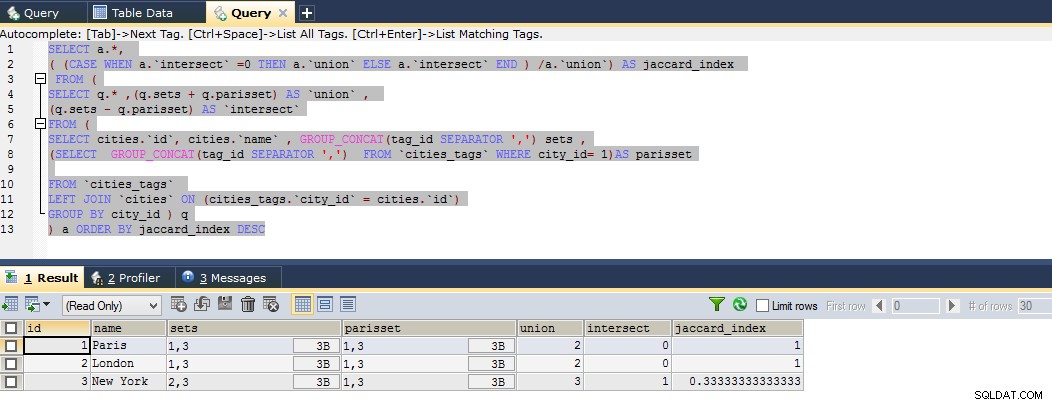
Voici la requête jusqu'à présent qui calcule l'index jaccard parfait, vous pouvez voir l'exemple de violon ci-dessous
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`)
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Dans la requête ci-dessus, j'ai dérivé le jeu de résultats sur deux sous-sélections afin d'obtenir mes alias calculés personnalisés
Vous pouvez ajouter le filtre dans la requête ci-dessus pour ne pas calculer la similarité avec elle-même
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`) WHERE cities.`id` !=1
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Ainsi, le résultat montre que Paris est étroitement liée à Londres, puis à New York