Vous pouvez importer des données d'un fichier CSV (Comma Separated Values) dans une base de données Neo4j. Pour cela, utilisez le LOAD CSV clause.
La possibilité de charger des fichiers CSV dans Neo4j facilite l'importation de données à partir d'un autre modèle de base de données (par exemple, une base de données relationnelle).
Avec Neo4j, vous pouvez charger des fichiers CSV à partir d'une URL locale ou distante.
Pour accéder à un fichier stocké localement (sur le serveur de la base de données), utilisez un file:/// URL. Sinon, vous pouvez importer des fichiers distants à l'aide de l'un des protocoles HTTPS, HTTP et FTP.
Charger un fichier CSV
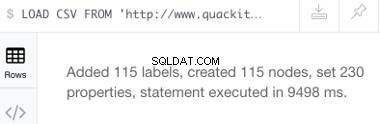
Chargeons un fichier CSV appelé genres.csv utilisant le protocole HTTP. Ce n'est pas un gros fichier — il contient une liste de 115 genres musicaux, il créera donc 115 nœuds (et 230 propriétés).
Ce fichier est stocké sur Quackit.com, vous pouvez donc exécuter ce code depuis votre navigateur Neo4j et il devrait être importé directement dans votre base de données (en supposant que vous êtes connecté à Internet).
Vous pouvez également télécharger le fichier ici :genres.csv
LOAD CSV FROM 'https://www.quackit.com/neo4j/tutorial/genres.csv' AS line
CREATE (:Genre { GenreId: line[0], Name: line[1]})
Vous pouvez omettre certains champs du fichier CSV si nécessaire. Par exemple, si vous ne souhaitez pas que le premier champ soit importé dans la base de données, vous pouvez simplement omettre GenreId: line[0], à partir du code ci-dessus.
L'exécution de l'instruction ci-dessus devrait produire le message de réussite suivant :
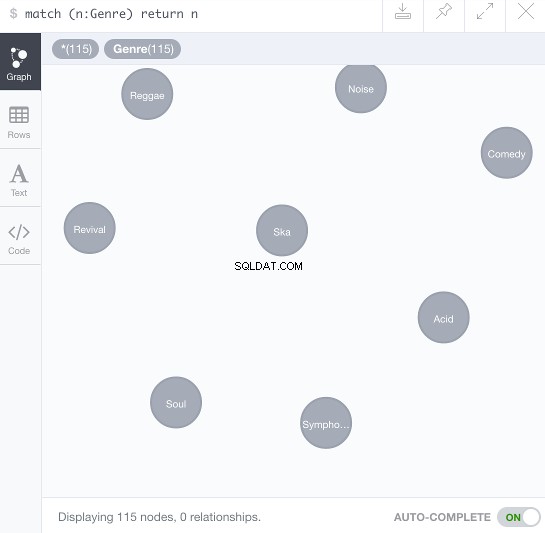
Vous pouvez poursuivre avec une requête pour voir les nœuds nouvellement créés :
MATCH (n:Genre) RETURN n
Ce qui devrait entraîner la dispersion des nœuds autour du cadre de visualisation des données :
Importer un fichier CSV contenant des en-têtes
Le fichier CSV précédent ne contenait aucun en-tête. Si le fichier CSV contient des en-têtes, vous pouvez utiliser WITH HEADERS .
L'utilisation de cette méthode vous permet également de référencer chaque champ par leur nom de colonne/en-tête.
Nous avons un autre fichier CSV, cette fois avec des en-têtes. Ce fichier contient une liste de pistes d'album.
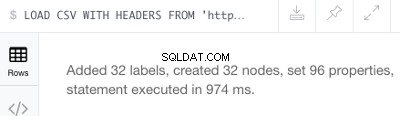
Encore une fois, celui-ci n'est pas un fichier volumineux :il contient une liste de 32 pistes, il créera donc 32 nœuds (et 96 propriétés).
Ce fichier est également stocké sur Quackit.com, vous pouvez donc exécuter ce code depuis votre navigateur Neo4j et il devrait être importé directement dans votre base de données (en supposant que vous êtes connecté à Internet).
Vous pouvez également télécharger le fichier ici :pistes.csv
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) Cela devrait produire le message de réussite suivant :
Suivi d'une requête pour afficher les nœuds nouvellement créés :
MATCH (n:Track) RETURN n
Ce qui devrait entraîner la dispersion des nouveaux nœuds autour du cadre de visualisation des données.
Cliquez sur les lignes icône pour voir chaque nœud et ses trois propriétés :
Délimiteur de champ personnalisé
Vous pouvez spécifier un délimiteur de champ personnalisé si nécessaire. Par exemple, vous pouvez spécifier un point-virgule au lieu d'une virgule si c'est ainsi que le fichier CSV est formaté.
Pour cela, ajoutez simplement le FIELDTERMINATOR clause à la déclaration. Comme ceci :
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line FIELDTERMINATOR ';'
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) Importation de fichiers volumineux
Si vous allez importer un fichier avec beaucoup de données, le PERODIC COMMIT clause peut être pratique.
Utilisation de PERIODIC COMMIT ordonne à Neo4j de valider les données après un certain nombre de lignes. Cela réduit la surcharge de mémoire de l'état de la transaction.
La valeur par défaut est de 1000 lignes, donc les données seront validées toutes les mille lignes.
Pour utiliser PERIODIC COMMIT insérez simplement USING PERIODIC COMMIT au début de l'instruction (avant LOAD CSV )
Voici un exemple :
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) Définir le taux de commits périodiques
Vous pouvez également modifier le taux de 1000 lignes par défaut à un autre nombre. Ajoutez simplement le nombre après USING PERIODIC COMMIT :
Comme ceci :
USING PERIODIC COMMIT 800
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) Format CSV/Exigences
Voici quelques informations sur la façon dont le fichier CSV doit être formaté lors de l'utilisation de LOAD CSV :
- Le codage des caractères doit être UTF-8.
- La fin de ligne dépend du système, par exemple,
\nsous Unix ou\r\nsous Windows. - Le terminateur doit être une virgule
,sauf indication contraire en utilisant leFIELDTERMINATORoption. - Le caractère pour la citation de chaîne est le guillemet double
"(ceux-ci sont supprimés lorsque les données sont lues). - Tous les caractères qui doivent être échappés peuvent être échappés avec la barre oblique inverse
\personnage. LOAD CSVprend en charge les ressources compressées avec gzip, Deflate, ainsi que les archives ZIP.