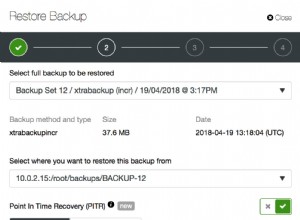
La sous-requête corrélée renvoie le nombre de personnes ayant le même pays et un identifiant supérieur. Donc, si vous comparez cela avec < 2 vous ne sélectionnerez que les deux identifiants les plus élevés pour chaque pays. Vous pouvez vous en faire une meilleure idée en examinant les résultats de la sélection de la sous-requête au lieu de l'utiliser comme contrainte :
SELECT co.id, co.person, co.country,
(
SELECT COUNT(*)
FROM person ci
WHERE co.country = ci.country -- controlling grouping column
AND co.id < ci.id -- controlling min or max
) AS higher_ids
FROM person co
https://dbfiddle.uk/?rdbms=mysql_8.0&fiddle=9c3cfe469dd299b3160d09e97e73>
Notez qu'à moins qu'il n'y ait des optimisations qui recherchent spécifiquement ce modèle, ce dont je doute fortement, cette requête sera O(N^2).