Quelqu'un a accidentellement supprimé une partie de la base de données. Quelqu'un a oublié d'inclure une clause WHERE dans une requête DELETE ou a supprimé la mauvaise table. Des choses comme ça peuvent arriver et arriveront, c'est inévitable et humain. Mais l'impact peut être désastreux. Que pouvez-vous faire pour vous prémunir contre de telles situations et comment pouvez-vous récupérer vos données ? Dans cet article de blog, nous couvrirons certains des cas les plus typiques de perte de données et comment vous pouvez vous préparer pour vous en remettre.
Préparatifs
Il y a des choses que vous devez faire pour assurer une récupération en douceur. Passons par eux. Veuillez garder à l'esprit qu'il ne s'agit pas de "choisir une situation" - idéalement, vous mettrez en œuvre toutes les mesures dont nous allons discuter ci-dessous.
Sauvegarde
Vous devez avoir une sauvegarde, il n'y a pas moyen de s'en éloigner. Vous devriez faire tester vos fichiers de sauvegarde - à moins que vous ne testiez vos sauvegardes, vous ne pouvez pas être sûr qu'elles sont bonnes et si vous pourrez un jour les restaurer. Pour la reprise après sinistre, vous devez conserver une copie de votre sauvegarde quelque part en dehors de votre centre de données - juste au cas où l'ensemble du centre de données deviendrait indisponible. Pour accélérer la récupération, il est très utile de conserver une copie de la sauvegarde également sur les nœuds de la base de données. Si votre ensemble de données est volumineux, sa copie sur le réseau à partir d'un serveur de sauvegarde vers le nœud de base de données que vous souhaitez restaurer peut prendre un temps considérable. Conserver la dernière sauvegarde localement peut améliorer considérablement les temps de récupération.
Sauvegarde logique
Votre première sauvegarde sera très probablement une sauvegarde physique. Pour MySQL ou MariaDB, ce sera quelque chose comme xtrabackup ou une sorte d'instantané du système de fichiers. Ces sauvegardes sont idéales pour restaurer un ensemble de données complet ou pour provisionner de nouveaux nœuds. Cependant, en cas de suppression d'un sous-ensemble de données, elles souffrent d'un surcoût important. Tout d'abord, vous ne pouvez pas restaurer toutes les données, sinon vous écraserez toutes les modifications apportées après la création de la sauvegarde. Ce que vous recherchez, c'est la possibilité de restaurer uniquement un sous-ensemble de données, uniquement les lignes supprimées accidentellement. Pour ce faire avec une sauvegarde physique, vous devez la restaurer sur un hôte séparé, localiser les lignes supprimées, les vider, puis les restaurer sur le cluster de production. Copier et restaurer des centaines de gigaoctets de données juste pour récupérer une poignée de lignes est quelque chose que nous appellerions certainement une surcharge importante. Pour l'éviter, vous pouvez utiliser des sauvegardes logiques - au lieu de stocker des données physiques, ces sauvegardes stockent les données au format texte. Cela facilite la localisation des données exactes qui ont été supprimées, qui peuvent ensuite être restaurées directement sur le cluster de production. Pour le rendre encore plus facile, vous pouvez également diviser cette sauvegarde logique en plusieurs parties et sauvegarder chaque table dans un fichier séparé. Si votre ensemble de données est volumineux, il sera judicieux de diviser autant que possible un énorme fichier texte. Cela rendra la sauvegarde incohérente, mais dans la majorité des cas, ce n'est pas un problème - si vous devez restaurer l'ensemble de données dans un état cohérent, vous utiliserez une sauvegarde physique, qui est beaucoup plus rapide à cet égard. Si vous devez restaurer uniquement un sous-ensemble de données, les exigences de cohérence sont moins strictes.
Récupération ponctuelle
La sauvegarde n'est qu'un début - vous pourrez restaurer vos données au point où la sauvegarde a été effectuée mais, très probablement, les données ont été supprimées après ce moment. En restaurant simplement les données manquantes à partir de la dernière sauvegarde, vous risquez de perdre toutes les données modifiées après la sauvegarde. Pour éviter cela, vous devez implémenter la récupération ponctuelle. Pour MySQL, cela signifie essentiellement que vous devrez utiliser des journaux binaires pour rejouer toutes les modifications qui se sont produites entre le moment de la sauvegarde et l'événement de perte de données. La capture d'écran ci-dessous montre comment ClusterControl peut vous aider.
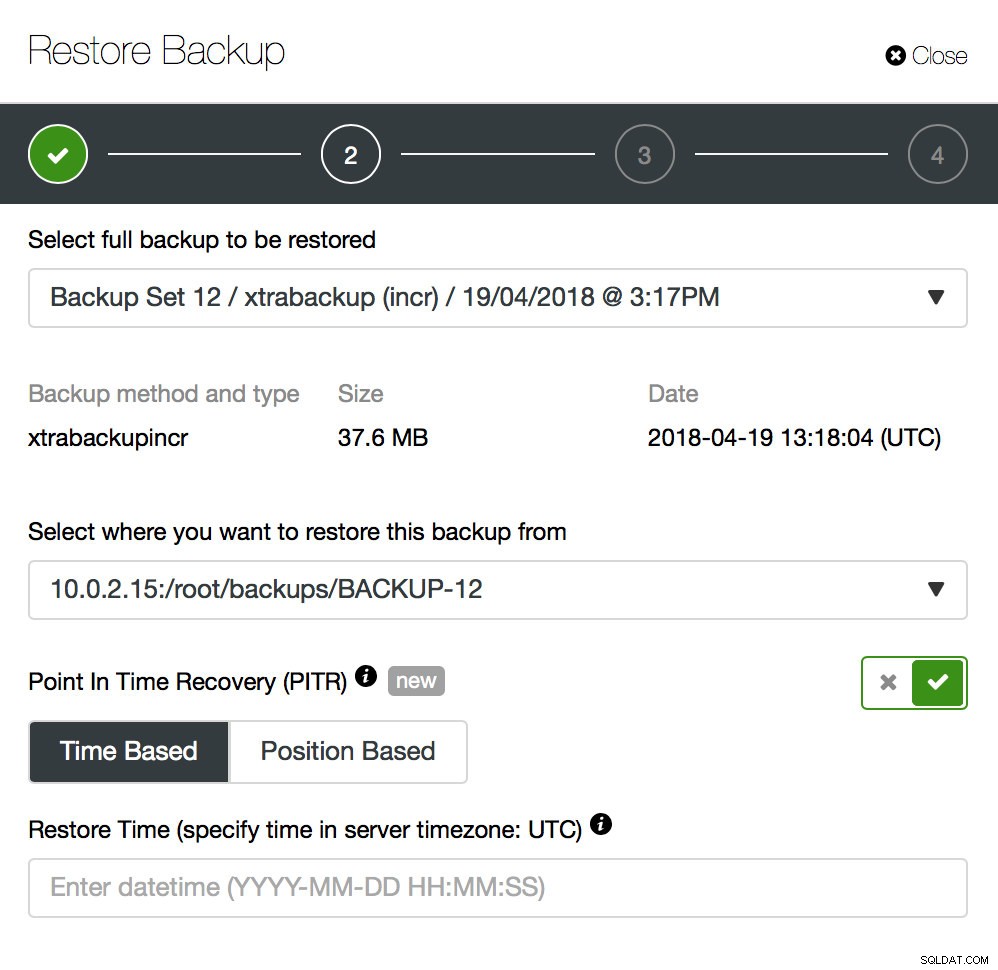
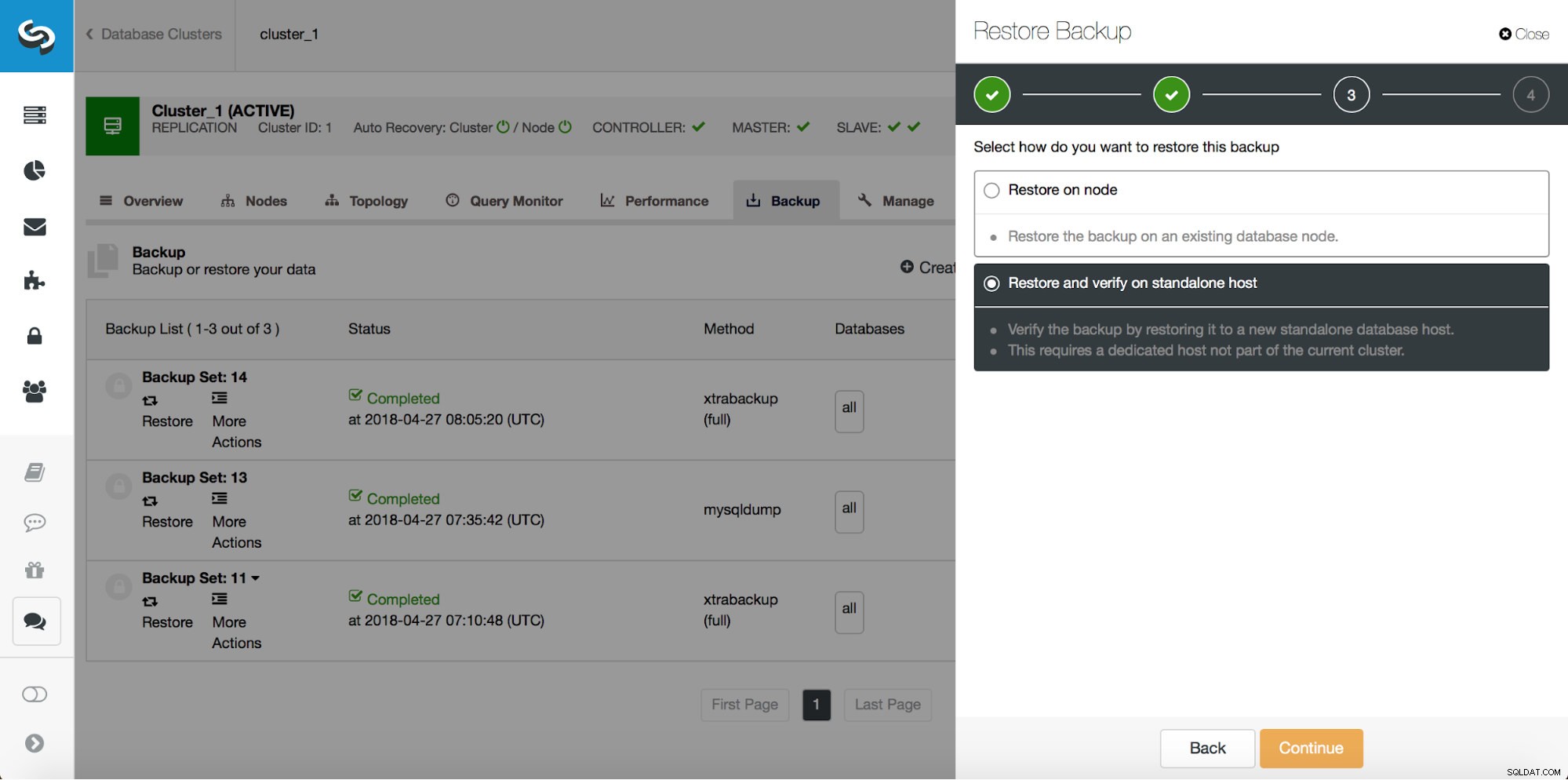
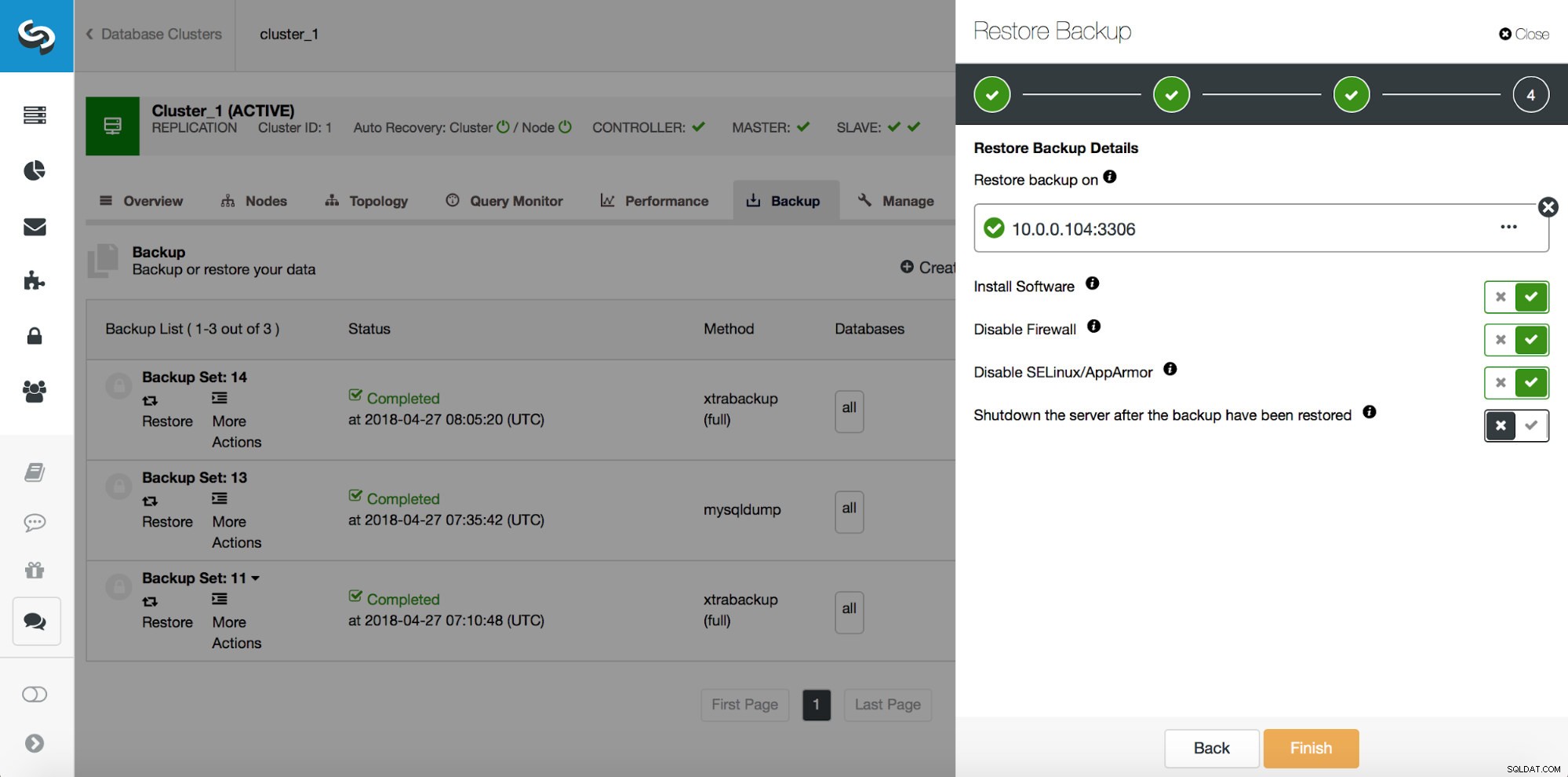
Ce que vous devrez faire est de restaurer cette sauvegarde jusqu'au moment juste avant la perte de données. Vous devrez le restaurer sur un hôte séparé afin de ne pas apporter de modifications sur le cluster de production. Une fois la sauvegarde restaurée, vous pouvez vous connecter à cet hôte, rechercher les données manquantes, les vider et les restaurer sur le cluster de production.
Esclave retardé
Toutes les méthodes dont nous avons discuté ci-dessus ont un point commun :la restauration des données prend du temps. Cela peut prendre plus de temps si vous restaurez toutes les données et essayez ensuite de ne vider que la partie intéressante. Cela peut prendre moins de temps si vous disposez d'une sauvegarde logique et que vous pouvez rapidement accéder aux données que vous souhaitez restaurer, mais ce n'est en aucun cas une tâche rapide. Vous devez toujours trouver quelques lignes dans un gros fichier texte. Plus il est volumineux, plus la tâche devient compliquée - parfois, la taille même du fichier ralentit toutes les actions. Une méthode pour éviter ces problèmes est d'avoir un esclave retardé. Les esclaves essaient généralement de rester à jour avec le maître, mais il est également possible de les configurer pour qu'ils se tiennent à distance de leur maître. Dans la capture d'écran ci-dessous, vous pouvez voir comment utiliser ClusterControl pour déployer un tel esclave :
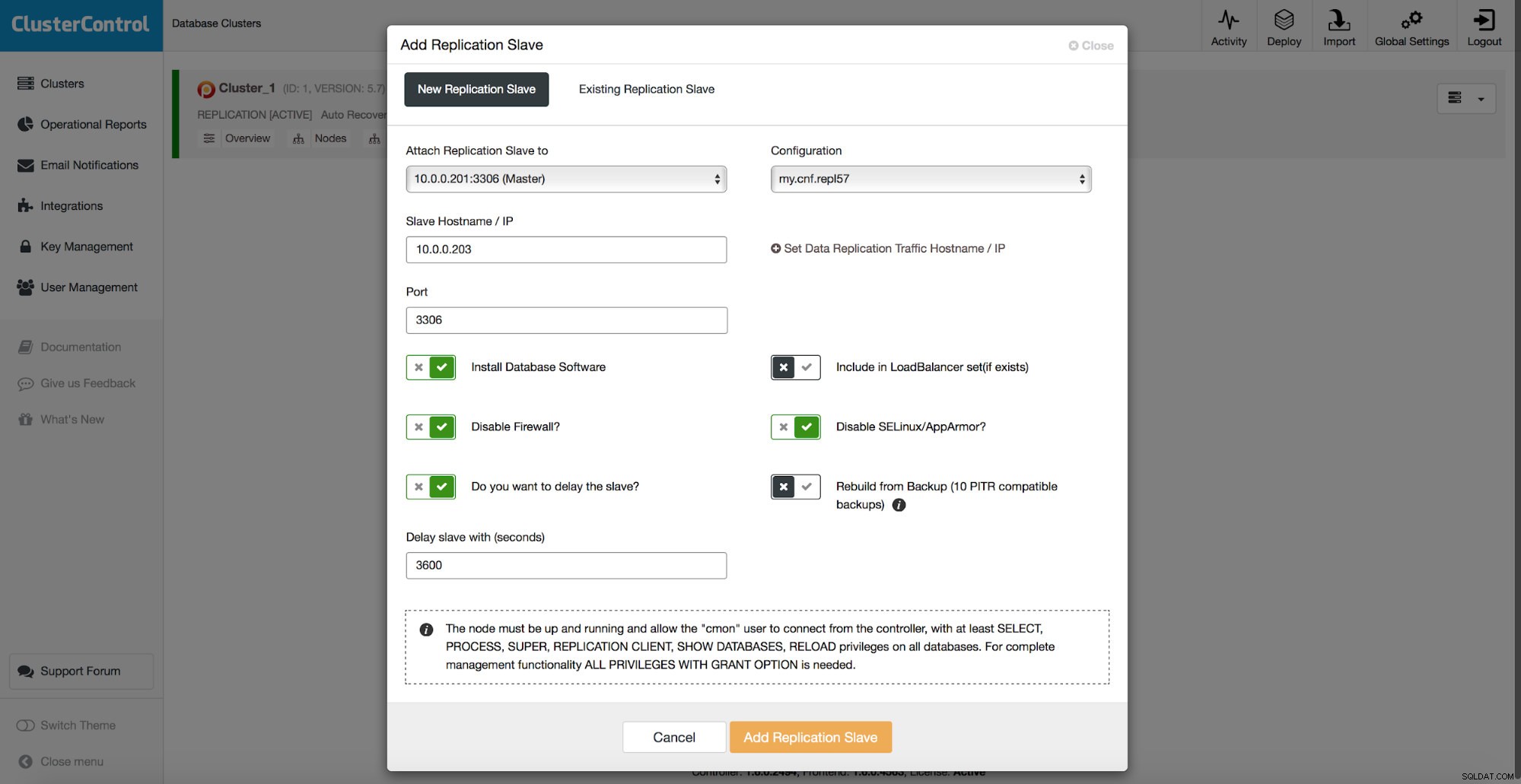
En bref, nous avons ici une option pour ajouter un esclave de réplication à la configuration de la base de données et le configurer pour qu'il soit retardé. Dans la capture d'écran ci-dessus, l'esclave sera retardé de 3600 secondes, soit une heure. Cela vous permet d'utiliser cet esclave pour récupérer les données supprimées jusqu'à une heure après la suppression des données. Vous n'aurez pas à restaurer de sauvegarde, il suffira de lancer mysqldump ou SELECT ... INTO OUTFILE pour les données manquantes et vous obtiendrez les données à restaurer sur votre cluster de production.
Restauration des données
Dans cette section, nous allons passer en revue quelques exemples de suppression accidentelle de données et comment vous pouvez vous en remettre. Nous allons parcourir la récupération après une perte de données complète, nous montrerons également comment récupérer après une perte de données partielle lors de l'utilisation de sauvegardes physiques et logiques. Nous allons enfin vous montrer comment restaurer des lignes supprimées accidentellement si vous avez un esclave retardé dans votre configuration.
Perte de données complète
"rm -rf" accidentel ou "DROP SCHEMA myonlyschema ;" a été exécuté et vous vous êtes retrouvé sans données du tout. S'il vous arrivait de supprimer également des fichiers autres que ceux du répertoire de données MySQL, vous devrez peut-être reprovisionner l'hôte. Pour simplifier les choses, nous supposerons que seul MySQL a été impacté. Considérons deux cas, avec un esclave retardé et sans.
Aucun esclave retardé
Dans ce cas, la seule chose que nous pouvons faire est de restaurer la dernière sauvegarde physique. Comme toutes nos données ont été supprimées, nous n'avons pas à nous inquiéter de l'activité qui s'est produite après la perte de données, car sans données, il n'y a pas d'activité. Nous devrions nous inquiéter de l'activité qui s'est produite après la sauvegarde. Cela signifie que nous devons effectuer une restauration ponctuelle. Bien sûr, cela prendra plus de temps que de simplement restaurer les données à partir de la sauvegarde. Si la mise en place rapide de votre base de données est plus cruciale que la restauration de toutes les données, vous pouvez également restaurer une sauvegarde et vous en sortir.
Tout d'abord, si vous avez toujours accès aux journaux binaires sur le serveur que vous souhaitez restaurer, vous pouvez les utiliser pour PITR. Tout d'abord, nous voulons convertir la partie pertinente des journaux binaires en un fichier texte pour une enquête plus approfondie. Nous savons que la perte de données s'est produite après 13:00:00. Tout d'abord, vérifions sur quel fichier binlog nous devons enquêter :
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
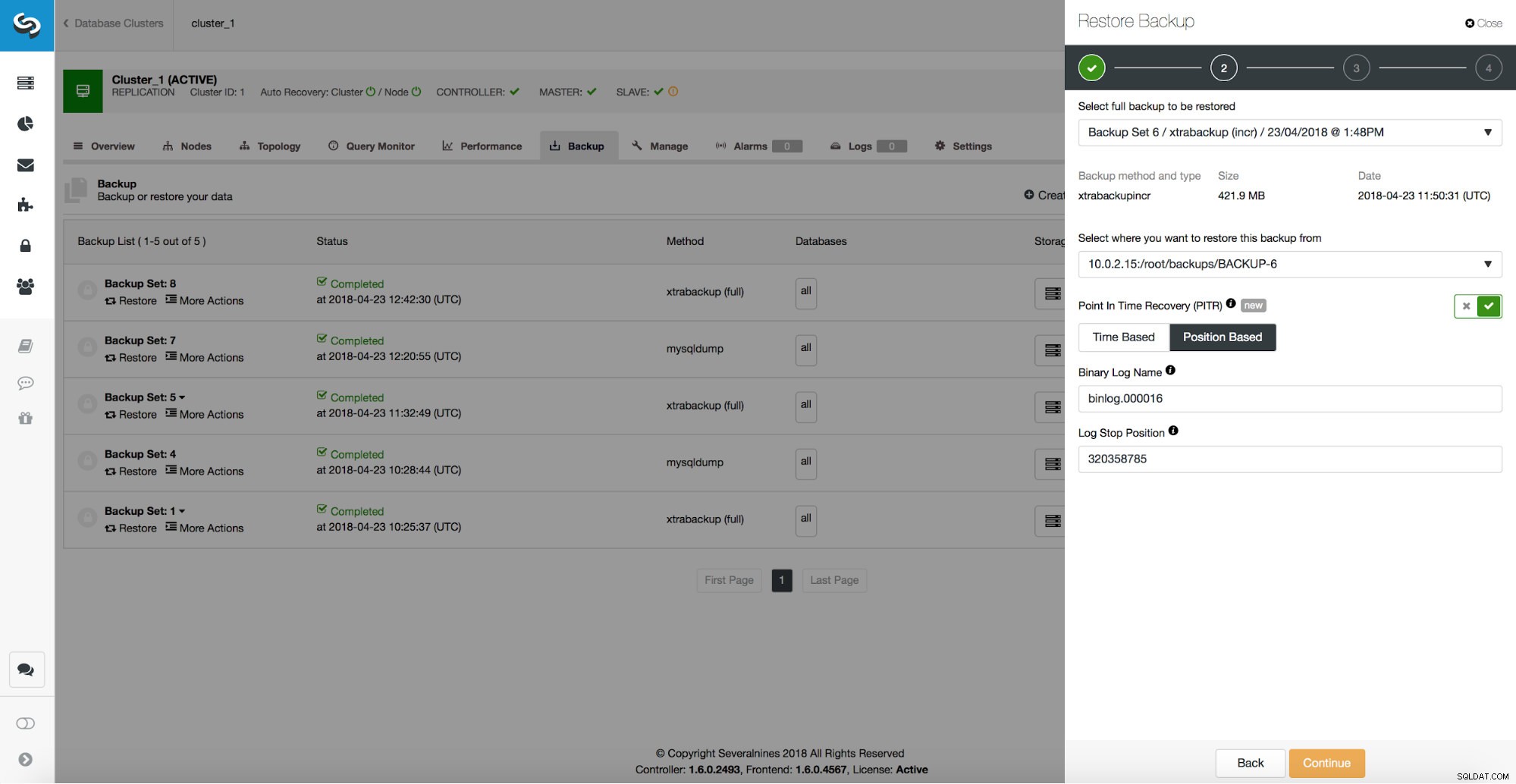
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Comme on peut le voir, nous nous intéressons au dernier fichier binlog.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outUne fois cela fait, regardons le contenu de ce fichier. Nous allons rechercher « drop schema » dans vim. Voici une partie pertinente du fichier :
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Comme nous pouvons le voir, nous voulons restaurer jusqu'à la position 320358785. Nous pouvons transmettre ces données à l'interface utilisateur de ClusterControl :
Esclave retardé
Si nous avons un esclave retardé et que cet hôte est suffisant pour gérer tout le trafic, nous pouvons l'utiliser et le promouvoir en tant que maître. Cependant, nous devons d'abord nous assurer qu'il a rattrapé l'ancien maître jusqu'au point de la perte de données. Nous utiliserons ici quelques CLI pour y arriver. Tout d'abord, nous devons déterminer sur quelle position la perte de données s'est produite. Ensuite, nous arrêterons l'esclave et le laisserons fonctionner jusqu'à l'événement de perte de données. Nous avons montré comment obtenir la position correcte dans la section précédente - en examinant les logs binaires. Nous pouvons soit utiliser cette position (binlog.000016, position 320358785) ou, si nous utilisons un esclave multithread, nous devons utiliser le GTID de l'événement de perte de données (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) et rejouer les requêtes jusqu'à ce GTID.
Tout d'abord, arrêtons l'esclave et désactivons le délai :
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Ensuite, nous pouvons le démarrer jusqu'à une position de journal binaire donnée.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Si nous souhaitons utiliser GTID, la commande sera différente :
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)Une fois la réplication arrêtée (c'est-à-dire que tous les événements que nous avons demandés ont été exécutés), nous devons vérifier que l'hôte contient les données manquantes. Si tel est le cas, vous pouvez le promouvoir en tant que maître, puis reconstruire d'autres hôtes en utilisant le nouveau maître comme source de données.
Ce n'est pas toujours la meilleure option. Tout dépend du retard de votre esclave - s'il est retardé de quelques heures, il n'est peut-être pas logique d'attendre qu'il se rattrape, surtout si le trafic d'écriture est important dans votre environnement. Dans ce cas, il est probablement plus rapide de reconstruire les hôtes à l'aide d'une sauvegarde physique. D'un autre côté, si vous avez un volume de trafic plutôt faible, cela pourrait être un bon moyen de résoudre rapidement le problème, de promouvoir un nouveau maître et de continuer à servir le trafic, tandis que le reste des nœuds est reconstruit en arrière-plan. .
Perte partielle de données - Sauvegarde physique
En cas de perte partielle de données, les sauvegardes physiques peuvent être inefficaces mais, comme il s'agit du type de sauvegarde le plus courant, il est très important de savoir comment les utiliser pour une restauration partielle. La première étape consistera toujours à restaurer une sauvegarde jusqu'à un moment donné avant l'événement de perte de données. Il est également très important de le restaurer sur un hôte distinct. ClusterControl utilise xtrabackup pour les sauvegardes physiques, nous allons donc montrer comment l'utiliser. Supposons que nous ayons exécuté la requête incorrecte suivante :
DELETE FROM sbtest1 WHERE id < 23146;
Nous voulions supprimer une seule ligne (‘=’ dans la clause WHERE), à la place nous en avons supprimé un tas (
Maintenant, regardons le fichier de sortie et voyons ce que nous pouvons y trouver. Nous utilisons la réplication basée sur les lignes, nous ne verrons donc pas le code SQL exact qui a été exécuté. Au lieu de cela (tant que nous utiliserons l'indicateur --verbose pour mysqlbinlog), nous verrons des événements comme ci-dessous :
Comme on peut le voir, MySQL identifie les lignes à supprimer en utilisant une condition WHERE très précise. Des signes mystérieux dans le commentaire lisible par l'homme, "@1", "@2", signifient "première colonne", "deuxième colonne". Nous savons que la première colonne est 'id', ce qui nous intéresse. Nous devons trouver un grand événement DELETE sur une table 'sbtest1'. Les commentaires qui suivront doivent mentionner l'identifiant de 1, puis l'identifiant de "2", puis "3" et ainsi de suite - le tout jusqu'à l'identifiant de "23145". Tout doit être exécuté en une seule transaction (un seul événement dans un journal binaire). Après avoir analysé la sortie à l'aide de "moins", nous avons trouvé :
L'événement, auquel ces commentaires sont joints, a commencé à :
Donc, nous voulons restaurer la sauvegarde jusqu'au commit précédent à la position 29600687. Faisons-le maintenant. Nous utiliserons un serveur externe pour cela. Nous restaurerons la sauvegarde jusqu'à cette position et nous maintiendrons le serveur de restauration opérationnel afin que nous puissions ensuite extraire les données manquantes.
Une fois la restauration terminée, assurons-nous que nos données ont bien été récupérées :
Cela semble bon. Nous pouvons maintenant extraire ces données dans un fichier que nous rechargerons sur le maître.
Quelque chose ne va pas - c'est parce que le serveur est configuré pour pouvoir écrire des fichiers uniquement dans un emplacement particulier - c'est une question de sécurité, nous ne voulons pas laisser les utilisateurs enregistrer le contenu où ils veulent. Voyons où nous pouvons enregistrer notre fichier :
Ok, essayons encore une fois :
Maintenant, ça a l'air beaucoup mieux. Copions les données dans le maître :
Il est maintenant temps de charger les lignes manquantes sur le maître et de tester si cela a réussi :
C'est tout, nous avons restauré nos données manquantes.
Dans la section précédente, nous avons restauré les données perdues à l'aide d'une sauvegarde physique et d'un serveur externe. Et si nous avions créé une sauvegarde logique ? Nous allons jeter un coup d'oeil. Tout d'abord, vérifions que nous avons bien une sauvegarde logique :
Oui, c'est là. Maintenant, il est temps de le décompresser.
Lorsque vous l'examinerez, vous verrez que les données sont stockées au format INSERT à valeurs multiples. Par exemple :
Il ne nous reste plus qu'à déterminer où se trouve notre table, puis où sont stockées les lignes qui nous intéressent. Tout d'abord, connaissant les modèles mysqldump (supprimer une table, en créer une nouvelle, désactiver les index, insérer des données), déterminons quelle ligne contient l'instruction CREATE TABLE pour la table 'sbtest1' :
Maintenant, en utilisant une méthode d'essais et d'erreurs, nous devons déterminer où chercher nos lignes. Nous allons vous montrer la commande finale que nous avons trouvée. L'astuce consiste à essayer d'imprimer différentes plages de lignes à l'aide de sed, puis de vérifier si la dernière ligne contient des lignes proches de, mais plus tardives que ce que nous recherchons. Dans la commande ci-dessous, nous recherchons les lignes entre 971 (CREATE TABLE) et 993. Nous demandons également à sed de quitter une fois qu'il atteint la ligne 994 car le reste du fichier ne nous intéresse pas :
La sortie ressemble à ci-dessous :
Cela signifie que notre plage de lignes (jusqu'à la ligne avec l'identifiant 23145) est proche. Ensuite, il s'agit du nettoyage manuel du fichier. Nous voulons qu'il commence par la première ligne que nous devons restaurer :
Et terminez avec la dernière ligne à restaurer :
Nous avons dû supprimer certaines des données inutiles (il s'agit d'une insertion multiligne), mais après tout cela, nous avons un fichier que nous pouvons recharger sur le maître.
Enfin, dernière vérification :
Tout va bien, les données ont été restaurées.
Dans ce cas, nous ne suivrons pas tout le processus. Nous avons déjà décrit comment identifier la position d'un événement de perte de données dans les journaux binaires. Nous avons également décrit comment arrêter un esclave retardé et redémarrer la réplication, jusqu'à un certain point avant l'événement de perte de données. Nous avons également expliqué comment utiliser SELECT INTO OUTFILE et LOAD DATA INFILE pour exporter des données depuis un serveur externe et les charger sur le maître. C'est tout ce dont vous avez besoin. Tant que les données sont encore sur l'esclave retardé, vous devez l'arrêter. Ensuite, vous devez localiser la position avant l'événement de perte de données, démarrer l'esclave jusqu'à ce point et, une fois cela fait, utiliser l'esclave retardé pour extraire les données qui ont été supprimées, copier le fichier sur le maître et le charger pour restaurer les données. .
Restaurer des données perdues n'est pas amusant, mais si vous suivez les étapes que nous avons suivies dans ce blog, vous aurez de bonnes chances de récupérer ce que vous avez perdu.mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826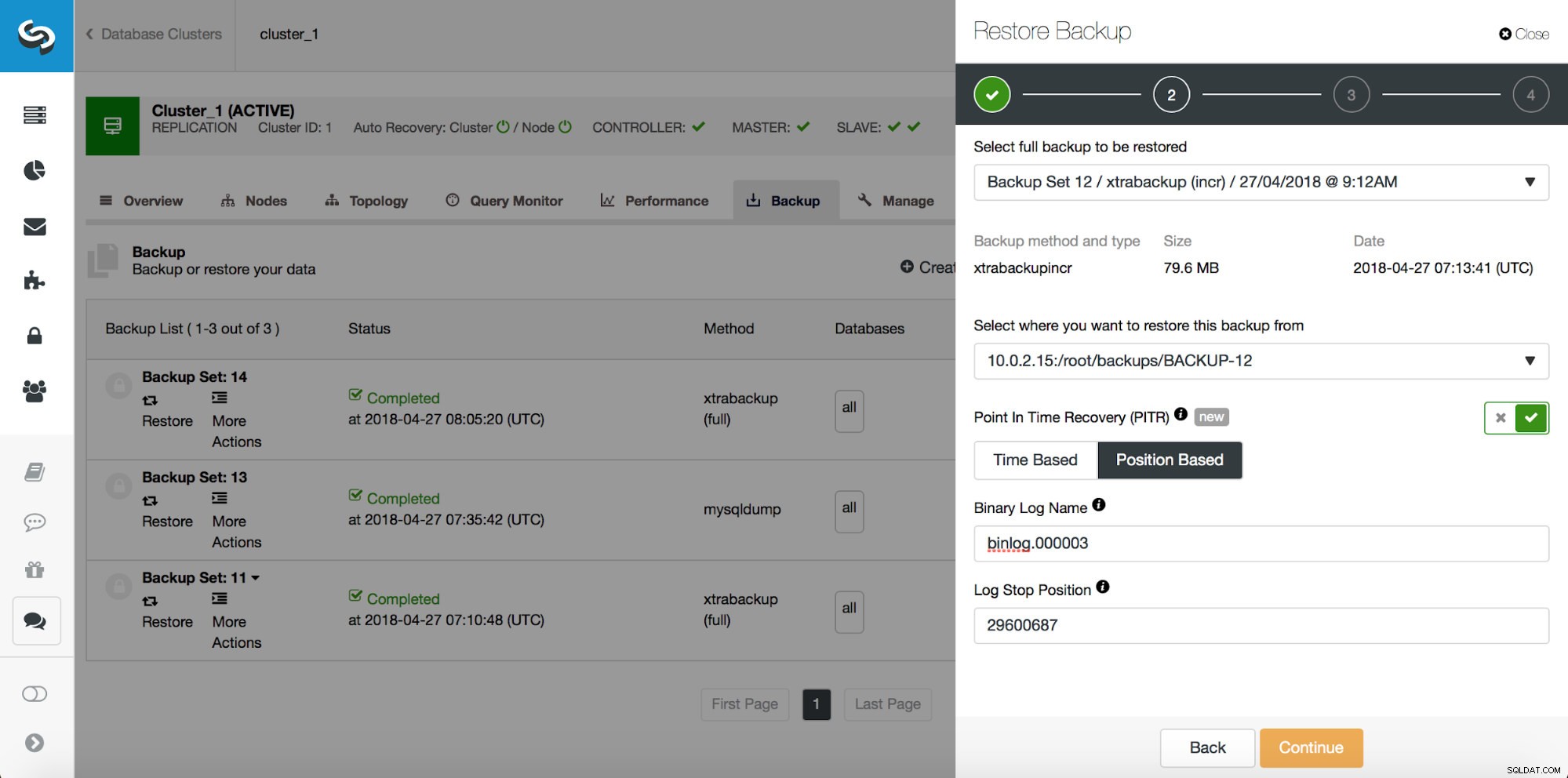
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Perte partielle de données - Sauvegarde logique
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzexample@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlINSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessINSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Perte de données partielle, esclave retardé
Conclusion