Cela est dû à ce que j'appelle la règle des 5 % basée sur la population clé (cardinalité des tuples).
Si vous indexez une table où une cardinalité déséquilibrée existe, l'optimiseur de requête MySQL choisira toujours le chemin de moindre résistance.
EXEMPLE :Si une table a une colonne de genre, la cardinalité est deux, M et F.
Qu'est-ce que vous indexez une telle colonne genre ??? Vous obtenez essentiellement deux listes liées géantes.
Si vous chargez un million de lignes dans un tableau avec une colonne de sexe, vous pouvez obtenir 50 % M et 50 % F.
Un index est rendu inutile lors de l'optimisation de la requête si la cardinalité d'une combinaison de clés (population de clés comme je l'ai formulé) est supérieure à 5 % du nombre total de tables.
Maintenant, en ce qui concerne votre exemple, pourquoi les deux plans EXPLAIN différents ??? Je suppose que MySQL Query Optimizer et InnoDB forment une équipe de balises.
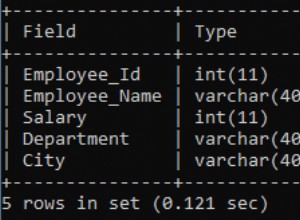
Dans le premier CREATE TABLE, la table et les index sont à peu près de la même taille bien que petits, donc il a décidé en faveur de l'index en faisant une analyse d'index et non une analyse complète de la table . Gardez à l'esprit que les index non uniques comportent la clé primaire interne de chaque ligne (RowID) dans ses entrées d'index, ce qui donne aux index presque la même taille que la table elle-même.
Dans la deuxième CREATE TABLE, en raison de l'introduction d'une autre colonne, user, vous faites maintenant voir à l'optimiseur de requête un scénario complètement différent :la table est maintenant plus grande que les index . Par conséquent, l'optimiseur de requête est devenu plus strict dans son interprétation de la façon d'utiliser les index disponibles. Il est allé à la règle des 5% que j'ai mentionnée précédemment. Cette règle a lamentablement échoué et l'optimiseur de requête a opté pour une analyse complète de la table.