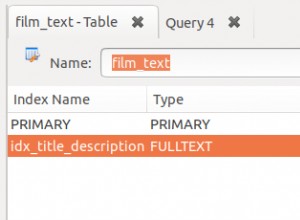
Si vos données sont uniques, vous devez créer un UNIQUE indexez-les.
Cela n'implique aucune surcharge supplémentaire et affecte les décisions de l'optimiseur dans certains cas afin qu'il puisse choisir un meilleur algorithme.
Dans SQL Server et dans PostgreSQL , par exemple, si vous triez sur un UNIQUE clé, l'optimiseur ignore le ORDER BY les clauses utilisées par la suite (puisqu'elles ne sont pas pertinentes), i. e. cette requête :
SELECT *
FROM mytable
ORDER BY
col_unique, other_col
LIMIT 10
utilisera un index sur col_unique et ne triera pas sur other_col parce que c'est inutile.
Cette requête :
SELECT *
FROM mytable
WHERE mycol IN
(
SELECT othercol
FROM othertable
)
sera également converti en un INNER JOIN (par opposition à un SEMI JOIN ) s'il y a un UNIQUE index sur othertable.othercol .
Un index contient toujours une sorte de pointeur vers la ligne (ctid dans PostgreSQL , pointeur de ligne dans MyISAM , clé primaire/uniquificateur dans InnoDB ) et les feuilles sont ordonnées sur ces pointeurs, donc en fait chaque feuille d'index est unique d'une certaine manière (bien que ce ne soit pas évident).
Consultez cet article sur mon blog pour plus de détails sur les performances :