C'est un obstacle classique auquel la plupart des programmeurs MySQL se heurtent.
- Vous avez une colonne
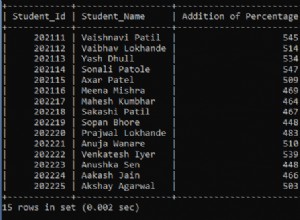
ticket_idc'est l'argument deGROUP BY. Des valeurs distinctes dans cette colonne définissent les groupes. - Vous avez une colonne
incoming_timec'est l'argument deMAX(). La plus grande valeur de cette colonne sur les lignes de chaque groupe est renvoyée en tant que valeur deMAX(). - Vous avez toutes les autres colonnes du tableau article. Les valeurs renvoyées pour ces colonnes sont arbitraires, et ne proviennent pas de la même ligne où le
MAX()valeur se produit.
La base de données ne peut pas déduire que vous voulez des valeurs de la même ligne où se trouve la valeur maximale.
Pensez aux cas suivants :
-
Il existe plusieurs lignes où la même valeur maximale se produit. Quelle ligne doit être utilisée pour afficher les colonnes de
article.*? -
Vous écrivez une requête qui renvoie à la fois le
MIN()et leMAX(). C'est légal, mais quelle ligne devraitarticle.*afficher ?SELECT article.* , MIN(article.incoming_time), MAX(article.incoming_time) FROM ticket, article WHERE ticket.id = article.ticket_id AND ticket.queue_id = 1 GROUP BY article.ticket_id -
Vous utilisez une fonction d'agrégation telle que
AVG()ouSUM(), où aucune ligne n'a cette valeur. Comment la base de données peut-elle deviner quelle ligne afficher ?SELECT article.* , AVG(article.incoming_time) FROM ticket, article WHERE ticket.id = article.ticket_id AND ticket.queue_id = 1 GROUP BY article.ticket_id
Dans la plupart des marques de bases de données - ainsi que dans le standard SQL lui-même - vous n'êtes pas autorisé pour écrire une requête comme celle-ci, à cause de l'ambiguïté. Vous ne pouvez pas inclure de colonne dans la liste de sélection qui ne se trouve pas dans une fonction d'agrégation ou nommée dans le GROUP BY clause.
MySQL est plus permissif. Il vous permet de le faire et vous laisse le soin d'écrire des requêtes sans ambiguïté. Si vous avez une ambiguïté, il sélectionne les valeurs de la ligne qui est physiquement la première dans le groupe (mais cela dépend du moteur de stockage).
Pour ce que ça vaut, SQLite a aussi ce comportement, mais il choisit le dernier rangée dans le groupe pour résoudre l'ambiguïté. Allez comprendre. Si la norme SQL ne dit pas quoi faire, c'est à l'implémentation du fournisseur de décider.
Voici une requête qui peut résoudre votre problème pour vous :
SELECT a1.* , a1.incoming_time AS maxtime
FROM ticket t JOIN article a1 ON (t.id = a1.ticket_id)
LEFT OUTER JOIN article a2 ON (t.id = a2.ticket_id
AND a1.incoming_time < a2.incoming_time)
WHERE t.queue_id = 1
AND a2.ticket_id IS NULL;
En d'autres termes, recherchez une ligne (a1 ) pour lequel il n'y a pas d'autre ligne (a2 ) avec le même ticket_id et un incoming_time supérieur . S'il n'y a pas plus de incoming_time est trouvé, le LEFT OUTER JOIN renvoie NULL au lieu d'une correspondance.