Dans mon article précédent, j'ai discuté des attentes CXPACKET et des moyens d'empêcher ou de limiter le parallélisme. J'ai également expliqué comment le thread de contrôle dans une opération parallèle enregistre toujours une attente CXPACKET, et que parfois des threads non contrôlés peuvent également enregistrer des attentes CXPACKET. Cela peut se produire si l'un des threads est bloqué en attente d'une ressource (donc tous les autres threads se terminent avant lui et enregistrent également les attentes de CXPACKET), ou si les estimations de cardinalité sont incorrectes. Dans cet article, j'aimerais explorer ce dernier.
Lorsque les estimations de cardinalité sont incorrectes, les threads parallèles effectuant le travail de requête reçoivent des quantités de travail inégales. Le cas typique est celui où un thread reçoit tout le travail, ou bien plus de travail que les autres threads. Cela signifie que les threads qui terminent le traitement de leurs lignes (s'ils en ont même reçu) avant que le thread le plus lent enregistrent un CXPACKET à partir du moment où ils se terminent jusqu'à ce que le thread le plus lent se termine. Ce problème peut conduire à une explosion apparente des attentes CXPACKET et est communément appelé parallélisme biaisé , car la répartition du travail entre les threads parallèles est faussée, pas égale.
Notez que dans SQL Server 2016 SP2 et SQL Server 2017 RTM CU3, les threads consommateurs n'enregistrent plus les attentes CXPACKET. Ils enregistrent les attentes CXCONSUMER, qui sont bénignes et peuvent être ignorées. Cela permet de réduire le nombre d'attentes CXPACKET générées, et les autres sont plus susceptibles d'être exploitables.
Exemple de parallélisme asymétrique
Je vais parcourir un exemple artificiel pour montrer comment identifier de tels cas.
Tout d'abord, je vais créer un scénario dans lequel une table contient des statistiques extrêmement inexactes, en définissant manuellement le nombre de lignes et de pages dans un UPDATE STATISTICS déclaration (ne faites pas cela en production !) :
USE [master];
GO
IF DB_ID (N'ExecutionMemory') IS NOT NULL
BEGIN
ALTER DATABASE [ExecutionMemory] SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE [ExecutionMemory];
END
GO
CREATE DATABASE [ExecutionMemory];
GO
USE [ExecutionMemory];
GO
CREATE TABLE dbo.[Test] (
[RowID] INT IDENTITY,
[ParentID] INT,
[CurrentValue] NVARCHAR (100),
CONSTRAINT [PK_Test] PRIMARY KEY CLUSTERED ([RowID]));
GO
INSERT INTO dbo.[Test] ([ParentID], [CurrentValue])
SELECT
CASE WHEN ([t1].[number] % 3 = 0)
THEN [t1].[number] – [t1].[number] % 6
ELSE [t1].[number] END,
'Test' + CAST ([t1].[number] % 2 AS VARCHAR(11))
FROM [master].[dbo].[spt_values] AS [t1]
WHERE [t1].[type] = 'P';
GO
UPDATE STATISTICS dbo.[Test] ([PK_Test]) WITH ROWCOUNT = 10000000, PAGECOUNT = 1000000;
GO Donc, ma table ne contient que quelques milliers de lignes, mais j'ai simulé qu'elle avait 10 millions de lignes.
Je vais maintenant créer une requête artificielle pour sélectionner les 500 premières lignes, qui iront en parallèle car elle pense qu'il y a des millions de lignes à analyser.
USE [ExecutionMemory];
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentValue NVARCHAR (100);
WHILE (1=1)
SELECT TOP (500)
@CurrentValue = [CurrentValue]
FROM dbo.[Test]
ORDER BY NEWID() DESC;
GO Et mettez ça en marche.
Affichage des attentes CXPACKET
Maintenant, je peux regarder les attentes CXPACKET qui se produisent à l'aide d'un simple script pour regarder les sys.dm_os_waiting_tasks DMV :
SELECT
[owt].[session_id],
[owt].[exec_context_id],
[owt].[wait_duration_ms],
[owt].[wait_type],
[owt].[blocking_session_id],
[owt].[resource_description],
[er].[database_id],
[eqp].[query_plan]
FROM sys.dm_os_waiting_tasks [owt]
INNER JOIN sys.dm_exec_sessions [es] ON
[owt].[session_id] = [es].[session_id]
INNER JOIN sys.dm_exec_requests [er] ON
[es].[session_id] = [er].[session_id]
OUTER APPLY sys.dm_exec_sql_text ([er].[sql_handle]) [est]
OUTER APPLY sys.dm_exec_query_plan ([er].[plan_handle]) [eqp]
WHERE
[es].[is_user_process] = 1
ORDER BY
[owt].[session_id],
[owt].[exec_context_id]; Si j'exécute cela plusieurs fois, je vois finalement des résultats montrant un parallélisme biaisé (j'ai supprimé le lien de la poignée du plan de requête et raccourci la description de la ressource, pour plus de clarté, et remarquez que j'ai mis le code pour saisir le texte SQL si vous voulez que aussi):
| session_id | exec_context_id | wait_duration_ms | wait_type | blocking_session_id | description_ressource | database_id |
|---|---|---|---|---|---|---|
56 | 0 | 1 | CXPACKET | NULL | exchangeEvent | 13 |
56 | 1 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 3 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 4 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 5 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 6 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
56 | 7 | 1 | CXPACKET | 56 | exchangeEvent | 13 |
Résultats montrant un parallélisme asymétrique en action
Le thread de contrôle est celui avec exec_context_id mis à 0. Les autres threads parallèles sont ceux avec exec_context_id supérieur à 0, et ils affichent tous les attentes CXPACKET à l'exception d'un (notez que exec_context_id = 2 est absent de la liste). Vous remarquerez qu'ils listent tous leur propre session_id comme celui qui les bloque, et c'est correct car tous les threads attendent un autre thread à partir de leur propre session_id compléter. Le database_id est la base de données dans le contexte de laquelle la requête est exécutée, pas nécessairement la base de données où se trouve le problème, mais c'est généralement le cas, sauf si la requête utilise une dénomination en trois parties pour s'exécuter dans une base de données différente.
Affichage du problème d'estimation de cardinalité
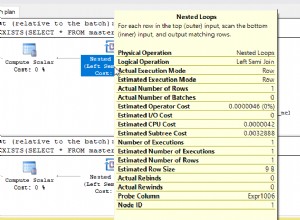
Avec le query_plan dans la sortie de la requête (que j'ai supprimée pour plus de clarté), vous pouvez cliquer dessus pour afficher le plan graphique, puis cliquer avec le bouton droit et sélectionner Afficher avec l'explorateur de plans SQL Sentry. Cela se présente comme ci-dessous :
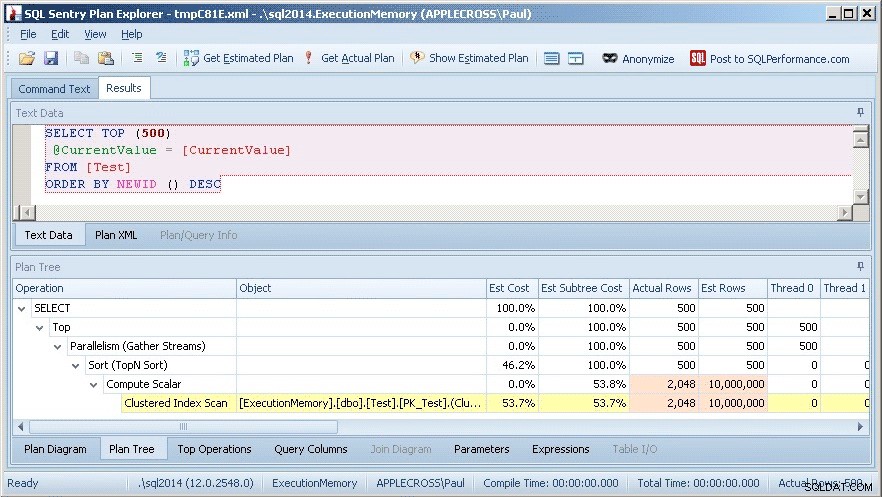
Je peux voir immédiatement qu'il y a un problème d'estimation de cardinalité, car les lignes réelles pour l'analyse de l'index clusterisé ne sont que de 2 048, contre 10 000 000 de lignes Est (estimées).
Si je fais défiler, je peux voir la distribution des lignes sur les threads parallèles qui ont été utilisés :
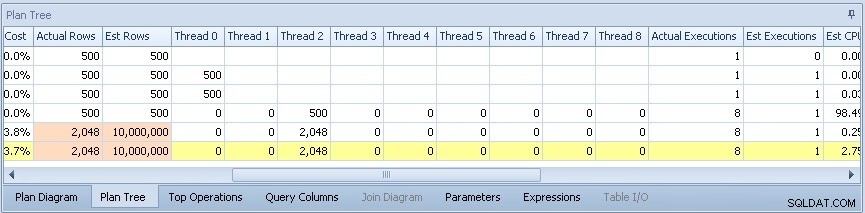
Et voilà, un seul thread faisait du travail pendant la partie parallèle du plan - celui qui n'apparaissait pas dans le sys.dm_os_waiting_tasks sortie ci-dessus.
Dans ce cas, le correctif consiste à mettre à jour les statistiques de la table.
Dans mon exemple artificiel, cela ne fonctionnera pas, car il n'y a eu aucune modification de la table, je vais donc relancer le script de configuration, en omettant les UPDATE STATISTICS déclaration.
Le plan de requête devient alors :
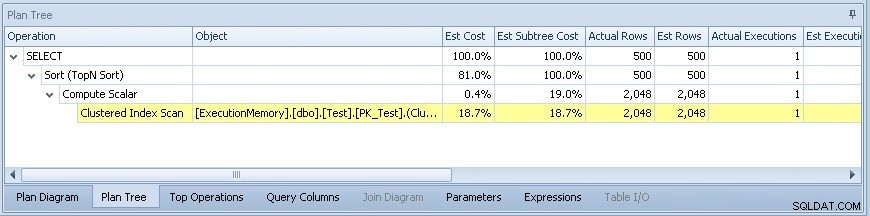
Là où il n'y a pas de problème de cardinalité ni de parallélisme non plus - problème résolu !
Résumé
Si vous voyez des attentes CXPACKET se produire, il est facile de vérifier le parallélisme biaisé, en utilisant la méthode décrite ci-dessus. Tous les cas que j'ai vus étaient dus à des problèmes d'estimation de cardinalité d'un type ou d'un autre, et il s'agit souvent simplement d'une mise à jour des statistiques.
En ce qui concerne les statistiques d'attente générales, vous pouvez trouver plus d'informations sur leur utilisation pour le dépannage des performances dans :
- Ma série d'articles de blog SQLskills, en commençant par les statistiques d'attente, ou dites-moi où ça fait mal ;
- Bibliothèque de mes types d'attente et de mes classes de verrouillage ici
- Ma formation en ligne Pluralsight SQL Server :Dépannage des performances à l'aide des statistiques d'attente
- Sentry SQL
Jusqu'à la prochaine fois, bon dépannage !