En travaillant avec des noms de personnes et en faisant des recherches floues sur eux, ce qui a fonctionné pour moi a été de créer une deuxième table de mots. Créez également une troisième table qui est une table d'intersection pour la relation plusieurs à plusieurs entre la table contenant le texte et la table de mots. Lorsqu'une ligne est ajoutée au tableau de texte, vous divisez le texte en mots et remplissez le tableau d'intersection de manière appropriée, en ajoutant de nouveaux mots au tableau de mots si nécessaire. Une fois cette structure en place, vous pouvez effectuer des recherches un peu plus rapidement, car vous n'avez qu'à exécuter votre fonction damlev sur la table des mots uniques. Une simple jointure vous permet d'obtenir le texte contenant les mots correspondants. 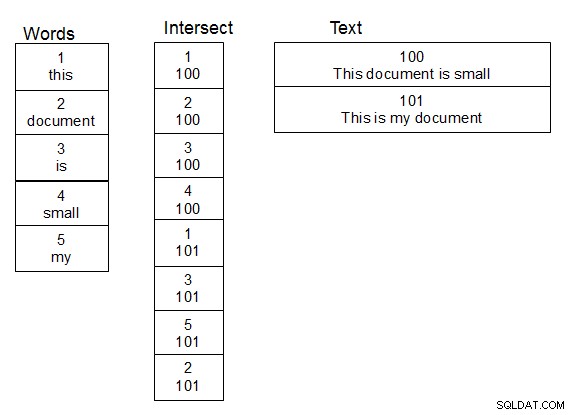
Une requête pour un seul mot correspondant ressemblerait à ceci :
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
et deux mots ressembleraient à ceci (sur le dessus de ma tête, donc peut-être pas tout à fait correct):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Les avantages ici, au prix d'un peu d'espace dans la base de données, sont que vous n'avez qu'à appliquer la fonction damlev, qui prend du temps, aux mots uniques, qui ne compteront probablement que des dizaines de milliers, quelle que soit la taille de votre table de texte. Ceci est important, car l'UDF damlev n'utilisera pas d'index - il analysera toute la table sur laquelle il est appliqué pour calculer une valeur pour chaque ligne. Numériser uniquement les mots uniques devrait être beaucoup plus rapide. L'autre avantage est que le damlev est appliqué au niveau du mot, ce qui semble être ce que vous demandez. Un autre avantage est que vous pouvez étendre la requête pour prendre en charge la recherche sur plusieurs mots et classer les résultats en regroupant les lignes d'intersection correspondantes sur TextId et en les classant sur le nombre de correspondances.



