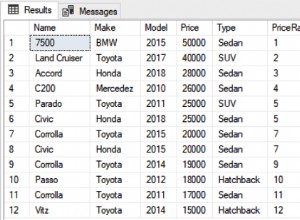
Étant donné que vous utilisez la colonne id comme indicateur de l'enregistrement "original" :
delete x
from myTable x
join myTable z on x.subscriberEmail = z.subscriberEmail
where x.id > z.id
Cela laissera un enregistrement par adresse e-mail.
modifier pour ajouter :
Pour expliquer la requête ci-dessus...
L'idée ici est de rejoindre la table contre elle-même. Imaginez que vous avez deux copies de la table, chacune portant un nom différent. Ensuite, vous pouvez les comparer les uns aux autres et trouver l'identifiant le plus bas ou pour chaque adresse e-mail. Vous verriez alors les enregistrements en double créés ultérieurement et pourriez les supprimer. (Je visualisais Excel en y pensant.)
Pour faire cette opération sur une table, la comparer à elle-même et pouvoir identifier chaque côté, vous utilisez des alias de table. x est un alias de table. Il est attribué dans le from clause comme ceci :from <table> <alias> . x peut maintenant être utilisé ailleurs dans la même requête pour faire référence à cette table en tant que raccourci.
delete x démarre la requête avec notre action et notre cible. Nous allons effectuer une requête pour sélectionner des enregistrements dans plusieurs tables, et nous voulons supprimer les enregistrements qui apparaissent dans x .
Les alias sont utilisés pour faire référence aux deux "instances" de la table. from myTable x join myTable z on x.subscriberEmail = z.subscriberEmail heurte la table contre elle-même là où les e-mails correspondent. Sans la clause where qui suit, chaque enregistrement serait sélectionné car il pourrait être joint à lui-même.
Le where La clause limite les enregistrements sélectionnés. where x.id > z.id autorise l''instance' aliasée x pour contenir uniquement les enregistrements qui correspondent aux e-mails mais qui ont un id plus élevé valeur. Les données que vous voulez vraiment dans le tableau, les adresses e-mail uniques (avec l'identifiant le plus bas) ne feront pas partie de x et ne sera pas supprimé. Les seuls enregistrements dans x seront des enregistrements en double (adresses e-mail) qui ont un id plus élevé que l'enregistrement d'origine pour cette adresse e-mail.
Les clauses join et where pourraient être combinées dans ce cas :
delete x
from myTable x
join myTable z
on x.subscriberEmail = z.subscriberEmail
and x.id > z.id
Pour éviter les doublons, envisagez de faire de la colonne subscriberEmail une colonne indexée UNIQUE.