Comment les tables MySQL sont-elles corrompues ? Il existe de nombreuses façons de gâcher des fichiers de données. Souvent, la corruption est due à des défauts de la plate-forme sous-jacente, sur laquelle MySQL s'appuie pour stocker et récupérer des données - sous-système de disque, contrôleurs, canaux de communication, pilotes, micrologiciels ou autres défauts matériels. La corruption des données peut également se produire si le démon du serveur MySQL redémarre soudainement ou si votre serveur redémarre en raison d'un plantage d'autres composants du système d'exploitation. Si l'instance de base de données était en train d'écrire des données sur le disque, elle pourrait écrire partiellement les données, ce qui pourrait se retrouver avec une somme de contrôle de page différente de celle attendue. Il y a également eu des bogues dans MySQL, donc même si le matériel du serveur est correct, MySQL lui-même peut provoquer une corruption.
Habituellement, lorsque les données MySQL sont corrompues, la recommandation est de les restaurer à partir de la dernière sauvegarde, de passer au serveur DR ou de supprimer le nœud affecté si vous avez un cluster Galera pour servir immédiatement les données à partir d'autres nœuds. Dans certains cas, vous ne pouvez pas - si la sauvegarde n'est pas là, le cluster n'a jamais été configuré, votre réplication est arrêtée depuis très longtemps ou la procédure DR n'a jamais été testée. Même si vous disposez d'une sauvegarde, vous souhaiterez peut-être prendre certaines mesures pour tenter une récupération, car cela peut prendre moins de temps pour se remettre en ligne.
MyISAM, le méchant et le laid
InnoDB est plus tolérant aux pannes que MyISAM. InnoDB a des fonctionnalités de récupération automatique et est beaucoup plus sûr que l'ancien moteur MyISAM.
Les tables MyISAM peuvent facilement être corrompues lorsque de nombreuses écritures se produisent et que de nombreux verrous se produisent sur cette table. Le moteur de stockage "écrit" les données dans le cache du système de fichiers, ce qui peut prendre un certain temps avant qu'il ne soit vidé sur le disque. Par conséquent, si votre serveur redémarre soudainement, une quantité inconnue de données dans le cache est perdue. C'est une façon habituelle de corrompre les données MyISAM. La recommandation est de migrer de MyISAM vers InnoDB, mais il peut y avoir des cas où cela n'est pas possible.
Primum non nocere, la sauvegarde
Avant de tenter de réparer des tables corrompues, vous devez d'abord sauvegarder vos fichiers de base de données. Oui, il est déjà cassé, mais c'est pour minimiser le risque d'éventuels dommages supplémentaires qui pourraient être causés par une opération de récupération. Il n'y a aucune garantie que toute action que vous entreprenez n'endommagera pas les blocs de données intacts. Forcer la récupération d'InnoDB avec des valeurs supérieures à 4 peut corrompre les fichiers de données, alors assurez-vous de le faire avec une sauvegarde préalable et idéalement sur une copie physique distincte de la base de données.
Pour sauvegarder tous les fichiers de toutes vos bases de données, procédez comme suit :
Arrêtez le serveur MySQL
service mysqld stopTapez la commande suivante pour votre datadir.
cp -r /var/lib/mysql /var/lib/mysql_bkpUne fois que nous avons une copie de sauvegarde du répertoire de données, nous sommes prêts à commencer le dépannage.
Identification de la corruption des données
Le journal des erreurs est votre meilleur ami. Généralement, en cas de corruption des données, vous trouverez des informations pertinentes (y compris des liens vers la documentation) dans le journal des erreurs. Si vous ne savez pas où il se trouve, vérifiez my.cnf et la variable log_error, pour plus de détails, consultez cet article https://dev.mysql.com/doc/refman/8.0/en/error-log-destination-configuration. html. Ce que vous devez également savoir, c'est votre type de moteur de stockage. Vous pouvez trouver ces informations dans le journal des erreurs ou dans information_schema.
mysql> select table_name,engine from information_schema.tables where table_name = '<TABLE>' and table_schema = '<DATABASE>';Les principaux outils/commandes pour diagnostiquer les problèmes de corruption des données sont CHECK TABLE, REPAIR TABLE et myisamchk. Le client mysqlcheck effectue la maintenance des tables :il vérifie, répare (MyISAM), optimise ou analyse les tables pendant que MySQL est en cours d'exécution.
mysqlcheck -uroot -p <DATABASE>Remplacez DATABASE par le nom de la base de données et remplacez TABLE par le nom de la table que vous souhaitez vérifier :
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck vérifie la base de données et les tables spécifiées. Si une table passe la vérification, mysqlcheck affiche OK pour la table.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKLes problèmes de corruption de données peuvent également être liés à des problèmes d'autorisation. Dans certains cas, le système d'exploitation peut basculer le point de montage en mode lecture seule en raison de problèmes R/W ou cela peut être causé par un utilisateur qui a accidentellement changé la propriété des fichiers de données. Dans de tels cas, vous trouverez des informations pertinentes dans le journal des erreurs.
[example@sqldat.com employees]# ls -rtla
...
-rw-rw----. 1 mysql mysql 28311552 05-10 06:24 titles.ibd
-rw-r-----. 1 root root 109051904 05-10 07:09 salaries.ibd
drwxr-xr-x. 7 mysql mysql 4096 05-10 07:12 ..
drwx------. 2 mysql mysql 4096 05-10 07:17 .Client MySQL
MariaDB [employees]> select count(*) from salaries;
ERROR 1932 (42S02): Table 'employees.salaries' doesn't exist in engineEntrée du journal des erreurs
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Failed to find tablespace for table `employees`.`salaries` in the cache. Attempting to load the tablespace with space id 9
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Operating system error number 13 in a file operation.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Cannot open datafile for read-only: './employees/salaries.ibd' OS error: 81
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Operating system error number 13 in a file operation.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Could not find a valid tablespace file for `employees/salaries`. Please refer to https://dev.mysql.com/doc/refman/5.7/en/innodb-troubleshooting-datadict.html for how to resolve the issue.Récupération de la table InnoDB
Si vous utilisez le moteur de stockage InnoDB pour une table de base de données, vous pouvez exécuter le processus de récupération InnoDB.
Pour activer la récupération automatique, MySQL doit activer l'option innodb_force_recovery. Innodb_force_recovery force InnoDB à démarrer tout en empêchant les opérations en arrière-plan de s'exécuter, afin que vous puissiez vider vos tables.
Pour ce faire, ouvrez my.cnf et ajoutez la ligne suivante à la section [mysqld] :
[mysqld]
innodb_force_recovery=1
service mysql restartVous devez commencer à partir de innodb_force_recovery=1, enregistrer les modifications apportées au fichier my.cnf, puis redémarrer le serveur MySQL à l'aide de la commande appropriée pour votre système d'exploitation. Si vous êtes capable de vider vos tables avec une valeur innodb_force_recovery de 3 ou moins, alors vous êtes relativement en sécurité. Dans de nombreux cas, vous devrez monter jusqu'à 4 et comme vous le savez déjà, cela peut corrompre les données.
[mysqld]
innodb_force_recovery=1
service mysql restartSi nécessaire, passez à la valeur la plus élevée, six est le maximum et le plus dangereux.
Une fois que vous êtes en mesure de démarrer votre base de données, tapez la commande suivante pour exporter toutes les bases de données vers le fichier databases.sql :
mysqldump --all-databases --add-drop-database --add-drop-table > dump.sqlDémarrez mysql, puis essayez de supprimer la ou les bases de données concernées à l'aide de la commande DROP DATABASE. Si MySQL ne parvient pas à supprimer une base de données, vous pouvez la supprimer manuellement en suivant les étapes ci-dessous après avoir arrêté le serveur MySQL.
service mysqld stopSi vous n'avez pas pu supprimer une base de données, saisissez les commandes suivantes pour la supprimer manuellement.
cd /var/lib/mysql
rm -rf <DATABASE>
Assurez-vous de ne pas supprimer les répertoires internes de la base de données.
Une fois que vous avez terminé, commentez la ligne suivante dans [mysqld] pour désactiver le mode de récupération InnoDB.
#innodb_force_recovery=...Enregistrez les modifications dans le fichier my.cnf, puis démarrez le serveur MySQL
service mysqld startTapez la commande suivante pour restaurer les bases de données à partir du fichier de sauvegarde que vous avez créé à l'étape 5 :
mysql> tee import_database.log
mysql> source dump.sqlRéparer MyISAM
Si mysqlcheck signale une erreur pour une table, tapez la commande mysqlcheck avec l'indicateur -repair pour la corriger. L'option de réparation mysqlcheck fonctionne lorsque le serveur est opérationnel.
mysqlcheck -uroot -p -r <DATABASE> <TABLE>Si le serveur est en panne et que, pour une raison quelconque, mysqlcheck ne peut pas réparer votre table, vous avez toujours la possibilité d'effectuer une récupération directement sur les fichiers à l'aide de myisamchk. Avec myisamchk, vous devez vous assurer que le serveur n'a pas les tables ouvertes.
Arrêtez MySQL
service mysqld stop
cd /var/lib/mysqlAccédez au répertoire où se trouve la base de données.
cd /var/lib/mysql/employees
myisamchk <TABLE>Pour vérifier toutes les tables d'une base de données, tapez la commande suivante :
myisamchk *.MYISi la commande précédente ne fonctionne pas, vous pouvez essayer de supprimer les fichiers temporaires qui peuvent empêcher myisamchk de s'exécuter correctement. Pour ce faire, revenez au répertoire data dir, puis exécutez la commande suivante :
ls */*.TMDSi des fichiers .TMD sont répertoriés, supprimez-les :
rm */*.TMDPuis relancez myisamchk.
Pour tenter de réparer une table, exécutez la commande suivante en remplaçant TABLE par le nom de la table que vous souhaitez réparer :
myisamchk --recover <TABLE>Redémarrez le serveur MySQL
service mysqld startComment éviter la perte de données
Il y a plusieurs choses que vous pouvez faire pour minimiser le risque de données irrécupérables. Tout d'abord les sauvegardes. Le problème avec les sauvegardes est qu'elles peuvent parfois être négligées. Pour les sauvegardes planifiées cron, nous écrivons généralement des scripts wrapper qui détectent les problèmes dans le journal de sauvegarde, mais cela n'inclut pas les cas où la sauvegarde n'a pas démarré du tout. Cron peut parfois se bloquer et souvent aucune surveillance n'est définie dessus. Un autre problème potentiel pourrait être le cas où la sauvegarde n'a jamais été configurée. La bonne pratique consiste à exécuter des rapports à partir d'un outil distinct qui analysera l'état de la sauvegarde et vous informera des planifications de sauvegarde manquantes. Vous pouvez utiliser ClusterControl pour cela ou écrire vos propres programmes.
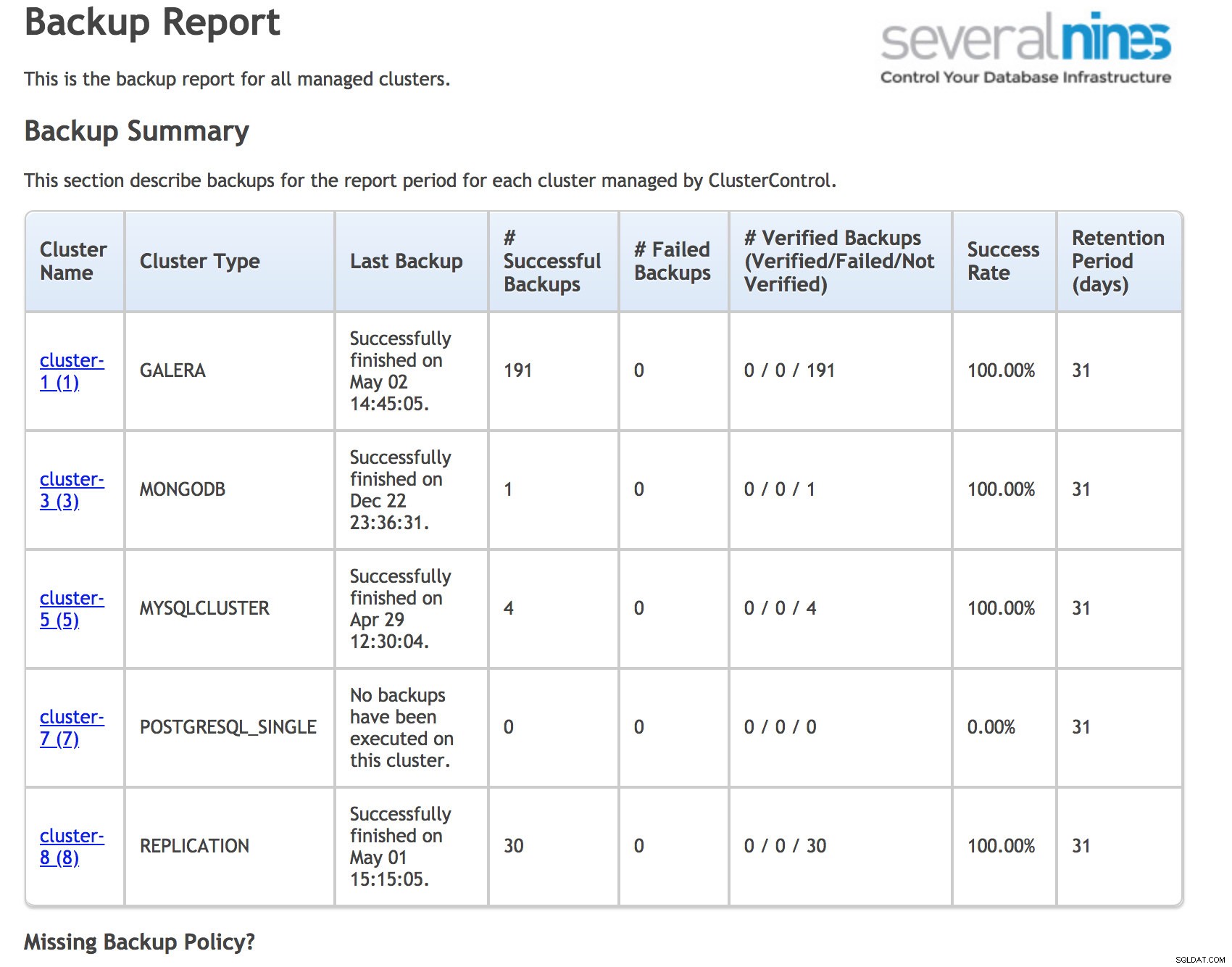 Rapport de sauvegarde opérationnelle de ClusterControl
Rapport de sauvegarde opérationnelle de ClusterControl Pour réduire l'impact d'une éventuelle corruption des données, vous devez toujours envisager des systèmes en cluster. Ce n'est qu'une question de temps lorsque la base de données plantera ou sera corrompue, il est donc bon d'avoir une copie vers laquelle vous pouvez basculer. Il peut s'agir d'une réplication Maître/Esclave. L'aspect important ici est d'avoir une récupération automatique sûre pour minimiser la complexité du basculement et minimiser le temps de récupération (RTO).
 Fonctionnalités de récupération automatique de ClusterControl
Fonctionnalités de récupération automatique de ClusterControl 


