Présentation
Tôt ou tard, tout système d'information se dote d'une base de données, souvent – plus d'une. Avec le temps, cette base de données rassemble beaucoup de données, de plusieurs Go à des dizaines de To. Pour comprendre comment les fonctionnalités fonctionneront avec l'augmentation des volumes de données, nous devons générer les données pour remplir cette base de données.

Tous les scripts présentés et implémentés s'exécuteront sur JobEmplDB base de données d'un service de recrutement. La réalisation de la base de données est disponible ici.
Approches du remplissage des données dans les bases de données pour les tests et le développement
Le développement et le test de la base de données impliquent deux approches principales pour remplir les données :
- Pour copier l'intégralité de la base de données depuis l'environnement de production avec les données personnelles et autres données sensibles modifiées. De cette façon, vous garantissez les données et effacez les données confidentielles.
- Pour générer des données synthétiques. Cela signifie générer des données de test similaires aux données réelles en termes d'apparence, de propriétés et d'interconnexions.
L'avantage de l'approche 1 est qu'elle rapproche les données et leur distribution selon différents critères de la base de données de production. Cela nous permet de tout analyser avec précision et, par conséquent, de tirer des conclusions et des pronostics en conséquence.
Cependant, cette approche ne vous permet pas d'augmenter la base de données elle-même plusieurs fois. Il devient problématique de prévoir les évolutions futures des fonctionnalités de l'ensemble du système d'information.
D'autre part, vous pouvez analyser des données désinfectées impersonnelles extraites de la base de données de production. En vous basant sur eux, vous pouvez définir comment générer les données de test qui ressembleraient aux données réelles par leur apparence, leurs propriétés et leurs interrelations. De cette façon, l'Approche 1 produit l'Approche 2.
Passons maintenant en revue en détail les deux approches du remplissage des données dans les bases de données pour les tests et le développement.
Copie et modification de données dans une base de données de production
Définissons d'abord l'algorithme général de copie et de modification des données depuis l'environnement de production.
L'algorithme général
L'algorithme général est le suivant :
- Créer une nouvelle base de données vide.
- Créez un schéma dans cette base de données nouvellement créée - le même système que celui de la base de données de production.
- Copiez les données nécessaires de la base de données de production dans la base de données nouvellement créée.
- Nettoyez et modifiez les données secrètes dans la nouvelle base de données.
- Effectuez une sauvegarde de la base de données nouvellement créée.
- Fournissez et restaurez la sauvegarde dans l'environnement nécessaire.
Cependant, l'algorithme devient plus compliqué après l'étape 5. Par exemple, l'étape 6 nécessite un environnement spécifique et protégé pour les tests préliminaires. Cette étape doit garantir que toutes les données sont impersonnelles et que les données secrètes sont modifiées.
Après cette étape, vous pouvez revenir à l'étape 5 pour la base de données testée dans l'environnement de non-production protégé. Ensuite, vous transmettez la sauvegarde testée aux environnements nécessaires pour la restaurer et l'utiliser pour le développement et les tests.
Nous avons présenté l'algorithme général de copie et de modification des données de la base de données de production. Décrivons comment l'implémenter.
Réalisation de l'algorithme général
Une nouvelle création de base de données vide
Vous pouvez créer une base de données vide à l'aide de la construction CREATE DATABASE comme ici.
La base de données est nommée JobEmplDB_Test . Il a trois groupes de fichiers :
- PRIMAIRE – c'est le groupe de fichiers principal par défaut. Il définit deux fichiers :JobEmplDB_Test1(path D:\DBData\JobEmplDB_Test1.mdf) , et JobEmplDB_Test2 (chemin D:\DBData\JobEmplDB_Test2.ndf) . La taille initiale de chaque fichier est de 64 Mo et l'étape de croissance est de 8 Mo pour chaque fichier.
- DBTableGroup – un groupe de fichiers personnalisé qui détermine deux fichiers :JobEmplDB_TestTableGroup1 (chemin D:\DBData\JobEmplDB_TestTableGroup1.ndf) et JobEmplDB_TestTableGroup2 (chemin D:\DBData\JobEmplDB_TestTableGroup2.ndf) . La taille initiale de chaque fichier est de 8 Go et l'étape de croissance est de 1 Go pour chaque fichier.
- DBIndexGroup – un groupe de fichiers personnalisé qui détermine deux fichiers :JobEmplDB_TestIndexGroup1 (chemin D:\DBData\JobEmplDB_TestIndexGroup1.ndf) , et JobEmplDB_TestIndexGroup2 (chemin D:\DBData\JobEmplDB_TestIndexGroup2.ndf) . La taille initiale est de 16 Go pour chaque fichier et l'étape de croissance est de 1 Go pour chaque fichier.
De plus, cette base de données comprend un journal des transactions :JobEmplDB_Testlog , chemin E:\DBLog\JobEmplDB_Testlog.ldf . La taille initiale du fichier est de 8 Go et l'étape de croissance est de 1 Go.
Copie du schéma et des données nécessaires de la base de données de production dans une nouvelle base de données
Pour copier le schéma et les données nécessaires de la base de données de production dans la nouvelle, vous pouvez utiliser plusieurs outils. Tout d'abord, c'est Visual Studio (SSDT). Ou, vous pouvez utiliser des utilitaires tiers comme :
- DbForge Schema Compare et DbForge Data Compare
- ApexSQL Diff et Apex Data Diff
- Outil de comparaison SQL et outil de comparaison de données SQL
Création de scripts pour les modifications de données
Exigences essentielles pour les scripts de modification des données
1. Il doit être impossible de restaurer les données réelles à l'aide de ce script.
Par exemple, l'inversion des lignes ne conviendra pas, car elle nous permet de restaurer les données réelles. Habituellement, la méthode consiste à remplacer chaque caractère ou octet par un caractère ou un octet pseudo-aléatoire. Il en va de même pour la date et l'heure.
2. La modification des données ne doit pas altérer la sélectivité de leurs valeurs.
Il ne fonctionnera pas d'affecter NULL au champ de la table. Au lieu de cela, vous devez vous assurer que les mêmes valeurs dans les données réelles resteront les mêmes dans les données modifiées. Par exemple, en données réelles, vous avez une valeur de 103785 trouvée 12 fois dans le tableau. Lorsque vous modifiez cette valeur dans les données modifiées, la nouvelle valeur doit rester 12 fois dans les mêmes champs de la table.
3. La taille et la longueur des valeurs ne doivent pas différer de manière significative dans les données modifiées. Par exemple, vous remplacez chaque octet ou caractère par un octet ou un caractère pseudo-aléatoire. La chaîne initiale reste la même en taille et en longueur.
4. Les interrelations dans les données ne doivent pas être rompues après les modifications. Il concerne les clés externes et tous les autres cas où vous faites référence aux données modifiées. Les données modifiées doivent rester dans les mêmes relations que les données réelles.
Mise en œuvre des scripts de modification des données
Passons maintenant en revue le cas particulier de la modification des données pour dépersonnaliser et masquer les informations secrètes. L'échantillon est la base de données de recrutement.
L'exemple de base de données comprend les données personnelles suivantes que vous devez dépersonnaliser :
- Nom et prénom ;
- Date de naissance ;
- La date de délivrance de la carte d'identité ;
- Le certificat d'accès à distance sous forme de séquence d'octets ;
- Les frais de service pour la promotion de CV.
Tout d'abord, nous allons vérifier des exemples simples pour chaque type de données modifiées :
- Changement de date et d'heure ;
- Changement de valeur numérique ;
- Modifier les séquences d'octets ;
- Modification des données de personnage.
Changement de date et d'heure
Vous pouvez obtenir une date et une heure aléatoires en utilisant le script suivant :
DECLARE @dt DATETIME;
SET @dt = CAST(CAST(@StartDate AS FLOAT) + (CAST(@FinishDate AS FLOAT) - CAST(@StartDate AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME);
Ici, @StartDate et @FinishDate sont les valeurs de début et de fin de la plage. Ils sont corrélés respectivement pour la génération pseudo-aléatoire de la date et de l'heure.
Pour générer ces données, vous utilisez les fonctions système RAND, CHECKSUM et NEWID.
UPDATE [dbo].[Employee]
SET [DocDate] = CAST(CAST(CAST(CAST([BirthDate] AS DATETIME) AS FLOAT) + (CAST(GETDATE() AS FLOAT) - CAST(CAST([BirthDate] AS DATETIME) AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME) AS DATE);
Le champ [DocDate] représente la date d'émission du document. Nous la remplaçons par une date pseudo-aléatoire, en gardant à l'esprit les plages de dates et leurs limites.
La limite « inférieure » est la date de naissance du candidat. Le bord "supérieur" est la date actuelle. Nous n'avons pas besoin de l'heure ici, donc la transformation du format de l'heure et de la date à la date nécessaire arrive à la fin. Vous pouvez obtenir des valeurs pseudo-aléatoires pour n'importe quelle partie de la date et de l'heure de la même manière.
Changement de valeur numérique
Vous pouvez obtenir un entier aléatoire à l'aide du script suivant :
DECLARE @Int INT;
SET @Int = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
@MinVal et @MaxVal sont les valeurs de début et de fin de la plage pour la génération de nombres pseudo-aléatoires. Nous le générons à l'aide des fonctions système RAND, CHECKSUM et NEWID.
UPDATE [dbo].[Employee]
SET [CountRequest] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
Le champ [CountRequest] représente le nombre de demandes que les entreprises font pour le CV de ce candidat.
De même, vous pouvez obtenir des valeurs pseudo-aléatoires pour n'importe quelle valeur numérique. Par exemple, regardez le nombre aléatoire de la génération de type décimal (18,2) :
DECLARE @Dec DECIMAL(18,2);
SET @Dec=CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Ainsi, vous pouvez mettre à jour les frais de service de promotion de CV de la manière suivante :
UPDATE [dbo].[Employee]
SET [PaymentAmount] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Modification des séquences d'octets
Vous pouvez obtenir une séquence d'octets aléatoire à l'aide du script suivant :
DECLARE @res VARBINARY(MAX);
SET @res = CRYPT_GEN_RANDOM(@Length, CAST(NEWID() AS VARBINARY(16)));
@Longueur représente la longueur de la séquence. Il définit le nombre d'octets renvoyés. Ici, @Length ne doit pas être supérieur à 16.
La génération se fait à l'aide des fonctions système CRYPT_GEN_RANDOM et NEWID.
Par exemple, vous pouvez mettre à jour le certificat d'accès à distance pour chaque candidat de la manière suivante :
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = CRYPT_GEN_RANDOM(CAST(LEN([RemoteAccessCertificate]) AS INT), CAST(NEWID() AS VARBINARY(16)));
Nous générons une séquence d'octets pseudo-aléatoire de la même longueur présente dans le champ [RemoteAccessCertificate] au moment du changement. Nous supposons que la longueur de la séquence d'octets ne dépasse pas 16.
De même, nous pouvons créer notre fonction qui renverra des séquences d'octets pseudo-aléatoires de n'importe quelle longueur. Il associera les résultats de la fonction système CRYPT_GEN_RANDOM à l'aide du simple opérateur d'addition « + ». Mais 16 octets suffisent généralement en pratique.
Faisons un exemple de fonction renvoyant la séquence d'octets pseudo-aléatoire de la longueur définie, où il sera possible de définir la longueur de plus de 16 octets. Pour cela, faites la présentation suivante :
CREATE VIEW [test].[GetNewID]
AS
SELECT NEWID() AS [NewID];
GO
Nous en avons besoin pour contourner la limitation nous interdisant d'utiliser NEWID dans la fonction.
De la même manière, créez la présentation suivante dans le même but :
CREATE VIEW [test].[GetRand]
AS
SELECT RAND(CHECKSUM((SELECT TOP(1) [NewID] FROM [test].[GetNewID]))) AS [Value];
GO
Créez une autre présentation :
CREATE VIEW [test].[GetRandVarbinary16]
AS
SELECT CRYPT_GEN_RANDOM(16, CAST((SELECT TOP(1) [NewID] FROM [test].[GetNewID]) AS VARBINARY(16))) AS [Value];
GO
Les définitions des trois fonctions sont ici. Et voici l'implémentation de la fonction qui renvoie une séquence d'octets pseudo-aléatoire de la longueur définie.
Tout d'abord, nous définissons si la fonction nécessaire est présente. Sinon, nous créons d'abord un poteau. Dans tous les cas, le code implique de modifier la définition de la fonction de manière appropriée. Au final, on ajoute la description de la fonction via les propriétés étendues. Plus de détails sur la documentation de la base de données sont dans cet article.
Pour mettre à jour le certificat d'accès à distance pour chaque candidat, vous pouvez procéder comme suit :
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = [test].[GetRandVarbinary](CAST(LEN([RemoteAccessCertificate]) AS INT));
Comme vous le voyez, il n'y a aucune limite à la longueur de la séquence d'octets ici.
Changement de données - Changement de données de caractère
Ici, nous prenons un exemple pour les alphabets anglais et russe, mais vous pouvez le faire pour n'importe quel autre alphabet. La seule condition est que ses caractères soient présents dans les types NCHAR.
Nous devons créer une fonction qui accepte la ligne, remplace chaque caractère par un caractère pseudo-aléatoire, puis rassemble le résultat et le renvoie.
Cependant, nous devons d'abord comprendre de quels personnages nous avons besoin. Pour cela, nous pouvons exécuter le script suivant :
DECLARE @tbl TABLE ([ValueInt] INT, [ValueNChar] NCHAR(1), [ValueChar] CHAR(1));
DECLARE @ind int=0;
DECLARE @count INT=65535;
WHILE(@count>=0)
BEGIN
INSERT INTO @tbl ([ValueInt], [ValueNChar], [ValueChar])
SELECT @ind, NCHAR(@ind), CHAR(@ind)
SET @ind+=1;
SET @count-=1;
END
SELECT *
INTO [test].[TblCharactersCode]
FROM @tbl;
Nous créons la table [test].[TblCharacterCode] qui comprend les champs suivants :
- ValueInt – la valeur numérique du caractère ;
- ValueNChar – le caractère de type NCHAR ;
- ValueChar – le caractère de type CHAR.
Reprenons le contenu de ce tableau. Nous avons besoin de la requête suivante :
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
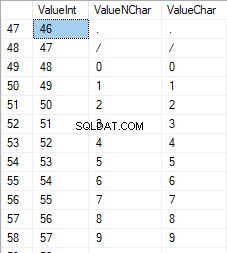
FROM [test].[TblCharactersCode];
Les nombres sont compris entre 48 et 57 :
Les caractères latins en majuscules sont compris entre 65 et 90 :
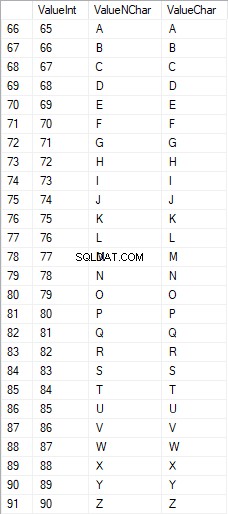
Les caractères latins dans les soins inférieurs sont compris entre 97 et 122 :
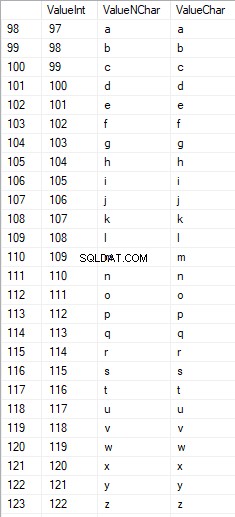
Les caractères russes en majuscules sont compris entre 1 040 et 1 071 :

Les caractères russes en minuscules sont compris entre 1 072 et 1 103 :


Et, caractères compris entre 58 et 64 :

Nous sélectionnons les caractères nécessaires et les plaçons dans la table [test].[SelectCharactersCode] de la manière suivante :
SELECT
[ValueInt]
,[ValueNChar]
,[ValueChar]
,CASE
WHEN ([ValueInt] BETWEEN 48 AND 57) THEN 1
ELSE 0
END AS [IsNumeral]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 1040 AND 1071)) THEN 1
ELSE 0
END AS [IsUpperCase]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 97 AND 122)) THEN 1
ELSE 0
END AS [IsLatin]
,CASE
WHEN (([ValueInt] BETWEEN 1040 AND 1071) OR
([ValueInt] BETWEEN 1072 AND 1103)) THEN 1
ELSE 0
END AS [IsRus]
,CASE
WHEN (([ValueInt] BETWEEN 33 AND 47) OR
([ValueInt] BETWEEN 58 AND 64)) THEN 1
ELSE 0
END AS [IsExtra]
INTO [test].[SelectCharactersCode]
FROM [test].[TblCharactersCode]
WHERE ([ValueInt] BETWEEN 48 AND 57)
OR ([ValueInt] BETWEEN 65 AND 90)
OR ([ValueInt] BETWEEN 97 AND 122)
OR ([ValueInt] BETWEEN 1040 AND 1071)
OR ([ValueInt] BETWEEN 1072 AND 1103)
OR ([ValueInt] BETWEEN 33 AND 47)
OR ([ValueInt] BETWEEN 58 AND 64);
Examinons maintenant le contenu de cette table à l'aide du script suivant :
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
,[IsNumeral]
,[IsUpperCase]
,[IsLatin]
,[IsRus]
,[IsExtra]
FROM [test].[SelectCharactersCode];
Nous recevons le résultat suivant :

De cette façon, nous avons le [test].[SelectCharactersCode] tableau, où :
- ValeurInt – la valeur numérique du caractère
- ValeurNChar – le caractère de type NCHAR
- ValueChar – le caractère de type CHAR
- EstNumérique – le critère d'un caractère étant un chiffre
- IsUpperCase – le critère d'un caractère en majuscule
- EstLatin – le critère d'un caractère étant un caractère latin;
- IsRus – le critère d'un caractère étant un caractère russe
- EstExtra – le critère d'un caractère étant un caractère supplémentaire
Maintenant, nous pouvons obtenir le code pour l'insertion des caractères nécessaires. Par exemple, voici comment procéder pour les caractères latins en minuscule :
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsLatin]=1;
Nous recevons le résultat suivant :

Il en est de même pour les caractères russes en minuscule :
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+COALESCE(''''+[ValueChar]+'''', 'NULL')+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsRus]=1;
Nous obtenons le résultat suivant :

Il en est de même pour les caractères :
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsNumeral]=1;
Le résultat est le suivant :

Nous avons donc des codes pour insérer séparément les données suivantes :
- Les caractères latins en minuscules.
- Les caractères russes en minuscules.
- Les chiffres.
Cela fonctionne pour les types NCHAR et CHAR.
De même, nous pouvons préparer un script d'insertion pour n'importe quel ensemble de caractères. De plus, chaque ensemble aura sa propre fonction de tabulation.
Pour être simple, nous implémentons la fonction de tabulation commune qui renverra l'ensemble de données nécessaire pour les données précédemment sélectionnées de la manière suivante :
SELECT
'SELECT ' + CAST([ValueInt] AS NVARCHAR(255)) + ' AS [ValueInt], '
+ '''' + [ValueNChar] + '''' + ' AS [ValueNChar], '
+ COALESCE('''' + [ValueChar] + '''', ‘NULL’) + ' AS [ValueChar], '
+ CAST([IsNumeral] AS NCHAR(1)) + ' AS [IsNumeral], ' +
+CAST([IsUpperCase] AS NCHAR(1)) + ' AS [IsUpperCase], ' +
+CAST([IsLatin] AS NCHAR(1)) + ' AS [IsLatin], ' +
+CAST([IsRus] AS NCHAR(1)) + ' AS [IsRus], ' +
+CAST([IsExtra] AS NCHAR(1)) + ' AS [IsExtra]' +
+' UNION ALL'
FROM [test].[SelectCharactersCode];
Le résultat final est le suivant :

Le script prêt est enveloppé dans la fonction de tabulation [test].[GetSelectCharacters].
Il est important de supprimer un UNION ALL supplémentaire à la fin du script généré, et dans le [ValueInt]=39, nous devons changer ”’ en ”” :
SELECT 39 AS [ValueInt], '''' AS [ValueNChar], '''' AS [ValueChar], 0 AS [IsNumeral], 0 AS [IsUpperCase], 0 AS [IsLatin], 0 AS [IsRus], 1 AS [IsExtra] UNION ALLCette fonction de tabulation renvoie l'ensemble de champs suivant :
- Nombre – le numéro de ligne dans l'ensemble de données retourné ;
- ValeurInt – la valeur numérique du caractère;
- ValeurNChar – le caractère de type NCHAR;
- ValueChar – le caractère de type CHAR;
- EstNumérique – le critère du caractère étant un chiffre;
- IsUpperCase – le critère définissant que le caractère est en majuscule;
- EstLatin – le critère définissant que le caractère est un caractère latin;
- IsRus – le critère définissant que le caractère est un caractère russe;
- EstExtra – le critère définissant que le caractère est un extra.
Pour l'entrée, vous disposez des paramètres suivants :
- @IsNumeral – s'il doit retourner les nombres ;
- @IsUpperCase :
- 0 – il ne doit renvoyer que les minuscules pour les lettres ;
- 1 - il ne doit renvoyer que les lettres majuscules ;
- NULL - il doit renvoyer des lettres dans tous les cas.
- @IsLatin – il doit renvoyer les caractères latins
- @IsRus – il doit renvoyer les caractères russes
- @IsExtra – il doit renvoyer des caractères supplémentaires.
Tous les drapeaux sont utilisés selon le OU logique. Par exemple, si vous avez besoin de renvoyer des chiffres et des caractères latins en minuscules, vous appelez la fonction de tabulation de la manière suivante :
Nous obtenons le résultat suivant :
declare
@IsNumeral BIT=1
,@IsUpperCase BIT=0
,@IsLatin BIT=1
,@IsRus BIT=0
,@IsExtra BIT=0;
SELECT *
FROM [test].[GetSelectCharacters](@IsNumeral, @IsUpperCase, @IsLatin, @IsRus, @IsExtra);
Nous obtenons le résultat suivant :

Nous implémentons la fonction [test].[GetRandString] qui remplacera la ligne par des caractères pseudo-aléatoires, en gardant la longueur initiale de la chaîne. Cette fonction doit inclure la possibilité d'utiliser uniquement les caractères qui sont des chiffres. Par exemple, cela peut être utile lorsque vous modifiez la série et le numéro de la carte d'identité.
Lorsque nous implémentons la fonction [test].[GetRandString], nous obtenons d'abord le jeu de caractères nécessaire pour générer une ligne pseudo-aléatoire de la longueur spécifiée dans le paramètre d'entrée @Length. Le reste des paramètres fonctionnent comme décrit ci-dessus.
Ensuite, nous mettons l'ensemble de données reçu dans la variable de tabulation @tbl . Cette table enregistre les champs [ID] - le numéro d'ordre dans la table de caractères résultante, et [Valeur] - la présentation du caractère dans le type NCHAR.
Après cela, dans un cycle, il génère un nombre pseudo-aléatoire compris entre 1 et la cardinalité des caractères @tbl reçus précédemment. Nous mettons ce numéro dans le [ID] de la variable de tabulation @tbl pour la recherche. Lorsque la recherche renvoie la ligne, nous prenons le caractère [Valeur] et le "collons" à la ligne résultante @res.
Lorsque le travail du cycle se termine, la ligne reçue revient via la variable @res.
Vous pouvez modifier à la fois le prénom et le nom du candidat de la manière suivante :
UPDATE [dbo].[Employee]
SET [FirstName] = [test].[GetRandString](LEN([FirstName])),
[LastName] = [test].[GetRandString](LEN([LastName]));
Ainsi, nous avons examiné l'implémentation de la fonction et son utilisation pour les types NCHAR et NVARCHAR. Nous pouvons faire la même chose facilement pour les types CHAR et VARCHAR.
Parfois, cependant, nous devons générer une ligne en fonction du jeu de caractères, et non des caractères alphabétiques ou des chiffres. De cette façon, nous devons d'abord utiliser la fonction multi-opérateur suivante [test].[GetListCharacters].
La fonction [test].[GetListCharacters] obtient les deux paramètres suivants pour l'entrée :
- @str – la ligne de caractères elle-même;
- @IsGroupUnique – il définit s'il doit regrouper des caractères uniques dans la ligne.
Avec le CTE récursif, la ligne d'entrée @str est transformée en table de caractères - @ListCharacters. Cette table contient les champs suivants :
- ID – le numéro d'ordre de la ligne dans la table de caractères résultante;
- Personnage – la présentation du personnage dans NCHAR(1)
- Compter – le nombre de répétitions du caractère dans la ligne (c'est toujours 1 si le paramètre @IsGroupUnique=0)
Prenons deux exemples d'utilisation de cette fonction pour mieux comprendre son fonctionnement :
- Transformation de la ligne en liste de caractères non uniques :
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 0);
Nous obtenons le résultat :

Cet exemple montre que la ligne est transformée en liste de caractères "telle quelle", sans la regrouper par l'unicité des caractères (le champ [Count] contient toujours 1).
- La transformation de la ligne en liste de caractères uniques
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 1);
Le résultat est le suivant :
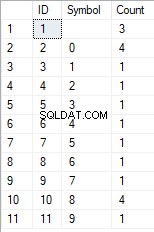
Cet exemple montre que la ligne est transformée en la liste des caractères regroupés par leur unicité. Le champ [Count] affiche le nombre de conclusions de chaque caractère dans la ligne de saisie.
En nous basant sur la fonction multi-opérateur [test].[GetListCharacters], nous créons une fonction scalaire [test].[GetRandString2].
La définition de la nouvelle fonction scalaire montre sa ressemblance avec la fonction scalaire [test].[GetRandString]. La seule différence est qu'il utilise la fonction multi-opérateur [test].[GetListCharacters] au lieu de la fonction de tabulation [test].[GetSelectCharacters].
Examinons ici deux exemples d'utilisation de la fonction scalaire implémentée :
Nous générons une ligne pseudo-aléatoire de 12 caractères à partir de la ligne d'entrée des caractères non regroupés par unicité :
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', DEFAULT);Le résultat est :
64017!!5!!!7
Le mot clé est DEFAULT. Il indique que la valeur par défaut définit le paramètre. Ici, c'est zéro (0).
Ou
Nous générons une ligne pseudo-aléatoire d'une longueur de 12 caractères à partir de la ligne d'entrée de caractères regroupés par unicité :
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', 1);Le résultat est :
35792 !428273
Mise en œuvre du script général pour le nettoyage des données et les modifications des données secrètes
Nous avons examiné des exemples simples pour chaque type de données modifiées :
- Modifier la date et l'heure ;
- Modifier la valeur numérique ;
- Modifier la séquence d'octets ;
- Modifier les données des personnages.
Cependant, ces exemples ne répondent pas aux critères 2 et 3 pour les scripts de modification de données :
- Critère 2 :la sélectivité des valeurs ne changera pas de manière significative dans les données modifiées. Vous ne pouvez pas utiliser NULL pour le champ de la table. Au lieu de cela, vous devez vous assurer que les mêmes valeurs de données réelles restent les mêmes dans les données modifiées. Par exemple, si les données réelles contiennent la valeur 103785 12 fois dans le champ d'une table susceptible d'être modifié, les données modifiées doivent inclure une valeur différente (modifiée) trouvée 12 fois dans le même champ de la table.
- Critère 3 :la longueur et la taille des valeurs ne doivent pas être modifiées de manière significative dans les données modifiées. Par exemple, vous remplacez chaque caractère/octet par un caractère/octet pseudo-aléatoire.
Ainsi, nous devons créer un script prenant en compte la sélectivité des valeurs dans les champs de la table.
Jetons un coup d'œil à notre base de données pour le service de recrutement. Comme on le voit, les données personnelles sont présentes dans le tableau des candidats uniquement [dbo].[Employee].
Supposons que le tableau inclut les champs suivants :
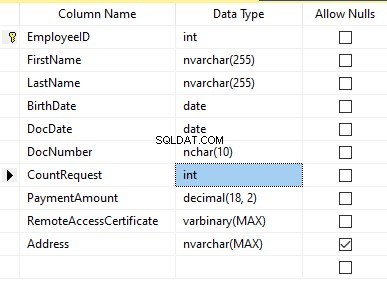
Description :
- Prénom – nom, ligne NVARCHAR(255)
- Nom de famille – nom de famille, ligne NVARCHAR(255)
- Date de naissance – date de naissance, DATE
- Numéro de document – le numéro de carte d'identité avec deux chiffres au début pour la série de passeports, et les sept chiffres suivants sont le numéro du document. Entre eux, nous avons un trait d'union comme ligne NCHAR(10).
- DocDate – la date de délivrance de la carte d'identité, DATE
- CountRequest – le nombre de demandes pour ce candidat lors de la recherche de CV, l'entier INT
- PaymentAmount – les frais de service de promotion de CV reçus, le nombre décimal (18,2)
- Certificat d'accès à distance – le certificat d'accès à distance, séquence d'octets VARBINARY
- Adresse – l'adresse domiciliaire ou l'adresse d'immatriculation, ligne NVARCHAR(MAX)
Ensuite, pour conserver la sélectivité initiale, nous devons implémenter l'algorithme suivant :
- Extraire toutes les valeurs uniques pour chaque champ et conserver les résultats dans des tables temporaires ou des variables de tabulation ;
- Générez une valeur pseudo-aléatoire pour chaque valeur unique. Cette valeur pseudo-aléatoire ne doit pas différer significativement en longueur et en taille de la valeur d'origine. Enregistrez le résultat au même endroit où nous avons enregistré les résultats du point 1. Chaque valeur nouvellement générée doit avoir une valeur actuelle unique corrélée.
- Remplacez toutes les valeurs du tableau par les nouvelles valeurs du point 2.
Au début, nous dépersonnalisons les noms et prénoms des candidats. Nous supposons que les noms et prénoms sont toujours présents et qu'ils ne comportent pas moins de deux caractères dans chaque champ.
Tout d'abord, nous sélectionnons des noms uniques. Ensuite, il génère une ligne pseudo-aléatoire pour chaque nom. La longueur du nom reste la même; le premier caractère est en majuscule et les autres caractères sont en minuscules. Nous utilisons la fonction scalaire [test].[GetRandString] créée précédemment pour générer une ligne pseudo-aléatoire de la longueur spécifique selon les critères de caractères définis.
Ensuite, nous mettons à jour les noms dans le tableau des candidats en fonction de leurs valeurs uniques. Il en est de même pour les noms de famille.
Nous dépersonnalisons le champ DocNumber. C'est le numéro de la carte d'identité (passeport). Les deux premiers caractères représentent la série du document et les sept derniers chiffres sont le numéro du document. Le trait d'union est entre eux. Ensuite, nous effectuons l'opération de désinfection.
Nous collectons tous les numéros de documents uniques et générons une ligne pseudo-aléatoire pour chacun. Le format de la ligne est "XX-XXXXXXX", où X est le chiffre compris entre 0 et 9. Ici, nous utilisons la fonction scalaire [test].[GetRandString] créée précédemment pour générer une ligne pseudo-aléatoire de la longueur spécifiée en fonction de le jeu de paramètres des personnages.
Après cela, le champ [DocNumber] est mis à jour dans la table des candidats [dbo].[Employee].
We depersonalize the DocDate field (the ID-card issue date) and the BirthDate field (the candidate’s date of birth).
First, we select all the unique pairs made of “date of birth &date of the ID-card issue.” For each such pair, we create a pseudorandom date for the date of birth. The pseudorandom date of the ID-card issue is made according to that “date of birth” – the date of the document’s issue must not be earlier than the date of birth.
After that, these data are updated in the respective fields of the candidates’ table [dbo].[Employee].
And, we update the remaining fields of the table.
The CountRequest value stands for the number of requests made for that candidate by companies during the resume search.
The PaymentAmount is the final amount of the resume promotion service fee paid. We calculate these numbers similarly to the previous fields.
Note that it generates a pseudorandom integer for the first case and a pseudorandom decimal for the second case. In both cases, the pseudorandom number generation occurs in the range of “two times less than original” to “two times more than original.” The selectivity of values in the fields is not changed too much.
After that, it writes the values into the fields of the candidates’ table [dbo].[Employee].
Further, we collect unique values of the RemoteAccessCertificate field for the remote access certificate. We generate a pseudorandom byte sequence for each such value. The length of the sequence must be the same as the original. Here, we use the previously created [test].[GetRandVarbinary] scalar function to generate the pseudorandom byte sequence of the specified length.
Then recording into the respective field [RemoteAccessCertificate] of the [dbo].[Employee] candidates’ table takes place.
The last step is the collection of the unique addresses from the [Address] field. For each value, we generate a pseudorandom line of the same length as the original. Note that if it was NULL originally, it must be NULL in the generated field. It allows you to keep NULL and don’t replace it with an empty line. It minimizes the selectivity values’ mismatch in this field between the production database and the altered data.
We use the previously created [test].[GetRandString] scalar function to generate the pseudorandom line of the specified length according to the characters’ parameters defined.
It then records the data into the respective [Address] field of the candidates’ table [dbo].[Employee].
This way, we get the full script for depersonalization and altering of the confidential data.
Finally, we get the database with altered personal and confidential data. The algorithms we used make it impossible to restore the original data from the altered data. Also, the values’ selectivity, length, and size aren’t changed significantly. So, the three criteria for the personal and secret data altering scripts are ensured.
We won’t review the criterion 4 separately here. Our database contains all the data subject to change in one candidates’ table [dbo].[Employee]. The data conformity is needed within this table only. Thus, criterion 4 is also here. However, we need to remember this criterion 4 claiming that all interrelations must remain the same in the altered data.
We often see other conditions for personal and confidential data altering algorithms, but we won’t review them here. Besides, the four criteria described above are always present. In many cases, it is enough to estimate the functionality of the algorithm suitable to use it.
Now, we need to make a backup of the created database, check it by restoring on another instance, and transfer that copy into the necessary environment for development and testing. For this, we examine the full database backup creation.
Full database backup creation
We can make a database backup with construction BACKUP DATABASE as in our example.
Make a compressed full backup of the database JobEmplDB_Test. The checksum calculation takes place in the file E:\Backup\JobEmplDB_Test.bak. Further, we check the backup created.
Then, we check the backup created by restoring the database for it. Let’s examine the database restoring.
Restoring the database
You can restore the database with the help of RESTORE DATABASE construction in the following way:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the JobEmplDB_Test database of the E:\Backup\JobEmplDB_Test.bak backup. The files will be overwritten, and the data file will be transferred into the file E:\DBData\JobEmplDB.mdf , while the transactions log file will be moved into F:\DBLog\JobEmplDB_log.ldf .
After we successfully check how the database is restored from the backup, we forward the backup to the development and testing environments. It will be restored again with the same method as described above.
We’ve examined the first approach to the data populating into the database for testing and development. This approach implies copying and altering the data from the production database. Now, we’ll examine the second approach – the synthetic data generation.
Synthetic data generation
The General algorithm for the synthetic data generation is following:
- Make a new empty database or clear a previously created database by purging all data.
- Create or renew a scheme in the newly created database – the same as that of the production databases.
- Copy of renew guidelines and regulations from the production database and transfer them into the new database.
- Generate synthetic data into the necessary tables of the new database.
- Make a backup of a new database.
- Deliver and restore the new backup in the necessary environment.
We already have the JobEmplDB_Test database to practice, and we have reviewed the means of creating a schema in the new database. Let’s focus on the tasks that are specific to this approach.
Clean up the database with the data purge
To clear the database off all its data, we need to do the following:
- Keep the definitions of all external keys.
- Disable all limitations and triggers.
- Delete all external keys.
- Clear the tables using the TRUNCATE construction.
- Restore all the external keys deleted in point 3.
- Enable all the limitations disabled in point 2.
You can save the definitions of all external keys with the following script:
1. The external keys’ definitions are saved in the tabulation variable @tbl_create_FK
2. You can disable the limitations and triggers with the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? DISABLE TRIGGER ALL";
To enable the limitations and triggers, you can use the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? ENABLE TRIGGER ALL";
Here, we use the saved procedure sp_MSforeachtable that applies the construction to all the database’s tables.
3. To delete external keys, use the special script. Here, we receive the information about the external keys through the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system presentation. We delete external keys through the cursor, one by one, using the formed dynamic script T-SQL, transferring the request into the system saved procedure sp_executesql .
4. To clear the tables with the TRUNCATE construction, use the dedicated script. The script works in the same way as above, but it receives the data for tables, and then it clears the tables one by one through the cursor, using the TRUNCATE construction.
5. Restoring the external keys is possible with the below script (earlier, we saved the external keys’ definitions in the tabulation variable @tbl_create_FK):
DECLARE @tsql NVARCHAR(4000);
DECLARE FK_Create CURSOR LOCAL FOR SELECT
[Script]
FROM @tbl_create_FK;
OPEN FK_Create;
FETCH NEXT FROM FK_Create INTO @tsql;
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
FETCH NEXT FROM FK_Create INTO @tsql;
END
CLOSE FK_Create;
DEALLOCATE FK_Create;
The script works in the same way as the two other scripts we mentioned above. But it restores the external keys’ definitions through the cursor, one for each iteration.
A particular case of data purging in the database is the current script. To get this output, we need the below construction in the scripts:
EXEC sp_executesql @tsql = @tsql;Before this construction, or instead of it, we need to write the generated construction output. It is necessary to call it manually or via the dynamic T-SQL query. We do it via the system saved procedure sp_executesql.
Instead of the below code fragment in all cases:
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
...
We write:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
EXEC sp_executesql @tsql = @tsql;
...
Or:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
...
The first case implies both the output of constructions and their execution. The second case if for the output only – it is helpful for the scripts’ debugging.
Thus, we get the general database cleaning script.
Copy guidelines and references from the production database to the new one
Here you can use the T-SQL scripts. Our example database of the recruitment service includes 5 guidelines:
- [dbo].[Company] – companies
- [dbo].[Skill] – skills
- [dbo].[Position] – positions (occupation)
- [dbo].[Project] – projects
- [dbo].[ProjectSkill] – project and skills’ correlations
The “skills” table [dbo].[Skill] serves to show how to make a script for the data insertion from the production database into the test database.
We form the following script:
SELECT 'SELECT '+CAST([SkillID] AS NVARCHAR(255))+' AS [SkillID], '+''''+[SkillName]+''''+' AS [SkillName] UNION ALL'
FROM [dbo].[Skill]
ORDER BY [SkillID];
We execute it in a copy of the production database that is usually available in read-only mode. It is a replica of the production database.
The result is:
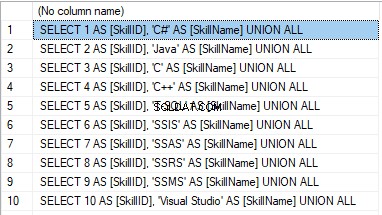
Now, wrap the result up into the script for the data adding as here. We have a script for the skills’ guideline compilation. The scripts for other guidelines are made in the same way.
However, it is much easier to copy the guidelines’ data through the data export and import in SSMS. Or, you can use the data import and export wizard.
Generate synthetic data
We’ve determined the pseudorandom values’ generation for lines, numbers, and byte sequences. It took place when we examined the implementation of the data sanitization and the confidential data altering algorithms for approach 1. Those implemented functions and scripts are also used for the synthetic data generation.
The recruitment service database requires us to fill the synthetic data in two tables only:
- [dbo].[Employee] – candidates
- [dbo].[JobHistory] – a candidate’s work history (experience), the resume itself
We can fill the candidates’ table [dbo].[Employee] with synthetic data using this script.
At the beginning of the script, we set the following parameters:
- @count – the number of lines to be generated
- @LengthFirstName – the name’s length
- @LengthLastName – the last name’s length
- @StartBirthDate – the lower limit of the date for the date of birth
- @FinishBirthDate – the upper limit of the date for the date of birth
- @StartCountRequest – the lower limit for the field [CountRequest]
- @FinishCountRequest – the upper limit for the field [CountRequest]
- @StartPaymentAmount – the lower limit for the field [PaymentAmount]
- @FinishPaymentAmount – the upper limit for the field [PaymentAmount]
- @LengthRemoteAccessCertificate – the byte sequence’s length for the certificate
- @LengthAddress – the length for the field [Address]
- @count_get_unique_DocNumber – the number of attempts to generate the unique document’s number [DocNumber]
The script complies with the uniqueness of the [DocNumber] field’s value.
Now, let’s fill the [dbo].[JobHistory] table with synthetic data as follows.
The start date of work [StartDate] is later than the issuing date of the candidate’s document [DocDate]. The end date of work [FinishDate] is later than the start date of work [StartDate].
It is important to note that the current script is simplified, as it does not deal with parameters of the generated data selectivity configuration.
Make a full database backup
We can make a database backup with the construction BACKUP DATABASE, using our script.
We create a full compressed backup of the database JobEmplDB_Test. The checksum is calculated into the file E:\Backup\JobEmplDB_Test.bak. It also ensures further testing of the backup.
Let’s check the backup by restoring the database from it. We need to examine the database restoring then.
Restore the database
You can restore the database with the help of the RESTORE DATABASE construction, as shown below:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the database JobEmplDB_Test from the backup E:\Backup\JobEmplDB_Test.bak. The files are overwritten, and the data file is transferred to the file E:\DBData\JobEmplDB.mdf. The transaction log file is transferred to file F:\DBLog\JobEmplDB_log.ldf.
After checking the database restoring from the backup successfully, we transfer the backup to the necessary environments. It will be used for testing and development, and further deployment through the database restoring, as described above.
This way, we’ve examined the second approach to filling the database in with data for testing and development purposes. It is the synthetic data generation approach.
Data generation tools (for external resources)
When we have a job to fill in the database with data for testing and development purposes, it can be much faster and easier with the help of specialized tools. Let’s review the most popular and powerful data generation tools and explore their practical usage.
Full list of tools
DATPROF
IRI RowGen
Data Generator for SQL Server
Redgate SQL Data Generator
DTM Data Generator
Datanamic Data Generator MultiDB
Now, let’s examine one of these tools more precisely.
An overview of the employees’ generation by the Data Generator for SQL Server
The Data Generator for SQL Server utility is embedded in SSMS, and also it is a part of dbForge Studio. We reviewed this utility here. Let’s now examine how it works for synthetic data generation. As examples, we use the [dbo].[Employee] and the [dbo].[JobHistory] tables.
This generator can quickly generate first and last names of candidates for the [FirstName] and [LastName] fields respectively:
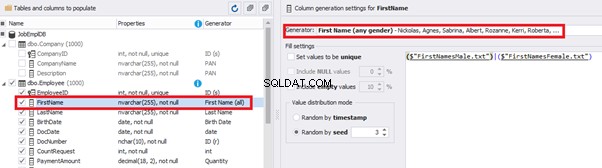
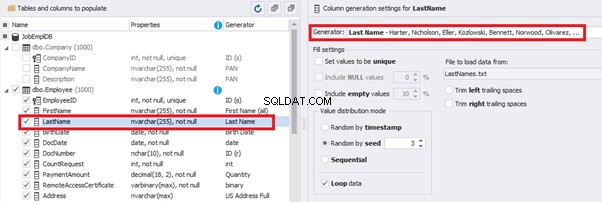
Note that FirstName requires choosing the “First Name” value in the “Generator” section. For LastName, you need to select the “Last Name” value from the “Generator” section.
It is important to note that the generator automatically determines which generation type it needs to apply to every field. The settings above were set by the generator itself, without manual correction.
You can configure distribution of values for the date of birth [BirthDate]:
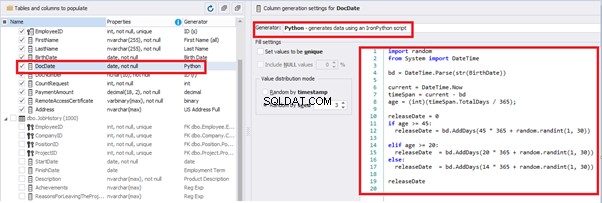
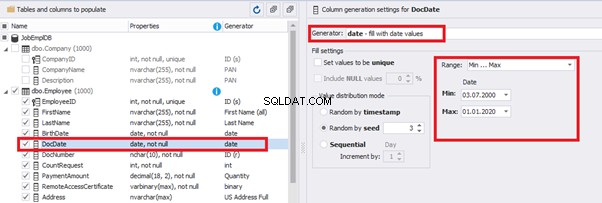
Set the distribution for the document’s date of issue [DocDate] through the Phyton generator using the below script:
import random
from System import DateTime
# receive the value from the Birthday field
bd = DateTime.Parse(str(BirthDate))
# receive the current date
current = DateTime.Now
# calculate the age in years
timeSpan = current - bd
age = (int)(timeSpan.TotalDays / 365);
# passport’s date of issue
releaseDate = 0
if age >= 45:
releaseDate = bd.AddDays(45 * 365 + random.randint(1, 30))
# randomize the issue during the month
elif age >= 20:
releaseDate = bd.AddDays(20 * 365 + random.randint(1, 30))
# randomize the issue during the month
else:
releaseDate = bd.AddDays(14 * 365 + random.randint(1, 30))
# randomize the issue during the month
releaseDateThis way, the [DocDate] configuration will look as follows:
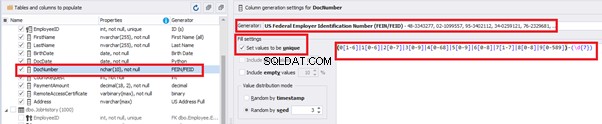
For the document’s number [DocNumber], we can select the necessary type of unique data generation, and edit the generated data format, if needed:
E.g., instead of the format
(0[1-6]|1[0-6]|2[0-7]|3[0-9]|4[0-68]|5[0-9]|6[0-8]|7[1-7]|8[0-8]|9[0-589])-(\d{7})We can set the following format:
(\d{2})-(\d{7})This format means that the line will be generated in format XX-XXXXXXX (X – is a digit in the range of 0 to 9).
We set up the generator for [CountRequest] and [PaymentAmount] fields in the same way, according to the generated data type:
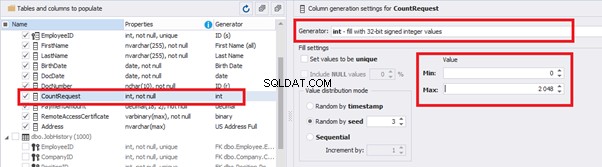
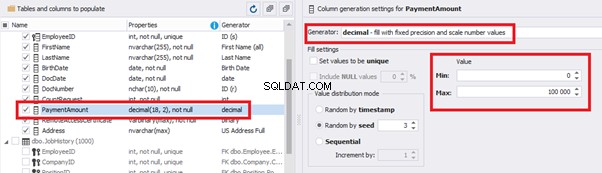
In the first case, we set the values’ range of 0 to 2048 for [CountRequest]. In the second case, it is the range of 0 to 100000 for [PaymentAmount].
We configure generation for [RemoteAccessCertificate] and [Address] fields in the same way:
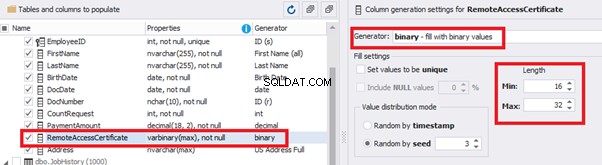
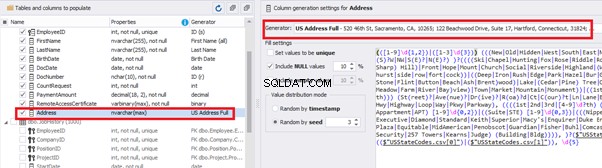
In the first case, we limit the byte sequence [RemoteAccessCertificate] with the range of lengths of 16 to 32. In the second case, we select values for [Address] as real addresses. It makes the generated values looking like the real ones.
This way, we’ve configured the synthetic data generation settings for the candidates’ table [dbo].[Employee]. Let’s now set up the synthetic data generation for the [dbo].[JobHistory] table.
We set it to take the data for the [EmployeeID] field from the candidates’ table [dbo].[Employee] in the following way:
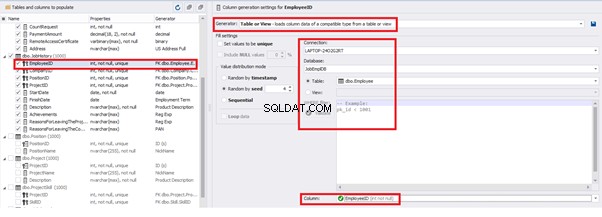
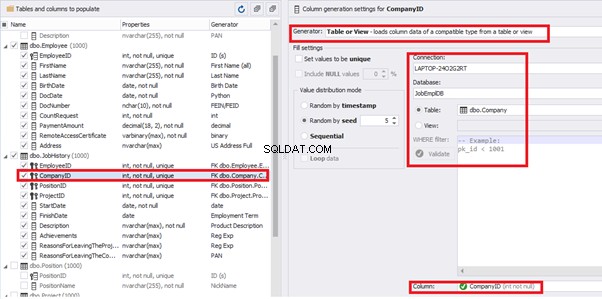
We select the generator’s type from the table or presentation. We then define the sample of MS SQL Server, the database, and the table to take the data from. We can also configure filters in the “WHERE filter” section, and select the [EmployeeID] field.
Here we suppose that we generate the “employees” first, and then we generate the data for the [dbo].[JobHistory] table, basing on the filled [dbo].[Employee] reference.
However, if we need to generate the data for both [dbo].[Employee] and [dbo].[JobHistory] at the same time, we need to select “Foreign Key (manually assigned) – references a column from the parent table,” referring to the [dbo].[Employee].[EmployeeID] column:
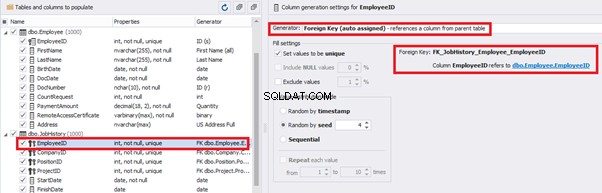
Similarly, we set up the data generation for the following fields.
[CompanyID] – from [dbo].[Company], the “companies” table:
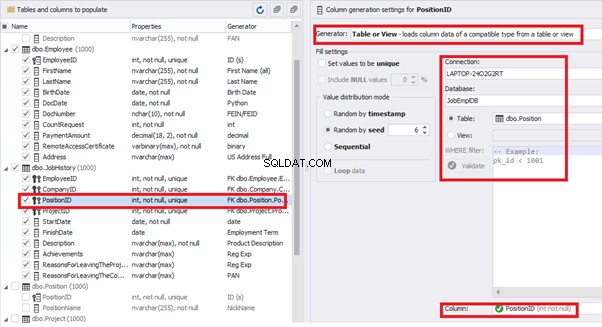
[PositionID] – from the table of positions [dbo].[Position]:
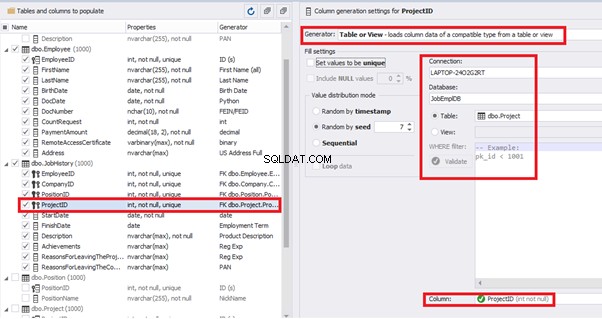
[ProjectID] – from the table of projects [dbo].[Project]:
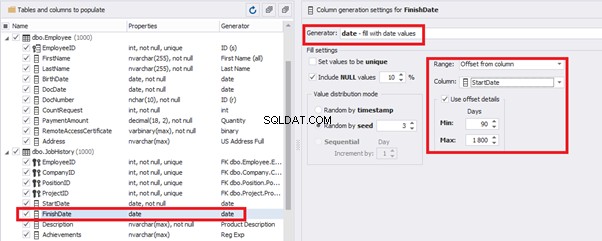
The tool cannot link the columns from different tables and shift them in some way. However, the generator can shift the date within one table – the “date” generator – fill with date values with Range – Offset from the column. Also, it can use data from a different table, but without any transformation (Table or View, SQL query, Foreign key generators).
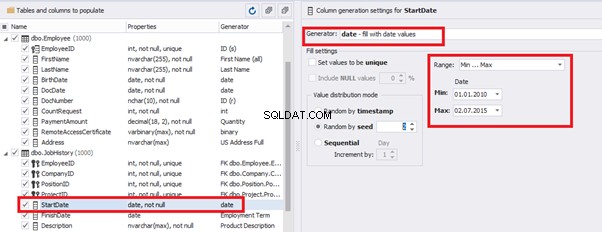
That’s why we resolve the dates’ problem (BirthDate
E.g., we limit the BirthDate with the 40-50 years’ interval. Then, we restrict the DocDate with 20-40 years’ interval. The StartDate is, respectively, limited with 25-35 years’ interval, and we set up the FinishDate with the offset from StartDate.
We set up the date of birth:
Set up the date of the document’s issue
Then, the StartDate will match the age from 35 to 45:
The simple offset generator sets FinishDate:
The result is, a person has worked for three months till the current date.
Also, to configure the date of the working end, we can use a small Python script:
This way, we receive the below configuration for the dates of work end [FinishDate] data generation:
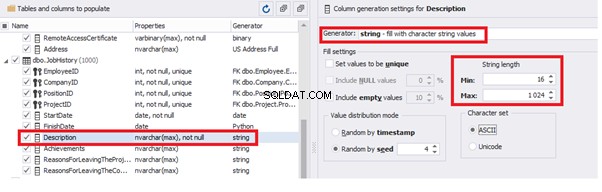
Similarly, we fill in the rest of fields. We set the generator type – string, and set the range for generated lines’ lengths:
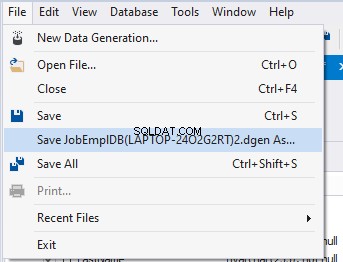
Also, you can save the data generation project as dgen-file consisting of:
We can save all these settings:it is enough to keep the project’s file and work with the database further, using that file:
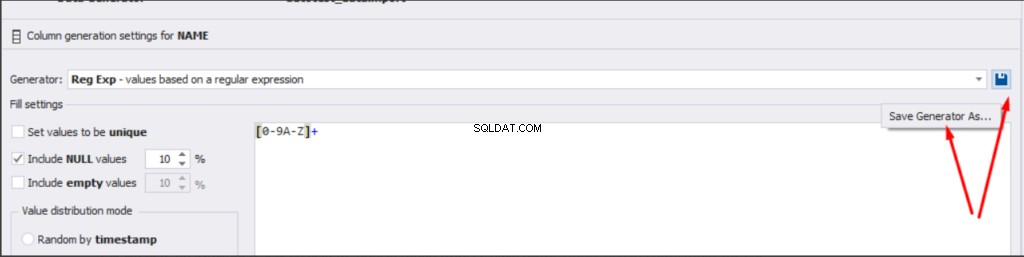
There is also the possibility to both save the new generators from scratch and save the custom settings in a new generator:
Thus, we’ve configured the synthetic data generation settings used for the jobs’ history table [dbo].[JobHistory].
We have examined two approaches to filling the data in the database for testing and development:
We’ve defied the objects for each approach and each script implementation. These objects are here. We’ve also provided scripts for changing the data from the production database and synthetic data generation. An example is the database of recruitment services. In the end, we’ve examined popular data generation tools and explored one of these tools in detail.
SQL SERVER – How to Disable and Enable All Constraint for Table and Database 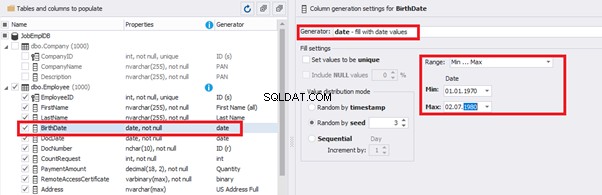
import random
from System import DateTime
bd = DateTime.Parse(str(StartDate))
releaseDate = bd.AddDays(random.randint(1, 30))
releaseDate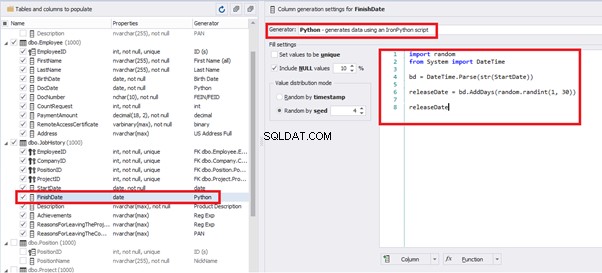
Conclusion
References
Microsoft TechNet Wiki
Top 10 Best Test Data Generation Tools In 2020
SQL Server Documentation