Construire une haute disponibilité, une étape à la fois
En matière d'infrastructure de base de données, nous en voulons tous. Nous nous efforçons tous de créer une configuration hautement disponible. La redondance est la clé. Nous commençons à implémenter la redondance au niveau le plus bas et continuons vers le haut de la pile. Cela commence par le matériel - blocs d'alimentation redondants, refroidissement redondant, disques remplaçables à chaud. Couche réseau - plusieurs cartes réseau liées ensemble et connectées à différents commutateurs utilisant des routeurs redondants. Pour le stockage nous utilisons des disques mis en RAID, ce qui donne de meilleures performances mais aussi de la redondance. Ensuite, au niveau logiciel, nous utilisons des technologies de clustering :plusieurs nœuds de base de données travaillant ensemble pour implémenter la redondance :MySQL Cluster, Galera Cluster.
Tout cela ne sert à rien si vous avez tout dans un seul centre de données :lorsqu'un centre de données tombe en panne, ou qu'une partie des services (mais importants) se déconnecte, ou même si vous perdez la connectivité au centre de données, votre service tombera en panne - quelle que soit la quantité de redondance dans les niveaux inférieurs. Et oui, ces choses arrivent.
- L'interruption du service S3 a fait des ravages dans la région USA-Est-1 en février 2017
- Interruption des services EC2 et RDS dans la région USA-Est en avril 2011
- EC2, EBS et RDS ont été interrompus dans la région UE-Ouest en août 2011
- Une panne de courant a fait tomber Rackspace Texas DC en juin 2009
- Une défaillance de l'UPS a entraîné la mise hors ligne de centaines de serveurs dans Rackspace London DC en janvier 2010
Ce n'est en aucun cas une liste complète des échecs, c'est juste le résultat d'une recherche rapide sur Google. Ceux-ci servent d'exemples que les choses peuvent mal tourner si vous mettez tous vos œufs dans le même panier. Un autre exemple serait l'ouragan Sandy, qui a provoqué un énorme exode de données de l'US-East vers les DC de l'US-West - à ce moment-là, vous pouviez difficilement créer des instances dans l'US-West alors que tout le monde se précipitait pour déplacer son infrastructure vers l'autre côte dans l'attente que North Virginia DC sera sérieusement affecté par la météo.
Ainsi, les configurations multi-centres de données sont indispensables si vous souhaitez créer un environnement à haute disponibilité. Dans cet article de blog, nous expliquerons comment créer une telle infrastructure à l'aide de Galera Cluster pour MySQL/MariaDB.
Concepts Galera
Avant d'examiner des solutions particulières, passons un peu de temps à expliquer deux concepts qui sont très importants dans les configurations Galera multi-DC hautement disponibles.
Quorum
La haute disponibilité nécessite des ressources - à savoir, vous avez besoin d'un certain nombre de nœuds dans le cluster pour le rendre hautement disponible. Un cluster peut tolérer la perte de certains de ses membres, mais seulement dans une certaine mesure. Au-delà d'un certain taux d'échec, vous pourriez envisager un scénario de cerveau divisé.
Prenons un exemple avec une configuration à 2 nœuds. Si l'un des nœuds tombe en panne, comment l'autre peut-il savoir que son homologue est tombé en panne et qu'il ne s'agit pas d'une panne de réseau ? Dans ce cas, l'autre nœud pourrait tout aussi bien être opérationnel et servir le trafic. Il n'y a pas de bonne façon de gérer un tel cas… C'est pourquoi la tolérance aux pannes commence généralement à partir de trois nœuds. Galera utilise un calcul de quorum pour déterminer si le cluster peut gérer le trafic en toute sécurité ou s'il doit cesser ses opérations. Après un échec, tous les nœuds restants tentent de se connecter les uns aux autres et de déterminer combien d'entre eux sont actifs. Il est ensuite comparé à l'état précédent du cluster, et tant que plus de 50 % des nœuds sont actifs, le cluster peut continuer à fonctionner.
Il en résulte ce qui suit :
cluster à 2 nœuds - aucune tolérance aux pannes
cluster à 3 nœuds :jusqu'à 1 crash
cluster à 4 nœuds :jusqu'à 1 crash (si deux nœuds devaient planter, seulement 50 % du cluster serait disponible, vous avez besoin de plus de 50 % de nœuds pour survivre)
Groupe de 5 nœuds - jusqu'à 2 plantages
Groupe de 6 nœuds - jusqu'à 2 plantages
Vous voyez probablement le modèle - vous voulez que votre cluster ait un nombre impair de nœuds - en termes de haute disponibilité, il est inutile de passer de 5 à 6 nœuds dans le cluster. Si vous voulez une meilleure tolérance aux pannes, vous devriez opter pour 7 nœuds.
Segments
En règle générale, dans un cluster Galera, toutes les communications suivent le modèle tout à tous. Chaque nœud communique avec tous les autres nœuds du cluster.
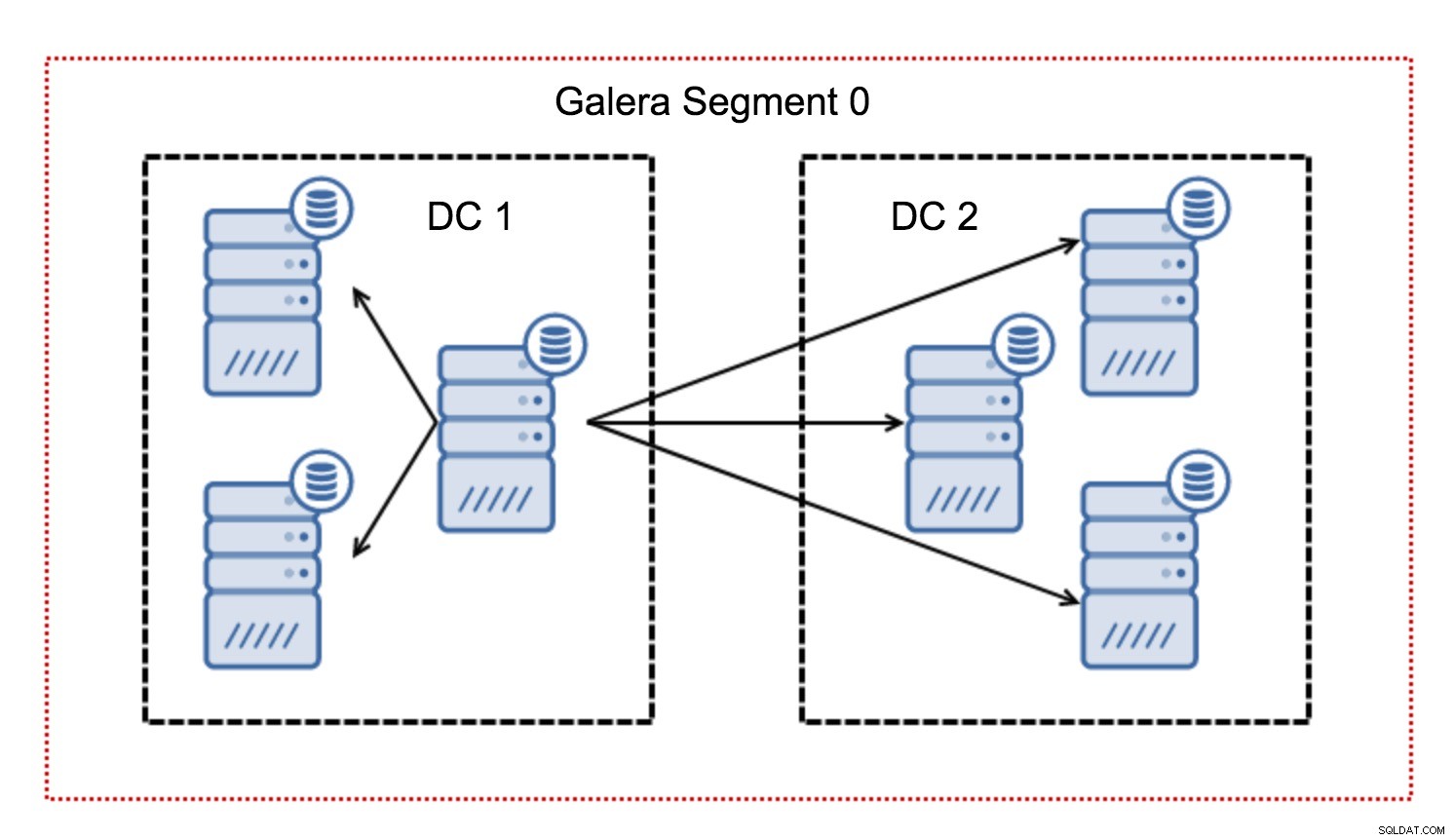
Comme vous le savez peut-être, chaque jeu d'écriture dans Galera doit être certifié par tous les nœuds du cluster. Par conséquent, chaque écriture qui s'est produite sur un nœud doit être transférée vers tous les nœuds du cluster. Cela fonctionne bien dans un environnement à faible latence. Mais si nous parlons de configurations multi-DC, nous devons prendre en compte une latence beaucoup plus élevée que dans un réseau local. Pour le rendre plus supportable dans les clusters s'étendant sur des réseaux étendus, Galera a introduit des segments.
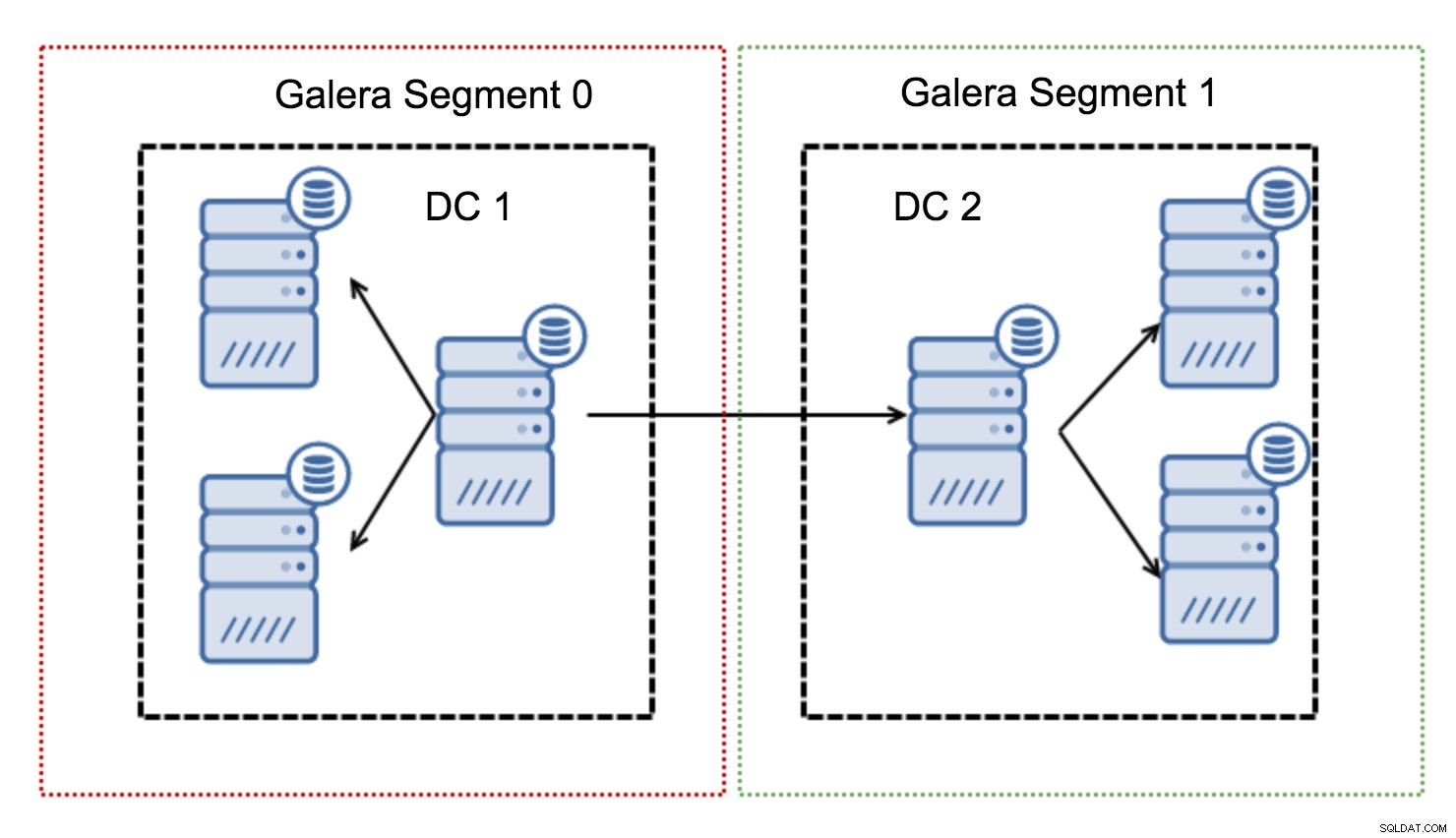
Ils fonctionnent en contenant le trafic Galera dans un groupe de nœuds (segment). Tous les nœuds d'un même segment agissent comme s'ils se trouvaient dans un réseau local - ils supposent une communication un à tous. Pour le trafic inter-segments, les choses sont différentes - dans chacun des segments, un nœud "relais" est choisi, tout le trafic inter-segments passe par ces nœuds. Lorsqu'un nœud relais tombe en panne, un autre nœud est élu. Cela ne réduit pas beaucoup la latence - après tout, la latence WAN restera la même, que vous établissiez une connexion à un hôte distant ou à plusieurs hôtes distants, mais étant donné que les liaisons WAN ont tendance à être limitées en bande passante et qu'il peut y avoir un charge pour la quantité de données transférées, une telle approche vous permet de limiter la quantité de données échangées entre les segments. Une autre option permettant de gagner du temps et de l'argent est le fait que les nœuds du même segment sont prioritaires lorsqu'un donneur est nécessaire - encore une fois, cela limite la quantité de données transférées sur le WAN et, très probablement, accélère presque toujours SST en tant que réseau local. sera plus rapide qu'une liaison WAN.
Maintenant que nous avons éliminé certains de ces concepts, examinons d'autres aspects importants des configurations multi-DC pour le cluster Galera.
Problèmes auxquels vous êtes sur le point de faire face
Lorsque vous travaillez dans des environnements s'étendant sur le WAN, vous devez tenir compte de quelques problèmes lors de la conception de votre environnement.
Calcul du quorum
Dans la section précédente, nous avons décrit à quoi ressemble un calcul de quorum dans le cluster Galera - en bref, vous voulez avoir un nombre impair de nœuds pour maximiser la capacité de survie. Tout cela est toujours vrai dans les configurations multi-DC, mais certains éléments supplémentaires sont ajoutés au mélange. Tout d'abord, vous devez décider si vous souhaitez que Galera gère automatiquement une panne de centre de données. Cela déterminera le nombre de centres de données que vous allez utiliser. Imaginons deux DC - si vous divisez vos nœuds 50% - 50%, si un centre de données tombe en panne, le second n'a pas 50% + 1 nœuds pour maintenir son état "primaire". Si vous divisez vos nœuds de manière inégale, en utilisant la majorité d'entre eux dans le centre de données "principal", lorsque ce centre de données tombe en panne, le contrôleur de domaine "de secours" n'aura pas 50 % + 1 nœuds pour former un quorum. Vous pouvez attribuer des poids différents aux nœuds, mais le résultat sera exactement le même - il n'y a aucun moyen de basculer automatiquement entre deux DC sans intervention manuelle. Pour implémenter le basculement automatisé, vous avez besoin de plus de deux contrôleurs de domaine. Encore une fois, idéalement un nombre impair - trois centres de données est une configuration parfaitement correcte. Ensuite, la question est - de combien de nœuds avez-vous besoin ? Vous voulez qu'ils soient répartis uniformément dans les centres de données. Le reste n'est qu'une question de nombre de nœuds défaillants que votre configuration doit gérer.
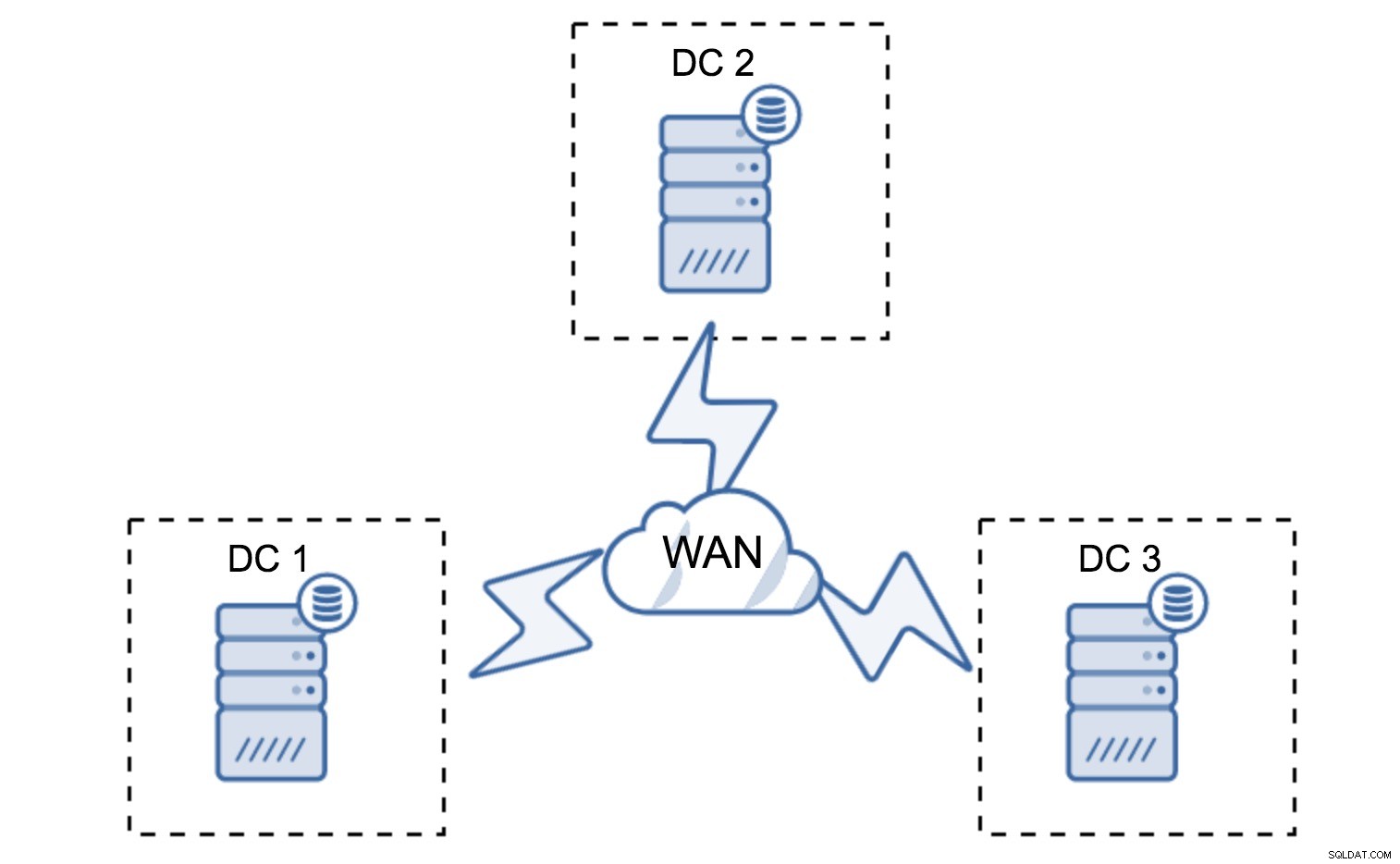
Une configuration minimale utilisera un nœud par centre de données - elle présente cependant de sérieux inconvénients. Chaque transfert d'état nécessitera le déplacement de données sur le WAN, ce qui allongera le temps nécessaire pour terminer le SST ou augmentera les coûts.
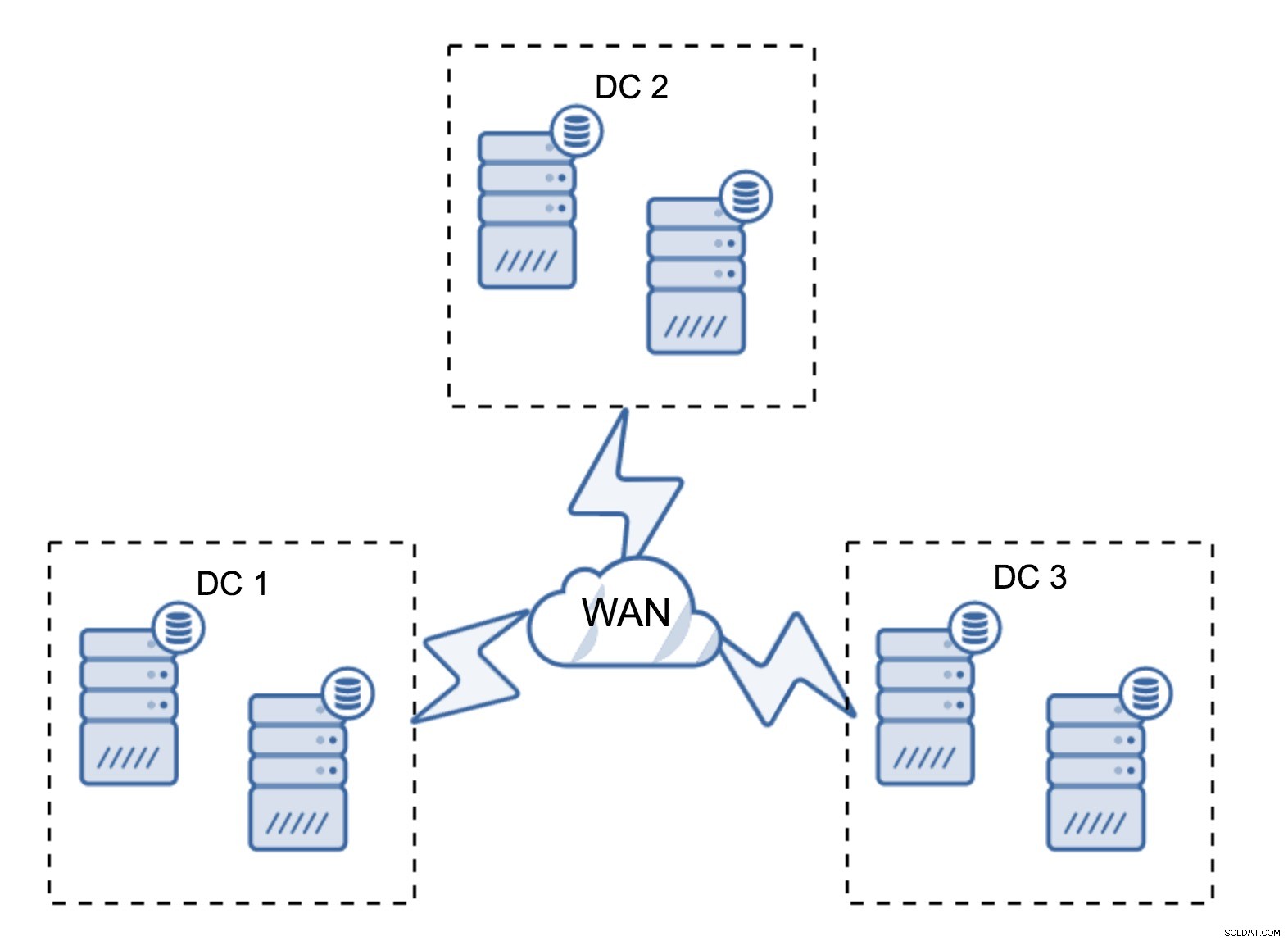
Une configuration assez typique consiste à avoir six nœuds, deux par centre de données. Cette configuration semble inattendue car elle a un nombre pair de nœuds. Mais, quand on y pense, ce n'est peut-être pas un si gros problème :il est peu probable que trois nœuds tombent en panne à la fois, et une telle configuration survivra à un crash de jusqu'à deux nœuds. Un centre de données entier peut être mis hors ligne et deux DC restants continueront leurs opérations. Il présente également un énorme avantage par rapport à la configuration minimale - lorsqu'un nœud est déconnecté, il y a toujours un deuxième nœud dans le centre de données qui peut servir de donneur. La plupart du temps, le WAN ne sera pas utilisé pour SST.
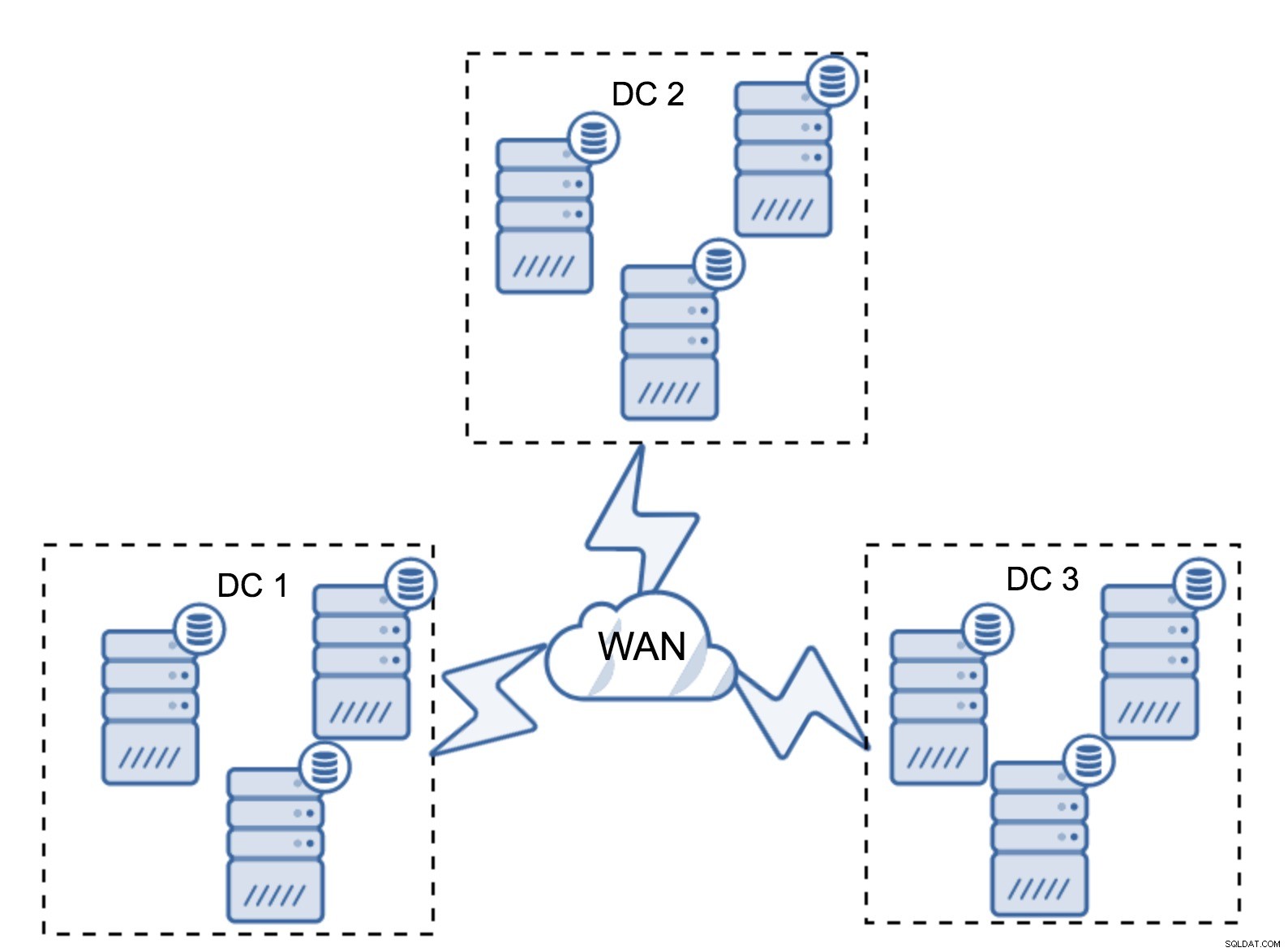
Bien sûr, vous pouvez augmenter le nombre de nœuds à trois par cluster, soit neuf au total. Cela vous donne une capacité de survie encore meilleure :jusqu'à quatre nœuds peuvent tomber en panne et le cluster survivra toujours. D'un autre côté, vous devez garder à l'esprit que, même avec l'utilisation de segments, plus de nœuds signifie une surcharge d'opérations plus élevée et vous ne pouvez faire évoluer le cluster Galera que dans une certaine mesure.
Il peut arriver qu'un troisième centre de données ne soit pas nécessaire car, disons, votre application n'est située que dans deux d'entre eux. Bien sûr, l'exigence de trois centres de données est toujours valable, vous ne la contournerez donc pas, mais il est parfaitement acceptable d'utiliser un arbitre Galera (garbd) au lieu de serveurs de base de données entièrement chargés.
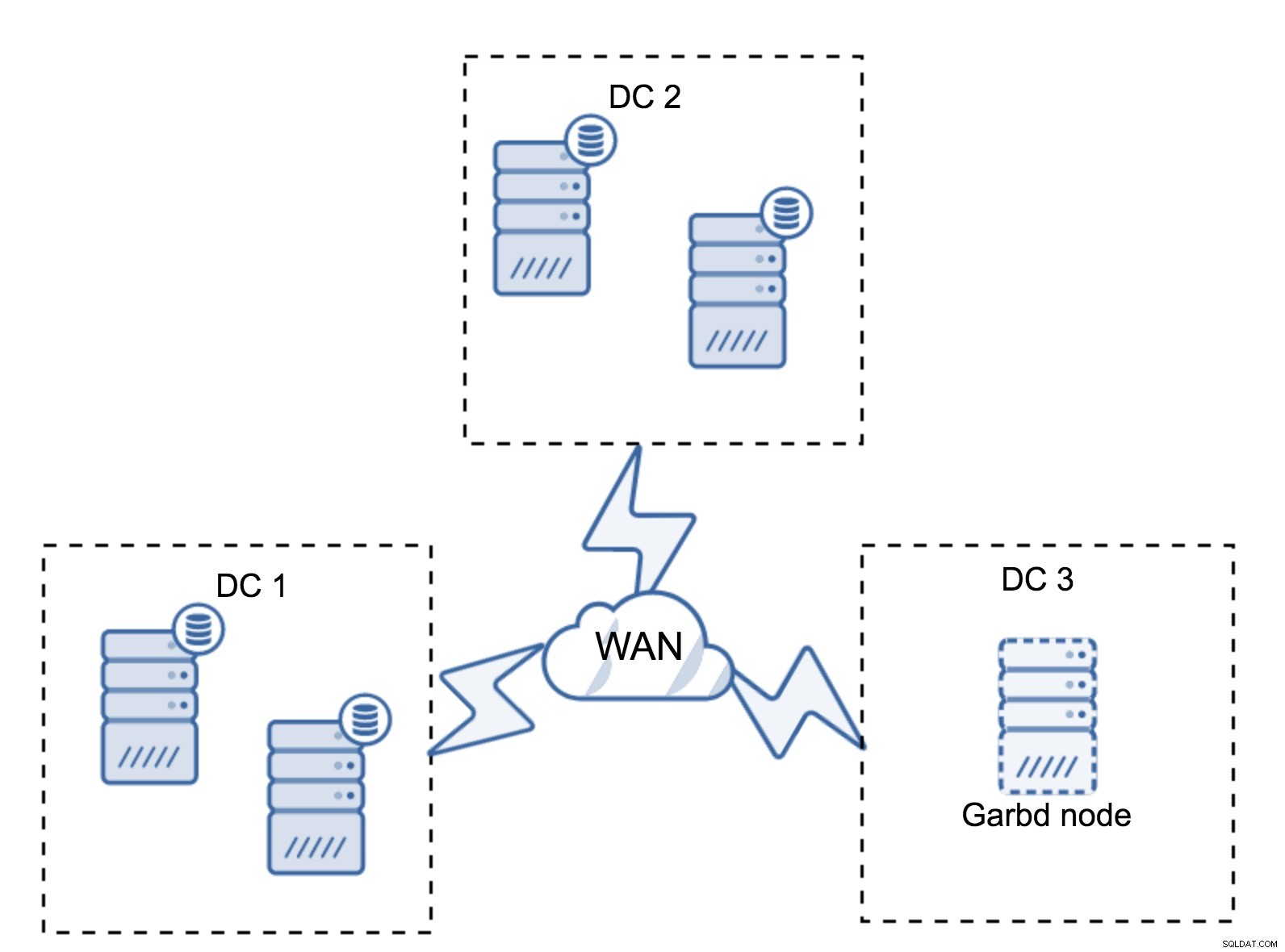
Garbd peut être installé sur des nœuds plus petits, même des serveurs virtuels. Il ne nécessite pas de matériel puissant, il ne stocke aucune donnée et n'applique aucun des jeux d'écriture. Mais il voit tout le trafic de réplication et participe au calcul du quorum. Grâce à lui, vous pouvez déployer des configurations comme quatre nœuds, deux par DC + garbd dans le troisième - vous avez cinq nœuds au total, et un tel cluster peut accepter jusqu'à deux échecs. Cela signifie donc qu'il peut accepter un arrêt complet de l'un des centres de données.
Quelle option est la meilleure pour vous ? Il n'y a pas de meilleure solution pour tous les cas, tout dépend de vos besoins en infrastructure. Heureusement, vous avez le choix entre différentes options :plus ou moins de nœuds, 3 DC complets ou 2 DC et garbd dans le troisième - il est fort probable que vous trouviez quelque chose qui vous convienne.
Latence du réseau
Lorsque vous travaillez avec des configurations multi-DC, vous devez garder à l'esprit que la latence du réseau sera nettement supérieure à ce que vous attendez d'un environnement de réseau local. Cela peut sérieusement réduire les performances du cluster Galera lorsque vous le comparez à une instance MySQL autonome ou à une configuration de réplication MySQL. L'exigence selon laquelle tous les nœuds doivent certifier un jeu d'écriture signifie que tous les nœuds doivent le recevoir, quelle que soit leur distance. Avec la réplication asynchrone, il n'est pas nécessaire d'attendre avant un commit. Bien sûr, la réplication a d'autres problèmes et inconvénients, mais la latence n'est pas le principal. Le problème est particulièrement visible lorsque votre base de données comporte des points chauds - des lignes fréquemment mises à jour (compteurs, files d'attente, etc.). Ces lignes ne peuvent pas être mises à jour plus d'une fois par aller-retour réseau. Pour les clusters couvrant le monde entier, cela peut facilement signifier que vous ne pourrez pas mettre à jour une seule ligne plus de 2 à 3 fois par seconde. Si cela devient une limitation pour vous, cela peut signifier que le cluster Galera n'est pas adapté à votre charge de travail particulière.
Couche proxy dans le cluster Galera multi-DC
Il ne suffit pas d'avoir un cluster Galera couvrant plusieurs centres de données, vous avez toujours besoin de votre application pour y accéder. L'une des méthodes les plus courantes pour masquer la complexité de la couche de base de données d'une application consiste à utiliser un proxy. Les proxys sont utilisés comme point d'entrée vers les bases de données, ils suivent l'état des nœuds de la base de données et doivent toujours diriger le trafic uniquement vers les nœuds disponibles. Dans cette section, nous essaierons de proposer une conception de couche proxy qui pourrait être utilisée pour un cluster Galera multi-DC. Nous utiliserons ProxySQL, qui vous donne une certaine flexibilité dans la gestion des nœuds de base de données, mais vous pouvez utiliser un autre proxy, tant qu'il peut suivre l'état des nœuds Galera.
Où trouver les procurations ?
En bref, il existe ici deux modèles communs :vous pouvez soit déployer ProxySQL sur des nœuds distincts, soit les déployer sur les hôtes de l'application. Examinons les avantages et les inconvénients de chacune de ces configurations.
Couche proxy en tant qu'ensemble distinct d'hôtes
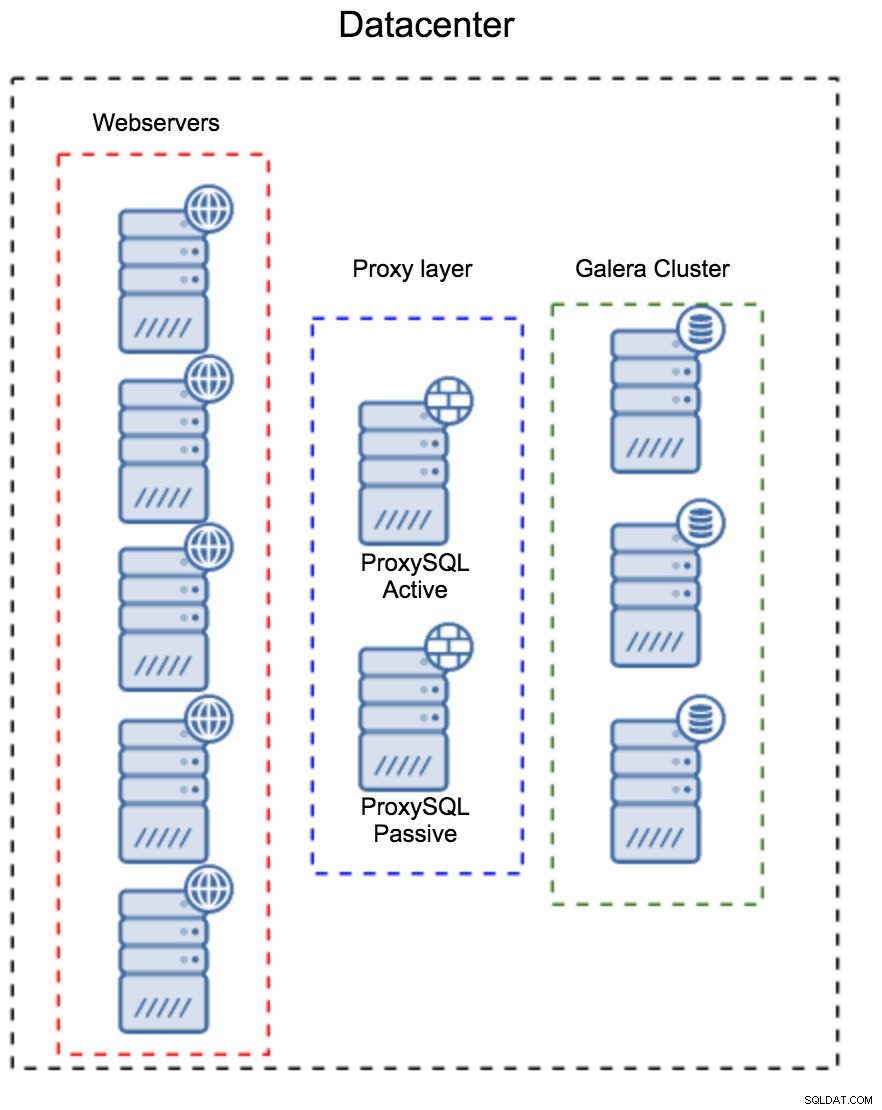
Le premier modèle consiste à créer une couche proxy à l'aide d'hôtes dédiés distincts. Vous pouvez déployer ProxySQL sur quelques hôtes et utiliser Virtual IP et keepalive pour maintenir une haute disponibilité. Une application utilisera le VIP pour se connecter à la base de données, et le VIP s'assurera que les demandes seront toujours acheminées vers un ProxySQL disponible. Le principal problème avec cette configuration est que vous utilisez au plus une des instances ProxySQL - tous les nœuds de secours ne sont pas utilisés pour acheminer le trafic. Cela peut vous obliger à utiliser un matériel plus puissant que celui que vous utilisez habituellement. D'un autre côté, il est plus facile de maintenir la configuration - vous devrez appliquer des modifications de configuration sur tous les nœuds ProxySQL, mais il n'y en aura qu'une poignée. Vous pouvez également utiliser l'option de ClusterControl pour synchroniser les nœuds. Une telle configuration devra être dupliquée sur chaque centre de données que vous utilisez.
Proxy installé sur les instances d'application
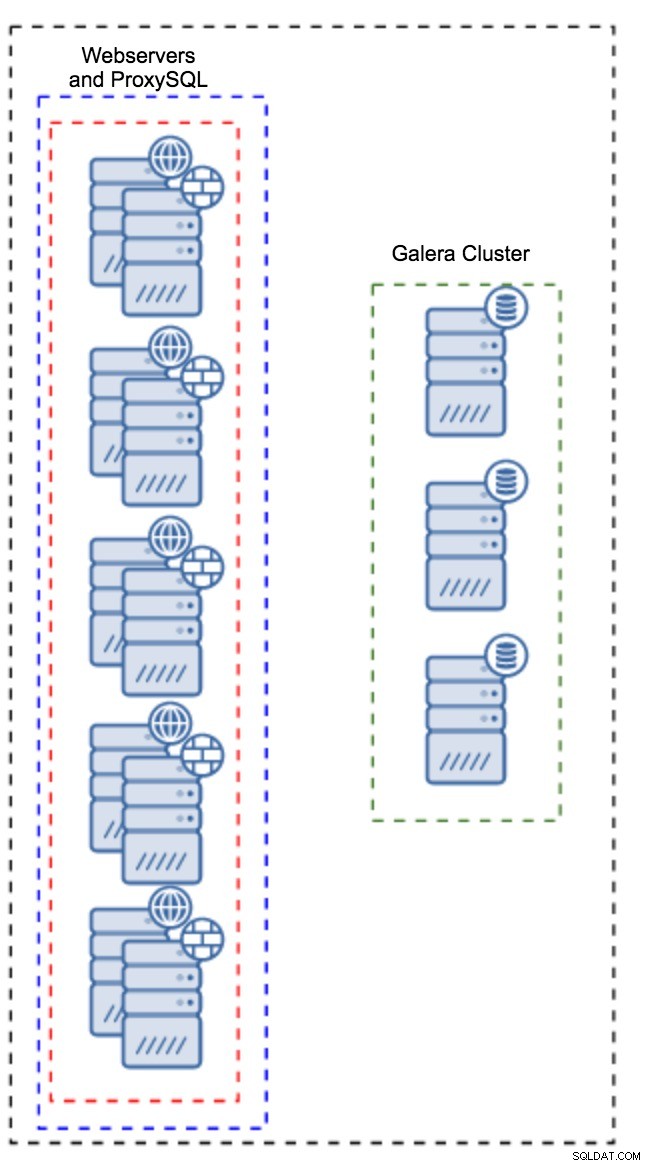
Au lieu d'avoir un ensemble d'hôtes distinct, ProxySQL peut également être installé sur les hôtes de l'application. L'application se connectera directement au ProxySQL sur localhost, elle pourrait même utiliser un socket unix pour minimiser la surcharge de la connexion TCP. Le principal avantage d'une telle configuration est que vous disposez d'un grand nombre d'instances ProxySQL et que la charge est répartie uniformément entre elles. Si l'un tombe en panne, seul cet hôte d'application sera affecté. Les nœuds restants continueront de fonctionner. Le problème le plus sérieux à affronter est la gestion de la configuration. Avec un grand nombre de nœuds ProxySQL, il est crucial de trouver une méthode automatisée pour synchroniser leurs configurations. Vous pouvez utiliser ClusterControl ou un outil de gestion de configuration comme Puppet.
Optimisation de Galera dans un environnement WAN
Les paramètres par défaut de Galera sont conçus pour le réseau local et si vous souhaitez l'utiliser dans un environnement WAN, certains réglages sont nécessaires. Discutons de quelques-uns des ajustements de base que vous pouvez apporter. N'oubliez pas que le réglage précis nécessite des données de production et du trafic. Vous ne pouvez pas simplement apporter quelques modifications et supposer qu'elles sont bonnes, vous devez effectuer une analyse comparative appropriée.
Configuration du système d'exploitation
Commençons par la configuration du système d'exploitation. Toutes les modifications proposées ici ne sont pas liées au WAN, mais il est toujours bon de se rappeler ce qui est un bon point de départ pour toute installation MySQL.
vm.swappiness = 1Swappiness contrôle l'agressivité avec laquelle le système d'exploitation utilisera le swap. Il ne doit pas être défini sur zéro car dans les noyaux plus récents, il empêche le système d'exploitation d'utiliser le swap et cela peut entraîner de graves problèmes de performances.
/sys/block/*/queue/scheduler = deadline/noopLe planificateur du périphérique de bloc, utilisé par MySQL, doit être défini sur deadline ou noop. Le choix exact dépend des benchmarks, mais les deux paramètres doivent offrir des performances similaires, meilleures que le planificateur par défaut, CFQ.
Pour MySQL, vous devriez envisager d'utiliser EXT4 ou XFS, selon le noyau (les performances de ces systèmes de fichiers changent d'une version du noyau à l'autre). Effectuez quelques benchmarks pour trouver la meilleure option pour vous.
En plus de cela, vous voudrez peut-être examiner les paramètres réseau sysctl. Nous n'en discuterons pas en détail (vous pouvez trouver de la documentation ici) mais l'idée générale est d'augmenter les tampons, les backlogs et les délais d'attente, pour faciliter la prise en charge des décrochages et des liaisons WAN instables.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0En plus du réglage du système d'exploitation, vous devriez envisager de peaufiner les paramètres liés au réseau Galera.
evs.suspect_timeout
evs.inactive_timeoutVous pouvez envisager de modifier les valeurs par défaut de ces variables. Les deux délais d'attente régissent la façon dont le cluster expulse les nœuds défaillants. Le délai d'attente suspect a lieu lorsque tous les nœuds ne peuvent pas atteindre le membre inactif. Le délai d'inactivité définit une limite stricte de la durée pendant laquelle un nœud peut rester dans le cluster s'il ne répond pas. Habituellement, vous constaterez que les valeurs par défaut fonctionnent bien. Mais dans certains cas, en particulier si vous exécutez votre cluster Galera sur WAN (par exemple, entre des régions AWS), l'augmentation de ces variables peut entraîner des performances plus stables. Nous suggérons de les définir tous les deux sur PT1M, afin de réduire le risque que l'instabilité de la liaison WAN éjecte un nœud du cluster.
evs.send_window
evs.user_send_windowCes variables, evs.send_window et evs.user_send_window , définissez combien de paquets peuvent être envoyés via la réplication en même temps (evs.send_window ) et combien d'entre eux peuvent contenir des données (evs.user_send_window ). Pour les connexions à latence élevée, il peut être utile d'augmenter ces valeurs de manière significative (512 ou 1024 par exemple).
evs.inactive_check_periodLa variable ci-dessus peut également être modifiée. evs.inactive_check_period , par défaut, est défini sur une seconde, ce qui peut être trop souvent pour une configuration WAN. Nous suggérons de le régler sur PT30S.
gcs.fc_factor
gcs.fc_limitIci, nous voulons minimiser les chances que le contrôle de flux se déclenche, nous suggérons donc de définir gcs.fc_factor à 1 et augmentez gcs.fc_limit à, par exemple, 260.
gcs.max_packet_sizeComme nous travaillons avec la liaison WAN, où la latence est nettement plus élevée, nous souhaitons augmenter la taille des paquets. Un bon point de départ serait 2097152.
Comme nous l'avons mentionné précédemment, il est pratiquement impossible de donner une recette simple sur la façon de définir ces paramètres car cela dépend de trop de facteurs - vous devrez faire vos propres benchmarks, en utilisant des données aussi proches que possible de vos données de production, avant de vous peut dire que votre système est réglé. Cela dit, ces paramètres devraient vous donner un point de départ pour un réglage plus précis.
C'est tout pour le moment. Galera fonctionne plutôt bien dans les environnements WAN, alors essayez-le et faites-nous savoir comment vous vous en sortez.