Dans cet article de blog, nous allons examiner certaines mesures et statuts clés lors de la surveillance d'un serveur Percona pour MySQL afin de nous aider à affiner la configuration du serveur MySQL à long terme. Juste pour la tête haute, Percona Server a des métriques de surveillance qui ne sont disponibles que sur cette version. Lors de la comparaison sur la version 8.0.20, les 51 statuts suivants ne sont disponibles que sur Percona Server pour MySQL, qui ne sont pas disponibles dans le serveur de communauté MySQL d'Oracle en amont :
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondaire_index_triggered_cluster_reads
- Innodb_secondaire_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Consultez la page Extended InnoDB Status pour plus d'informations sur chacune des métriques de surveillance ci-dessus. Notez que certains statuts supplémentaires comme le pool de threads ne sont disponibles que dans MySQL Enterprise d'Oracle. Consultez la documentation de Percona Server pour MySQL 8.0 pour voir toutes les améliorations spécifiques à cette version par rapport à MySQL Community Server 8.0 d'Oracle.
Pour récupérer le statut global de MySQL, utilisez simplement l'une des instructions suivantes :
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"État et aperçu de la base de données
Nous allons commencer par le statut de disponibilité, le nombre de secondes pendant lesquelles le serveur a été opérationnel.
Tous les statuts com_* sont les variables du compteur d'instructions qui indiquent le nombre de fois que chaque instruction a été exécutée. Il existe une variable d'état pour chaque type d'instruction. Par exemple, com_delete et com_update comptent respectivement les instructions DELETE et UPDATE. com_delete_multi et com_update_multi sont similaires mais s'appliquent aux instructions DELETE et UPDATE qui utilisent une syntaxe à plusieurs tables.
Pour répertorier tous les processus en cours d'exécution par MySQL, exécutez simplement l'une des instructions suivantes :
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Connexions et fils
Connexions actuelles
Le rapport des connexions actuellement ouvertes (thread de connexion). Si le ratio est élevé, cela indique qu'il existe de nombreuses connexions simultanées au serveur MySQL et peut entraîner une erreur "Trop de connexions". Pour obtenir le pourcentage de connexion :
Current connections(%) = (threads_connected / max_connections) x 100Une bonne valeur doit être de 80 % et moins. Essayez d'augmenter la variable max_connections ou inspectez les connexions à l'aide de SHOW FULL PROCESSLIST. Lorsque des erreurs "Trop de connexions" se produisent, le serveur de base de données MySQL devient indisponible pour le non-super utilisateur jusqu'à ce que certaines connexions soient libérées. Notez que l'augmentation de la variable max_connections pourrait également potentiellement augmenter l'empreinte mémoire de MySQL.
Maximum de connexions jamais vues
Le ratio de connexions maximales au serveur MySQL qui n'a jamais été vu. Un calcul simple serait :
Max connections ever seen(%) = (max_used_connections / max_connections) x 100La bonne valeur doit être inférieure à 80 %. Si le ratio est élevé, cela indique que MySQL a déjà atteint un nombre élevé de connexions, ce qui entraînerait une erreur "trop de connexions". Inspectez le taux de connexions actuel pour voir s'il reste effectivement faible de manière constante. Sinon, augmentez la variable max_connections. Vérifiez le statut max_used_connections_time pour indiquer quand le statut max_used_connections a atteint sa valeur actuelle.
Taux d'accès au cache des threads
Le statut de threads_created est le nombre de threads créés pour gérer les connexions. Si le threads_created est grand, vous pouvez augmenter la valeur de thread_cache_size. Le taux de réussite/échec du cache peut être calculé comme :
Threads cache hit rate (%) = (threads_created / connections) x 100C'est une fraction qui donne une indication du taux de succès du cache de thread. Plus près de moins de 50%, mieux c'est. Si votre serveur voit des centaines de connexions par seconde, vous devez normalement définir thread_cache_size suffisamment élevé pour que la plupart des nouvelles connexions utilisent des threads mis en cache.
Performance des requêtes
Analyses complètes de la table
Le ratio de balayages complets de la table, une opération qui nécessite de lire tout le contenu d'une table, plutôt que seulement des parties sélectionnées à l'aide d'un index. Cette valeur est élevée si vous effectuez de nombreuses requêtes nécessitant un tri des résultats ou des analyses de table. Généralement, cela suggère que les tables ne sont pas correctement indexées ou que vos requêtes ne sont pas écrites pour tirer parti des index dont vous disposez. Pour calculer le pourcentage de balayages complets de la table :
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100La bonne valeur doit être inférieure à 25 %. Examinez la sortie du journal des requêtes lentes MySQL pour découvrir les requêtes sous-optimales.
Sélectionner la jointure complète
L'état de select_full_join est le nombre de jointures qui effectuent des balayages de table car elles n'utilisent pas d'index. Si cette valeur n'est pas 0, vous devez vérifier attentivement les index de vos tables.
Sélectionner la vérification de plage
Le statut de select_range_check est le nombre de jointures sans clés qui vérifient l'utilisation des clés après chaque ligne. Si ce n'est pas 0, vous devriez vérifier attentivement les index de vos tables.
Trier les passes
Le ratio de passes de fusion que l'algorithme de tri a dû faire. Si cette valeur est élevée, vous devriez envisager d'augmenter la valeur de sort_buffer_size et read_rnd_buffer_size. Un calcul de ratio simple est :
Sort passes = sort_merge_passes / (sort_scan + sort_range)Une valeur de ratio inférieure à 3 devrait être une bonne valeur. Si vous souhaitez augmenter le sort_buffer_size ou read_rnd_buffer_size, essayez d'augmenter par petits incréments jusqu'à ce que vous atteigniez le ratio acceptable.
Performances InnoDB
Taux de réussite du pool de tampons InnoDB
Le ratio de la fréquence à laquelle vos pages sont extraites de la mémoire au lieu du disque. Si la valeur est faible au début du démarrage de MySQL, veuillez laisser le temps au pool de mémoire tampon de se réchauffer. Pour obtenir le taux de réussite du pool de mémoire tampon, utilisez l'instruction SHOW ENGINE INNODB STATUS :
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...La meilleure valeur est un taux de réussite de 1 000/10 000. Pour une valeur inférieure, par exemple, le taux de réussite de 986/1000 indique que sur 1000 pages lues, il a pu lire des pages en RAM 986 fois. Les 14 fois restantes, MySQL a dû lire les pages du disque. En termes simples, 1000/1000 est la meilleure valeur que nous essayons d'atteindre ici, ce qui signifie que les données fréquemment consultées tiennent entièrement dans la RAM.
L'augmentation de la variable innodb_buffer_pool_size aidera beaucoup à laisser plus de place à MySQL pour travailler. Cependant, assurez-vous d'avoir suffisamment de ressources RAM au préalable. La suppression des index redondants pourrait également aider. Si vous avez plusieurs instances de pool de mémoire tampon, assurez-vous que le taux de réussite de chaque instance atteint 1 000/1 000.
Pages sales InnoDB
Le ratio de la fréquence à laquelle InnoDB doit être vidé. Lors de la charge en écriture, il est normal que ce pourcentage augmente.
Un calcul simple serait :
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Une bonne valeur devrait être de 75 % et moins. Si le pourcentage de pages modifiées reste élevé pendant une longue période, vous pouvez augmenter le pool de mémoire tampon ou obtenir des disques plus rapides pour éviter les goulots d'étranglement des performances.
InnoDB attend le point de contrôle
Le ratio de la fréquence à laquelle InnoDB doit lire ou créer une page où aucune page propre n'est disponible. Normalement, les écritures dans le pool de tampons InnoDB se produisent en arrière-plan. Cependant, s'il est nécessaire de lire ou de créer une page et qu'aucune page propre n'est disponible, il est également nécessaire d'attendre que les pages soient d'abord vidées. Le compteur innodb_buffer_pool_wait_free compte combien de fois cela s'est produit. Pour calculer le ratio d'attentes InnoDB pour les points de contrôle, nous pouvons utiliser le calcul suivant :
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsSi innodb_buffer_pool_wait_free est supérieur à 0, c'est un indicateur fort que le pool de mémoire tampon InnoDB est trop petit et que les opérations ont dû attendre sur un point de contrôle. Augmenter innodb_buffer_pool_size diminuera généralement innodb_buffer_pool_wait_free, ainsi que ce ratio. Une bonne valeur de ratio doit rester inférieure à 1.
InnoDB attend Redolog
Le taux de contention de journalisation. Vérifiez innodb_log_waits et s'il continue d'augmenter, augmentez innodb_log_buffer_size. Cela peut également signifier que les disques sont trop lents et ne peuvent pas supporter les E/S du disque, peut-être en raison d'une charge d'écriture maximale. Utilisez le calcul suivant pour calculer le taux d'attente de journalisation :
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesUne bonne valeur de ratio doit être inférieure à 1. Sinon, augmentez innodb_log_buffer_size.
Tableaux
Utilisation du cache de table
Le ratio d'utilisation du cache de table pour tous les threads. Un calcul simple serait :
Table cache usage(%) = (opened_tables / table_open_cache) x 100La bonne valeur doit être inférieure à 80 %. Augmentez la variable table_open_cache jusqu'à ce que le pourcentage atteigne une bonne valeur.
Taux d'accès au cache de table
Le taux d'utilisation des hits du cache de table. Un calcul simple serait :
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Une bonne valeur de taux de réussite doit être de 90 % et plus. Sinon, augmentez la variable table_open_cache jusqu'à ce que le taux d'accès atteigne une bonne valeur.
Surveillance des métriques avec ClusterControl
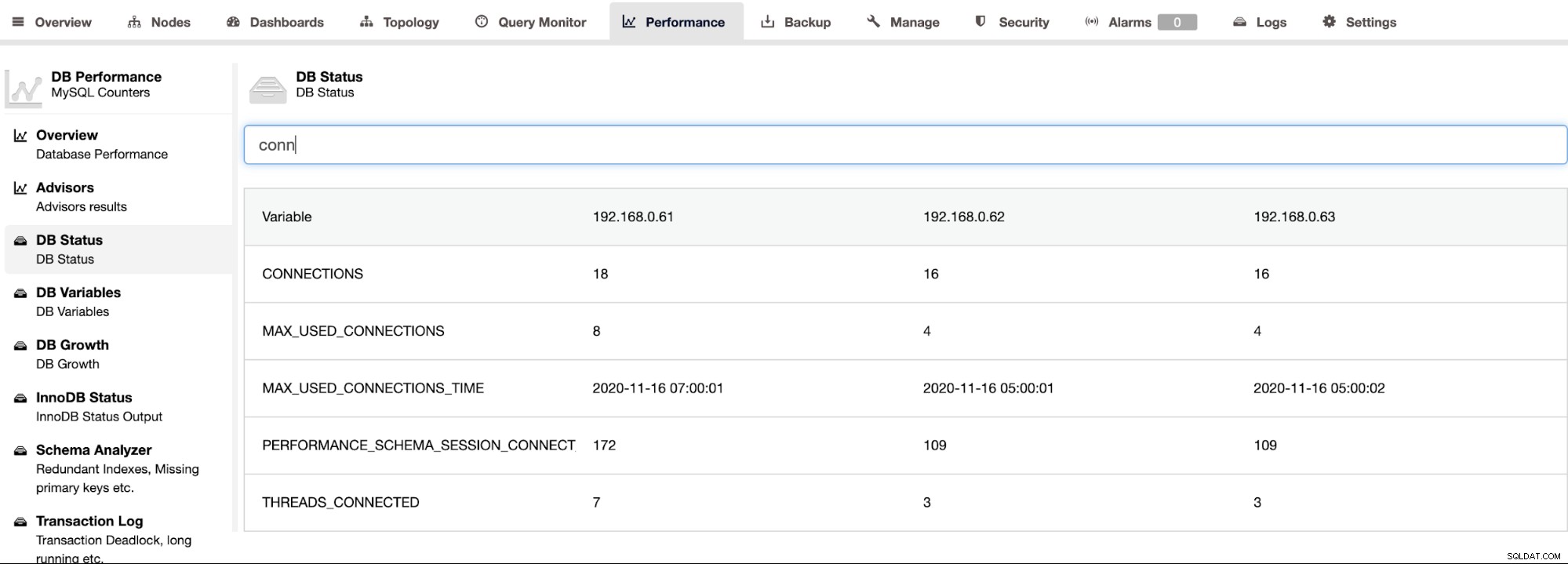
ClusterControl prend en charge Percona Server pour MySQL et fournit une vue agrégée de tous les nœuds d'un cluster sous la page ClusterControl > Performance > État de la base de données. Cela fournit une approche centralisée pour rechercher tous les statuts sur tous les hôtes avec la possibilité de filtrer le statut, comme illustré dans la capture d'écran suivante :
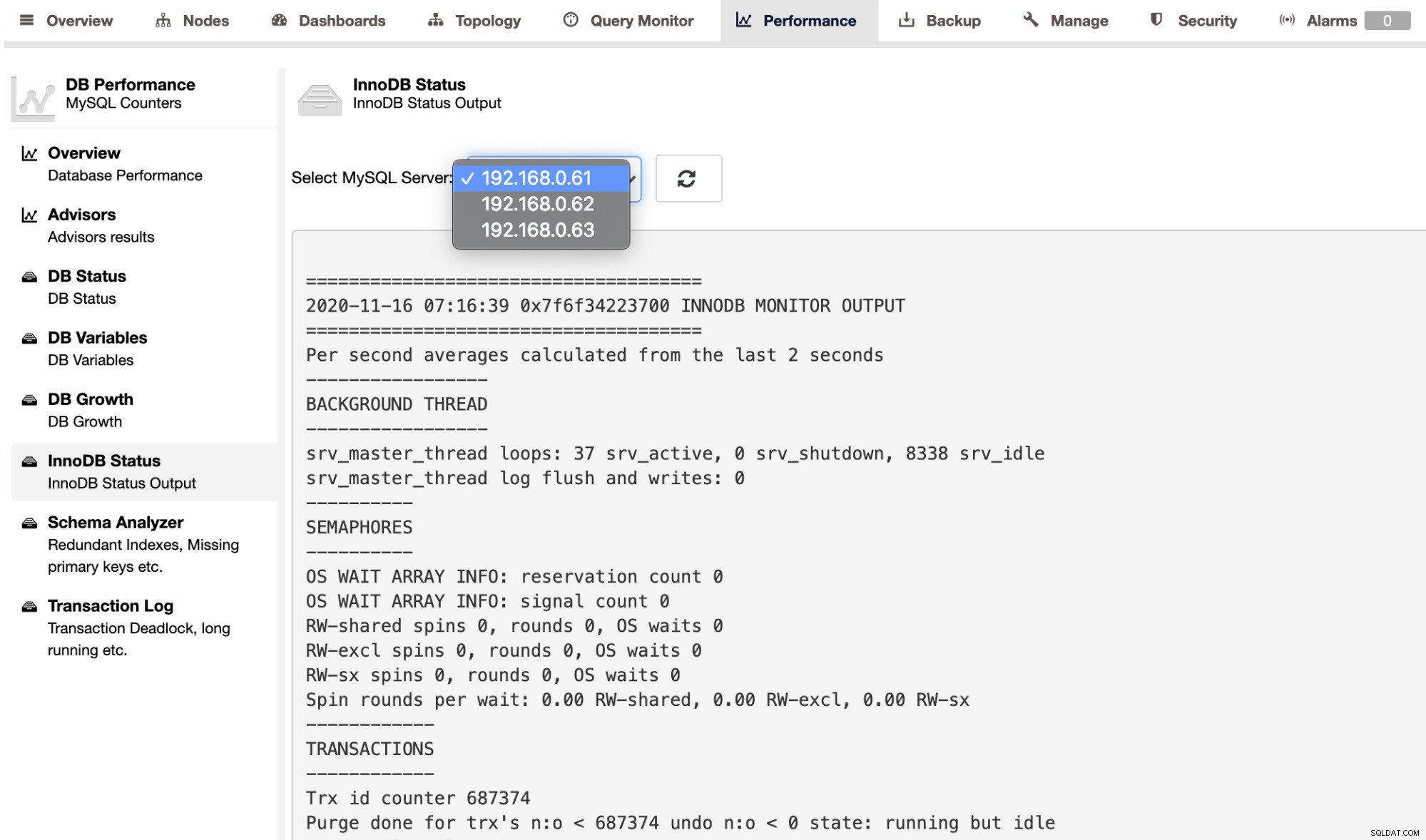
Pour récupérer la sortie SHOW ENGINE INNODB STATUS pour un serveur individuel, vous pouvez utilisez la page Performance -> InnoDB Status, comme indiqué ci-dessous :
ClusterControl fournit également des conseillers intégrés que vous pouvez utiliser pour suivre votre base de données performance. Cette fonctionnalité est accessible sous ClusterControl -> Performance -> Advisors :
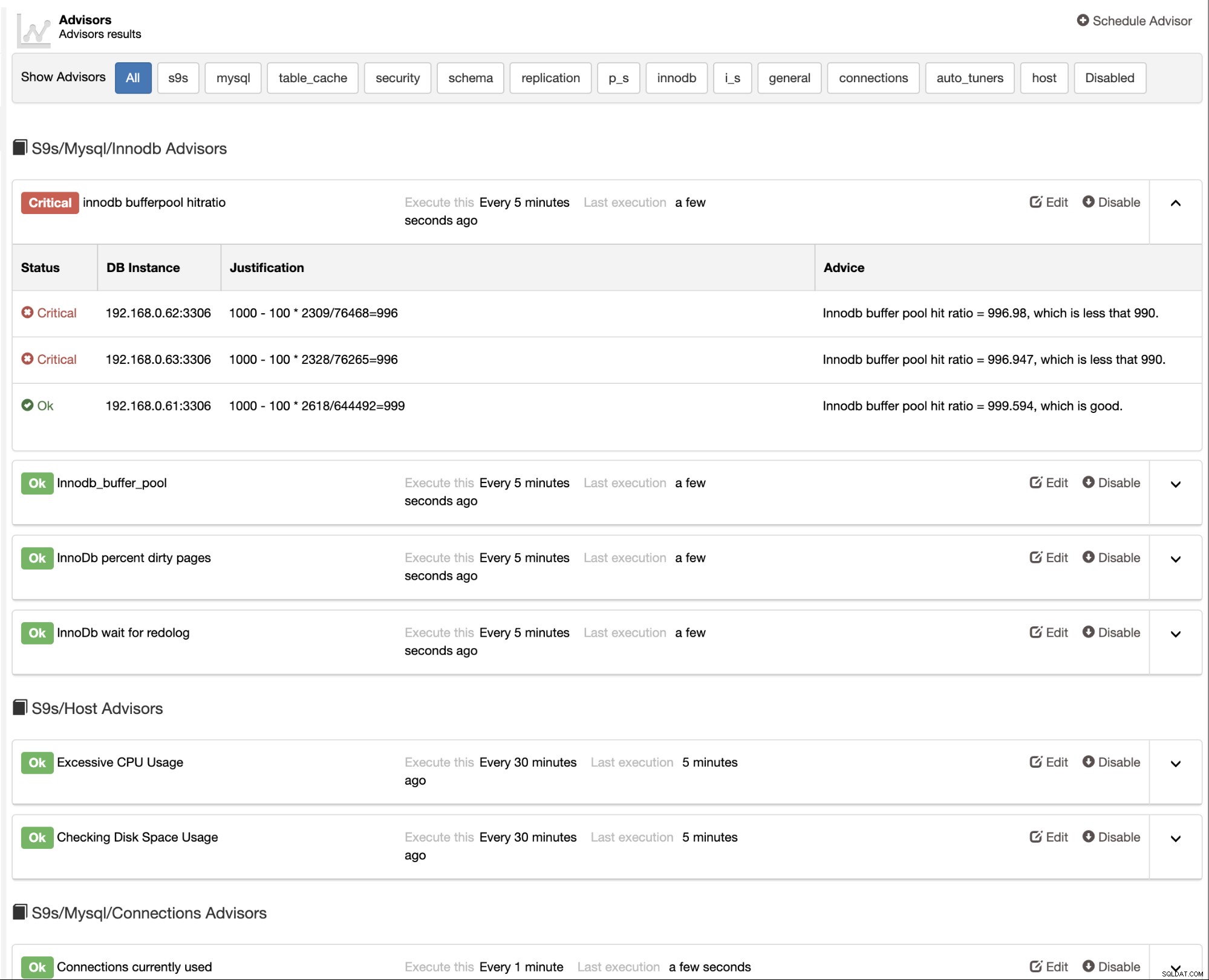
Les conseillers sont essentiellement des mini-programmes exécutés par ClusterControl dans un timing programmé comme cron emplois. Vous pouvez programmer un conseiller en cliquant sur le bouton "Planifier un conseiller" et choisir n'importe quel conseiller existant dans l'arborescence d'objets de Developer Studio :
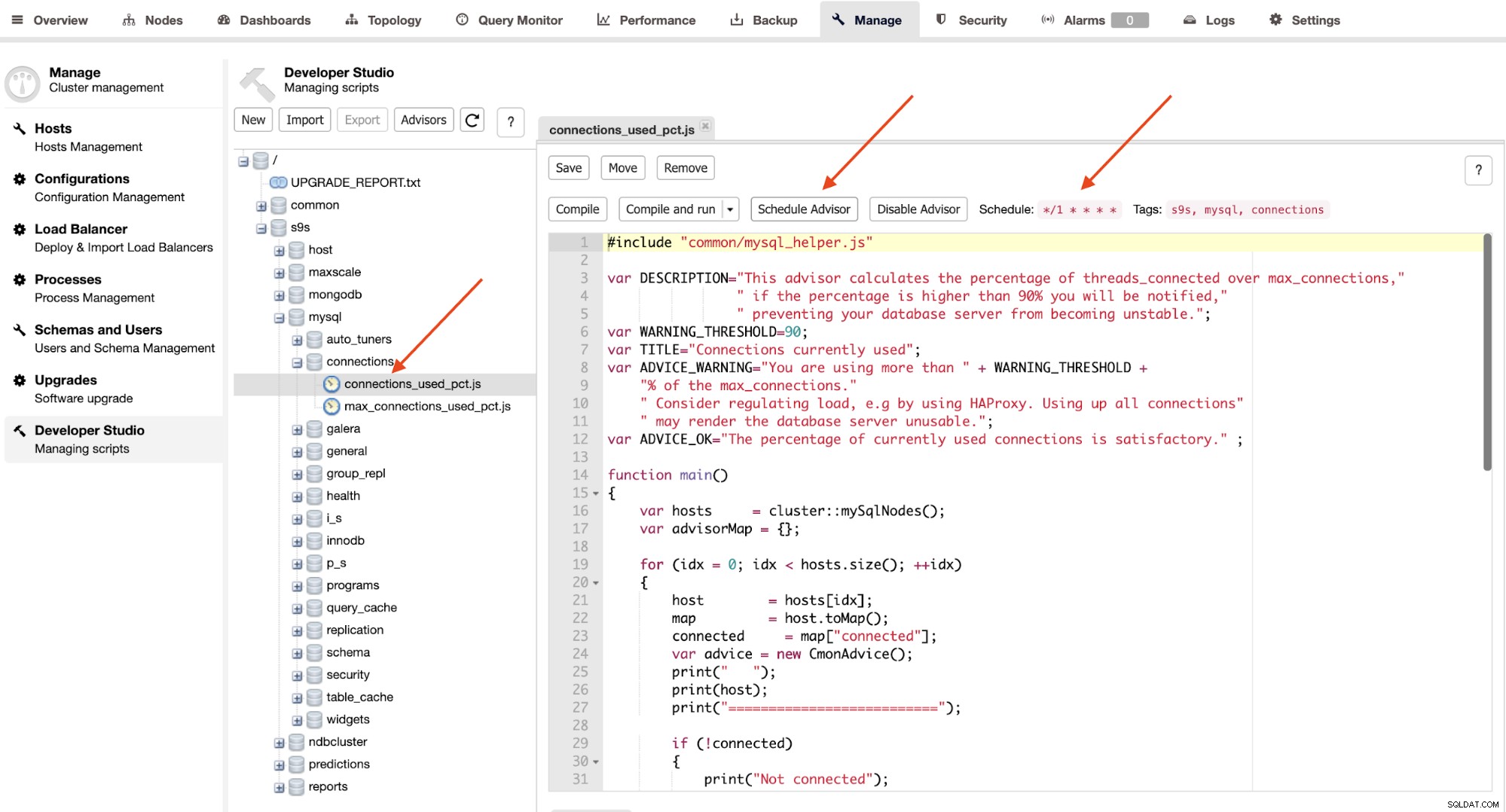
Cliquez sur le bouton "Schedule Advisor" pour définir l'argument de planification sur pass ainsi que les tags du conseiller. Vous pouvez également compiler le conseiller pour voir la sortie immédiatement en cliquant sur le bouton "Compiler et exécuter", où vous devriez voir la sortie suivante sous les "Messages" en dessous :

Vous pouvez créer votre propre conseiller en vous référant à ce Guide du développeur, écrit en ClusterControl Domain Specific Language (très similaire à Javascript), ou personnalisez un conseiller existant en fonction de vos politiques de surveillance. En bref, le devoir de surveillance de ClusterControl peut être étendu avec des possibilités illimitées grâce aux conseillers ClusterControl.