Normalement, je voudrais juste insérer et piéger l'exception DUP_VAL_ON_INDEX, car c'est la plus simple à coder. C'est plus efficace que de vérifier l'existence avant l'insertion. Je ne considère pas cela comme une "mauvaise odeur" (expression horrible !) car l'exception que nous gérons est levée par Oracle - ce n'est pas comme lever vos propres exceptions en tant que mécanisme de contrôle de flux.
Grâce au commentaire d'Igor, j'ai maintenant exécuté deux benchmarks différents à ce sujet :(1) où toutes les tentatives d'insertion, à l'exception de la première, sont des doublons, (2) où toutes les insertions ne sont pas des doublons. La réalité se situera quelque part entre les deux cas.
Remarque :tests effectués sur Oracle 10.2.0.3.0.
Cas 1 :principalement des doublons
Il semble que l'approche la plus efficace (par un facteur significatif) soit de vérifier l'existence TOUT EN insérant :
prompt 1) Check DUP_VAL_ON_INDEX
begin
for i in 1..1000 loop
begin
insert into hasviewed values(7782,20);
exception
when dup_val_on_index then
null;
end;
end loop
rollback;
end;
/
prompt 2) Test if row exists before inserting
declare
dummy integer;
begin
for i in 1..1000 loop
select count(*) into dummy
from hasviewed
where objectid=7782 and userid=20;
if dummy = 0 then
insert into hasviewed values(7782,20);
end if;
end loop;
rollback;
end;
/
prompt 3) Test if row exists while inserting
begin
for i in 1..1000 loop
insert into hasviewed
select 7782,20 from dual
where not exists (select null
from hasviewed
where objectid=7782 and userid=20);
end loop;
rollback;
end;
/
Résultats (après avoir exécuté une fois pour éviter les frais généraux d'analyse) :
1) Check DUP_VAL_ON_INDEX
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.54
2) Test if row exists before inserting
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.59
3) Test if row exists while inserting
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.20
Cas 2 :aucun doublon
prompt 1) Check DUP_VAL_ON_INDEX
begin
for i in 1..1000 loop
begin
insert into hasviewed values(7782,i);
exception
when dup_val_on_index then
null;
end;
end loop
rollback;
end;
/
prompt 2) Test if row exists before inserting
declare
dummy integer;
begin
for i in 1..1000 loop
select count(*) into dummy
from hasviewed
where objectid=7782 and userid=i;
if dummy = 0 then
insert into hasviewed values(7782,i);
end if;
end loop;
rollback;
end;
/
prompt 3) Test if row exists while inserting
begin
for i in 1..1000 loop
insert into hasviewed
select 7782,i from dual
where not exists (select null
from hasviewed
where objectid=7782 and userid=i);
end loop;
rollback;
end;
/
Résultats :
1) Check DUP_VAL_ON_INDEX
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.15
2) Test if row exists before inserting
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.76
3) Test if row exists while inserting
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.71
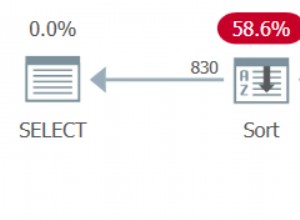
Dans ce cas, DUP_VAL_ON_INDEX gagne d'un mile. Notez que "sélectionner avant insérer" est le plus lent dans les deux cas.
Il semble donc que vous devriez choisir l'option 1 ou 3 en fonction de la probabilité relative que les insertions soient ou non des doublons.