La première question devrait être :que feriez-vous avec ces données ? Si vous n'avez pas d'exigences commerciales claires, ne le faites pas.
J'ai fait quelque chose de similaire et après 3 ans de fonctionnement, il y a environ 20% de "données valides" et le reste est constitué de "versions précédentes". Et c'est 10 millions + 40 millions d'enregistrements. Au cours des trois dernières années, nous avons eu 2 (deux) demandes d'enquête sur l'historique des changements et les deux fois, les demandes étaient stupides - nous enregistrons l'horodatage du changement d'enregistrement et on nous a demandé de vérifier si les personnes faisaient des heures supplémentaires (après 17 heures).
Maintenant, nous sommes coincés avec une base de données surdimensionnée qui contient 80 % des données dont personne n'a besoin.
MODIF :
Puisque vous avez demandé des solutions possibles, je vais décrire ce que nous avons fait. C'est un peu différent de la solution que vous envisagez.
- Toutes les tables ont une clé primaire de substitution.
- Toutes les clés primaires sont générées à partir d'une seule séquence. Cela fonctionne bien car Oracle peut générer et mettre en cache des numéros, donc pas de problèmes de performances ici. Nous utilisons ORM et nous voulions que chaque objet en mémoire (et l'enregistrement correspondant dans la base de données) ait un identifiant unique
- Nous utilisons ORM et les informations de mappage entre la table de base de données et la classe se présentent sous la forme d'attributs.
Nous enregistrons toutes les modifications dans une table d'archive unique avec les colonnes suivantes :
- id (clé primaire de substitution)
- horodatage
- tableau d'origine
- ID de l'enregistrement d'origine
- identifiant utilisateur
- type de transaction (insérer, mettre à jour, supprimer)
- enregistrer les données en tant que champ varchar2
- il s'agit de données réelles sous forme de paires nom de champ/valeur.
La chose fonctionne de cette façon :
- ORM a des commandes d'insertion/mise à jour et de suppression.
- nous avons créé une classe de base pour tous nos objets métier qui remplace les commandes d'insertion/mise à jour et de suppression
- les commandes d'insertion/mise à jour/suppression créent une chaîne sous la forme de paires nom de champ/valeur en utilisant la réflexion. Le code recherche les informations de mappage et lit le nom du champ, la valeur associée et le type de champ. Ensuite, nous créons quelque chose de similaire à JSON (nous avons ajouté quelques modifications). Lorsqu'une chaîne représentant l'état actuel de l'objet est créée, elle est insérée dans la table d'archive.
- lorsqu'un objet nouveau ou mis à jour est enregistré dans la table de la base de données, il est enregistré dans sa table cible et en même temps, nous insérons un enregistrement avec la valeur actuelle dans la table d'archive.
- lorsque l'objet est supprimé, nous le supprimons de sa table cible et en même temps nous insérons un enregistrement dans la table d'archive qui a le type de transaction ="DELETE"
Pro :
- nous n'avons pas de tables d'archives pour chaque table de la base de données. Nous n'avons pas non plus à nous soucier de la mise à jour de la table d'archive lorsque le schéma change.
- l'archive complète est séparée des "données actuelles", de sorte que l'archive n'impose aucun impact sur les performances de la base de données. Nous l'avons mis sur un tablespace séparé sur un disque séparé et cela fonctionne bien.
- nous avons créé 2 formulaires pour consulter les archives :
- visionneuse générale qui peut répertorier la table d'archives en fonction du filtre sur la table d'archives. Filtrer les données que l'utilisateur peut saisir sur le formulaire (intervalle de temps, utilisateur, ...). Nous affichons chaque enregistrement sous forme de nom de champ/valeur et chaque modification est codée par couleur. Les utilisateurs peuvent voir toutes les versions de chaque enregistrement et ils peuvent voir qui et quand ont apporté des modifications.
- visionneuse de factures - celle-ci était complexe, mais nous avons créé un formulaire qui affiche la facture très similaire au formulaire de saisie de facture d'origine, mais avec quelques boutons supplémentaires qui peuvent afficher différentes générations. Il a fallu des efforts considérables pour créer ce formulaire. Le formulaire a été utilisé quelques fois, puis oublié car il n'était pas nécessaire dans le flux de travail actuel.
- le code de création d'enregistrements d'archive est situé dans une seule classe C#. Il n'est pas nécessaire d'avoir des déclencheurs sur chaque table de la base de données.
- les performances sont très bonnes. Aux heures de pointe, le système est utilisé par environ 700 à 800 utilisateurs. C'est l'application ASP.Net. ASP.Net et Oracle fonctionnent tous deux sur un double XEON avec 8 Go de RAM.
Inconvénients :
- le format d'archive de table unique est plus difficile à lire que la solution où il y a une table d'archive pour chacune des tables de données.
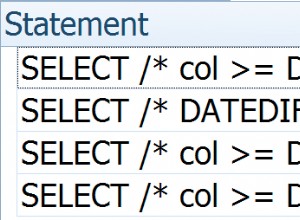
- la recherche sur un champ non-id dans la table d'archive est difficile - nous ne pouvons utiliser que
LIKEopérateur sur chaîne.
Donc, encore une fois, vérifiez les exigences sur l'archive . Ce n'est pas une tâche triviale, mais les gains et l'utilisation peuvent être minimes.