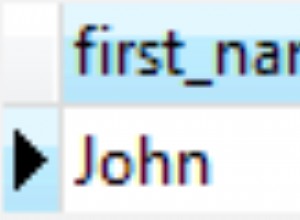
Joyce,
Voici trois exemples :
1) En utilisant dbms_utility.comma_to_table. Il ne s'agit pas d'une routine à usage général, car les éléments doivent être des identificateurs valides. Avec quelques trucs sales, nous pouvons le rendre plus universel :
SQL> declare
2 cn_non_occuring_prefix constant varchar2(4) := 'zzzz';
3 mystring varchar2(2000):='a:sd:dfg:31456:dasd: :sdfsdf'; -- just an example
4 l_tablen binary_integer;
5 l_tab dbms_utility.uncl_array;
6 begin
7 dbms_utility.comma_to_table
8 ( list => cn_non_occuring_prefix || replace(mystring,':',','||cn_non_occuring_prefix)
9 , tablen => l_tablen
10 , tab => l_tab
11 );
12 for i in 1..l_tablen
13 loop
14 dbms_output.put_line(substr(l_tab(i),1+length(cn_non_occuring_prefix)));
15 end loop;
16 end;
17 /
a
sd
dfg
31456
dasd
sdfsdf
PL/SQL-procedure is geslaagd.
2) Utilisation de la connexion SQL par niveau. Si vous êtes sur 10g ou plus, vous pouvez utiliser l'approche de connexion par niveau en combinaison avec des expressions régulières, comme ceci :
SQL> declare
2 mystring varchar2(2000):='a:sd:dfg:31456:dasd: :sdfsdf'; -- just an example
3 begin
4 for r in
5 ( select regexp_substr(mystring,'[^:]+',1,level) element
6 from dual
7 connect by level <= length(regexp_replace(mystring,'[^:]+')) + 1
8 )
9 loop
10 dbms_output.put_line(r.element);
11 end loop;
12 end;
13 /
a
sd
dfg
31456
dasd
sdfsdf
PL/SQL-procedure is geslaagd.
3) Encore une fois en utilisant la connexion SQL par niveau, mais maintenant en combinaison avec le bon vieux SUBSTR/INSTR au cas où vous êtes sur la version 9, comme vous :
SQL> declare
2 mystring varchar2(2000):='a:sd:dfg:31456:dasd: :sdfsdf'; -- just an example
3 begin
4 for r in
5 ( select substr
6 ( str
7 , instr(str,':',1,level) + 1
8 , instr(str,':',1,level+1) - instr(str,':',1,level) - 1
9 ) element
10 from (select ':' || mystring || ':' str from dual)
11 connect by level <= length(str) - length(replace(str,':')) - 1
12 )
13 loop
14 dbms_output.put_line(r.element);
15 end loop;
16 end;
17 /
a
sd
dfg
31456
dasd
sdfsdf
PL/SQL-procedure is geslaagd.
Vous pouvez voir d'autres techniques comme celles-ci dans cet article de blog :https://rwijk.blogspot.com/2007/11/interval-based-row-generation.html
J'espère que cela vous aidera.
Cordialement, Rob.
Pour répondre à votre commentaire :
Un exemple d'insertion des valeurs séparées dans un tableau normalisé.
Créez d'abord les tables :
SQL> create table csv_table (col)
2 as
3 select 'a,sd,dfg,31456,dasd,,sdfsdf' from dual union all
4 select 'a,bb,ccc,dddd' from dual union all
5 select 'zz,yy,' from dual
6 /
Table created.
SQL> create table normalized_table (value varchar2(10))
2 /
Table created.
Parce que vous semblez intéressé par l'approche dbms_utility.comma_to_table, je le mentionne ici. Cependant, je ne recommande certainement pas cette variante, en raison des bizarreries de l'identifiant et de la lenteur du traitement ligne par ligne.
SQL> declare
2 cn_non_occuring_prefix constant varchar2(4) := 'zzzz';
3 l_tablen binary_integer;
4 l_tab dbms_utility.uncl_array;
5 begin
6 for r in (select col from csv_table)
7 loop
8 dbms_utility.comma_to_table
9 ( list => cn_non_occuring_prefix || replace(r.col,',',','||cn_non_occuring_prefix)
10 , tablen => l_tablen
11 , tab => l_tab
12 );
13 forall i in 1..l_tablen
14 insert into normalized_table (value)
15 values (substr(l_tab(i),length(cn_non_occuring_prefix)+1))
16 ;
17 end loop;
18 end;
19 /
PL/SQL procedure successfully completed.
SQL> select * from normalized_table
2 /
VALUE
----------
a
sd
dfg
31456
dasd
sdfsdf
a
bb
ccc
dddd
zz
yy
14 rows selected.
Je recommande cette variante SQL :
SQL> truncate table normalized_table
2 /
Table truncated.
SQL> insert into normalized_table (value)
2 select substr
3 ( col
4 , instr(col,',',1,l) + 1
5 , instr(col,',',1,l+1) - instr(col,',',1,l) - 1
6 )
7 from ( select ',' || col || ',' col from csv_table )
8 , ( select level l from dual connect by level <= 100 )
9 where l <= length(col) - length(replace(col,',')) - 1
10 /
14 rows created.
SQL> select * from normalized_table
2 /
VALUE
----------
a
a
zz
sd
bb
yy
dfg
ccc
31456
dddd
dasd
sdfsdf
14 rows selected.
Cordialement, Rob.