Parfois, il arrive que vous ayez un très gros fichier texte ou CSV à traiter, mais vous voulez d'abord créer des fichiers plus petits de ce gros fichier. Parce que ce gros fichier peut prendre trop de temps à traiter ou à ouvrir. Je donne donc un exemple ci-dessous pour diviser un gros fichier texte/CSV en plusieurs fichiers en PL SQL à l'aide d'une procédure stockée.
Il vous suffit de passer deux paramètres à cette procédure PL SQL, le premier est le nom de l'objet du répertoire de la base de données, où résident les fichiers texte et le second est le nom du fichier source (le fichier que vous souhaitez diviser).
Si l'objet de répertoire Oracle n'existe pas pour l'emplacement des fichiers texte, vous pouvez le créer comme indiqué ci-dessous :
For windows: CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS 'D:\plsql\text_files';
For Linux/Unix (due to difference in path): CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS '/plsql/text_files';
Modifiez le chemin ci-dessus en fonction de l'emplacement de vos fichiers. Créez ensuite la procédure ci-dessous en exécutant son script :
CREATE OR REPLACE PROCEDURE split_file (p_db_dir IN VARCHAR2, p_file_name IN VARCHAR2) IS read_file UTL_FILE.file_type; write_file UTL_FILE.file_type; v_string VARCHAR2 (32767); j NUMBER := 1; BEGIN read_file := UTL_FILE.fopen (p_db_dir, p_file_name, 'r'); WHILE j > 0 LOOP write_file := UTL_FILE.fopen (p_db_dir, j || '_' || p_file_name, 'w'); FOR i IN 1 .. 100 LOOP -- example to dividing into 100 rows for each file.. you can increase the number as per your requirement UTL_FILE.get_line (read_file, v_string); UTL_FILE.put_line (write_file, v_string); END LOOP; UTL_FILE.fclose (write_file); j := J + 1; END LOOP; EXCEPTION WHEN OTHERS THEN -- this will handle if reading source file contents finish UTL_FILE.fclose (read_file); UTL_FILE.fclose (write_file); END;
Cette procédure divise 100 lignes pour chaque fichier, que vous pouvez modifier selon vos besoins. Exécutez maintenant cette procédure comme indiqué ci-dessous en transmettant le nom de l'objet du répertoire de la base de données et le nom du fichier :
BEGIN
split_file ('CSV_FILE_DIR', 'text_file.csv');
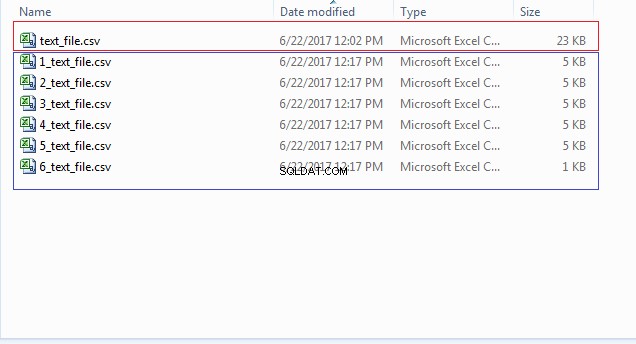
END; Vous pouvez vérifier l'emplacement de votre fichier (CSV_FILE_DIR) pour les multiples fichiers commençant par des numéros comme 1_text_file.csv, 2_text_file.csv et ainsi de suite, comme indiqué dans l'image ci-dessous :