Vous avez probablement commis certaines de ces erreurs au début de votre carrière dans la conception de bases de données. Peut-être que vous en faites encore ou que vous en ferez à l'avenir. Nous ne pouvons pas remonter le temps et vous aider à réparer vos erreurs, mais nous pouvons vous éviter des maux de tête futurs (ou présents).
La lecture de cet article pourrait vous faire économiser de nombreuses heures passées à résoudre des problèmes de conception et de code, alors plongeons-y. J'ai divisé la liste des erreurs en deux groupes principaux :celles qui sont non techniques de nature et ceux qui sont strictement techniques . Ces deux groupes sont une partie importante de la conception de la base de données.
Évidemment, si vous n'avez pas de compétences techniques, vous ne saurez pas comment faire quelque chose. Il n'est pas surprenant de voir ces erreurs sur la liste. Mais des compétences non techniques ? Les gens peuvent les oublier, mais ces compétences sont également une partie très importante du processus de conception. Ils ajoutent de la valeur à votre code et relient la technologie au problème réel que vous devez résoudre.
Alors, commençons d'abord par les problèmes non techniques, puis passons aux problèmes techniques.
Erreurs de conception de base de données non techniques
#1 Mauvaise planification
Il s'agit certainement d'un problème non technique, mais c'est un problème majeur et courant. Nous sommes tous excités lorsqu'un nouveau projet démarre et, au début, tout a l'air génial. Au début, le projet est encore une page blanche et vous et votre client êtes heureux de commencer à travailler sur quelque chose qui créera un avenir meilleur pour vous deux. Tout cela est formidable, et un grand avenir sera probablement le résultat final. Mais encore faut-il rester concentré. C'est la partie du projet où nous pouvons faire des erreurs cruciales.
Avant de vous asseoir pour dessiner un modèle de données, vous devez vous assurer que :
- Vous savez parfaitement ce que fait votre client (c'est-à-dire ses plans d'affaires liés à ce projet et aussi sa vue d'ensemble) et ce qu'il veut que ce projet réalise maintenant et à l'avenir.
- Vous comprenez le processus métier et, si nécessaire, vous êtes prêt à faire des suggestions pour le simplifier et l'améliorer (par exemple, pour augmenter l'efficacité et les revenus, réduire les coûts et les heures de travail, etc.).
- Vous comprenez le flux de données dans l'entreprise du client. Idéalement, vous connaissez tous les détails :qui travaille avec les données, qui apporte les modifications, quels rapports sont nécessaires, quand et pourquoi tout cela se produit.
- Vous pouvez utiliser le langage/la terminologie utilisés par votre client. Bien que vous soyez ou non un expert dans son domaine, votre client l'est certainement. Demandez-leur d'expliquer ce que vous ne comprenez pas. Et lorsque vous expliquez des détails techniques au client, utilisez un langage et une terminologie qu'il comprend.
- Vous savez quelles technologies vous utiliserez, du moteur de base de données et des langages de programmation aux autres outils. Ce que vous décidez d'utiliser est étroitement lié au problème que vous allez résoudre, mais il est important d'inclure les préférences du client et son infrastructure informatique actuelle.
Au cours de la phase de planification, vous devriez obtenir des réponses à ces questions :
- Quelles seront les tables centrales de votre modèle ? Vous en aurez probablement quelques-unes, tandis que les autres tables seront parmi les plus habituelles (par exemple, user_account, role). N'oubliez pas les dictionnaires et les relations entre les tables.
- Quels noms seront utilisés pour les tables dans le modèle ? N'oubliez pas de conserver une terminologie similaire à celle que le client utilise actuellement.
- Quelles règles s'appliqueront lors de l'attribution de noms aux tables et autres objets ? (Voir le point 4 sur les conventions de nommage.)
- Combien de temps l'ensemble du projet prendra-t-il ? C'est important, à la fois pour votre emploi du temps et pour le calendrier du client.
Ce n'est que lorsque vous avez toutes ces réponses que vous êtes prêt à partager une première solution au problème. Cette solution n'a pas besoin d'être une application complète - peut-être un court document ou même quelques phrases dans la langue de l'entreprise du client.
Une bonne planification n'est pas spécifique à la modélisation des données; il s'applique à presque tous les projets informatiques (et non informatiques). Ignorer n'est une option que si 1) vous avez un très petit projet ; 2) les tâches et les objectifs sont clairs, et 3) vous êtes vraiment pressé. Un exemple historique est celui des ingénieurs de lancement de Spoutnik 1 donnant des instructions verbales aux techniciens qui l'assemblaient. Le projet était pressé à cause de la nouvelle que les États-Unis prévoyaient de lancer bientôt leur propre satellite - mais je suppose que vous ne serez pas si pressé.
#2 Communication insuffisante avec les clients et les développeurs
Lorsque vous démarrez le processus de conception de la base de données, vous comprendrez probablement la plupart des principales exigences. Certains sont très courants quelle que soit l'entreprise, par ex. rôles et statuts des utilisateurs. En revanche, certaines tables de votre modèle seront assez spécifiques. Par exemple, si vous construisez un modèle pour une compagnie de taxis, vous aurez des tableaux pour les véhicules, les chauffeurs, les clients, etc.
Pourtant, tout ne sera pas évident au début d'un projet. Vous pourriez mal comprendre certaines exigences, le client pourrait ajouter de nouvelles fonctionnalités, vous verrez quelque chose qui pourrait être fait différemment, le processus pourrait changer, etc. Tout cela entraîne des changements dans le modèle. La plupart des modifications nécessitent l'ajout de nouvelles tables, mais parfois vous supprimerez ou modifierez des tables. Si vous avez déjà commencé à écrire du code qui utilise ces tables, vous devrez également réécrire ce code.
Pour réduire le temps consacré aux modifications inattendues, vous devez :
- Discutez avec les développeurs et les clients et n'ayez pas peur de poser des questions commerciales vitales. Lorsque vous pensez être prêt à commencer, demandez-vous La situation X est-elle couverte dans notre base de données ? Le client fait actuellement Y de cette façon ; attendons-nous un changement dans un futur proche ? Une fois que nous sommes convaincus que notre modèle a la capacité de stocker tout ce dont nous avons besoin de la bonne manière, nous pouvons commencer à coder.
- Si vous faites face à un changement majeur dans votre conception et que vous avez déjà écrit beaucoup de code, vous ne devriez pas essayer une solution rapide. Faites-le comme il aurait dû être fait, quelle que soit la situation actuelle. Une solution rapide pourrait vous faire gagner du temps maintenant et fonctionnerait probablement bien pendant un certain temps, mais cela peut se transformer en véritable cauchemar plus tard.
- Si vous pensez que quelque chose va bien maintenant mais pourrait devenir un problème plus tard, ne l'ignorez pas. Analysez ce domaine et mettez en œuvre des changements s'ils améliorent la qualité et les performances du système. Cela prendra du temps, mais vous fournirez un meilleur produit et dormirez beaucoup mieux.
Si vous essayez d'éviter d'apporter des modifications à votre modèle de données lorsque vous voyez un problème potentiel - ou si vous optez pour une solution rapide au lieu de le faire correctement - vous le paierez tôt ou tard.
Restez également en contact avec votre client et les développeurs tout au long du projet. Vérifiez toujours et voyez si des modifications ont été apportées depuis votre dernière discussion.
#3 Documentation médiocre ou manquante
Pour la plupart d'entre nous, la documentation vient à la fin du projet. Si nous sommes bien organisés, nous avons probablement documenté les choses en cours de route et nous n'aurons qu'à tout conclure. Mais honnêtement, ce n'est généralement pas le cas. La rédaction de la documentation se produit juste avant la clôture du projet - et juste après que nous en ayons mentalement terminé avec ce modèle de données !
Le prix payé pour un projet mal documenté peut être assez élevé, quelques fois supérieur au prix que nous payons pour tout documenter correctement. Imaginez trouver un bogue quelques mois après avoir fermé le projet. Parce que vous n'avez pas correctement documenté, vous ne savez pas par où commencer.
Pendant que vous travaillez, n'oubliez pas d'écrire des commentaires. Expliquez tout ce qui nécessite des explications supplémentaires et notez essentiellement tout ce que vous pensez être utile un jour. Vous ne savez jamais si ou quand vous aurez besoin de ces informations supplémentaires.
Erreurs techniques de conception de la base de données
#4 Ne pas utiliser de convention de dénomination
Vous ne savez jamais avec certitude combien de temps durera un projet et si vous aurez plus d'une personne travaillant sur le modèle de données. Il y a un moment où vous êtes vraiment proche du modèle de données, mais vous n'avez pas encore commencé à le dessiner. C'est à ce moment qu'il est sage de décider comment vous nommerez les objets dans votre modèle, dans la base de données et dans l'application générale. Avant de modéliser, vous devez savoir :
- Les noms de table sont-ils au singulier ou au pluriel ?
- Allons-nous regrouper les tables en utilisant des noms ? (Par exemple, toutes les tables liées au client contiennent "client_", toutes les tables liées aux tâches contiennent "task_", etc.)
- Allons-nous utiliser des lettres majuscules et minuscules, ou seulement des minuscules ?
- Quel nom allons-nous utiliser pour les colonnes d'ID ? (Il s'agira probablement de "id".)
- Comment allons-nous nommer les clés étrangères ? (Très probablement "id_" et le nom de la table référencée.)
Comparez la partie d'un modèle qui n'utilise pas de conventions de nommage avec la même partie qui utilise des conventions de nommage, comme indiqué ci-dessous :
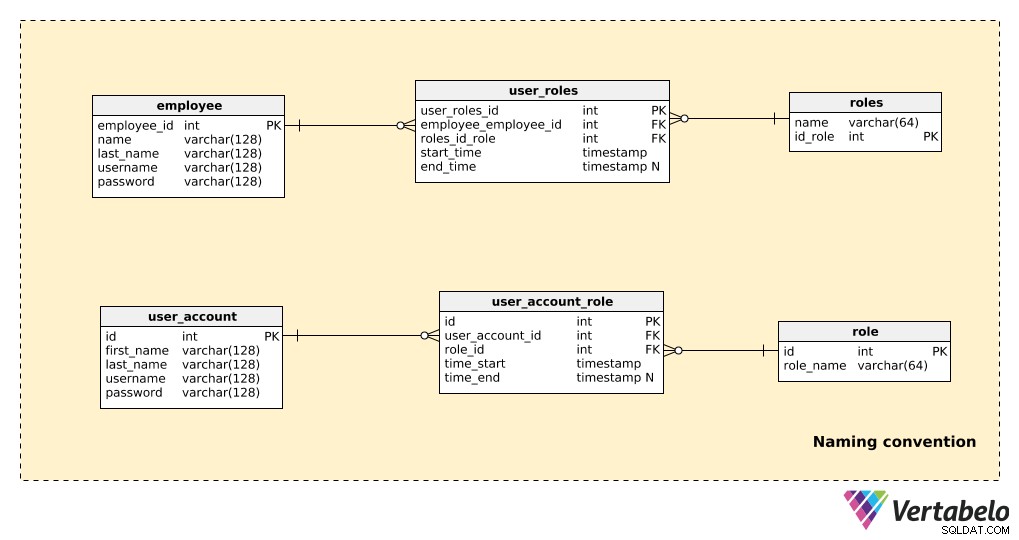
Il n'y a que quelques tableaux ici, mais il est encore assez évident de savoir quel modèle est le plus facile à lire. Notez que :
- Les deux modèles "fonctionnent", il n'y a donc aucun problème technique.
- Dans l'exemple de non-convention de dénomination (les trois tableaux du haut), il y a quelques éléments qui ont un impact significatif sur la lisibilité :l'utilisation de formes au singulier et au pluriel dans les noms de table ; noms de clés primaires non normalisés (
employees_id,id_role); et les attributs de différentes tables partagent le même nom (par exemple, le nom apparaît à la fois dans le champ "employee" et les "roles” tableaux).
Imaginez maintenant le désordre que nous créerions si notre modèle contenait des centaines de tables. Peut-être que nous pourrions travailler avec un tel modèle (si nous le créions nous-mêmes) mais nous rendrions quelqu'un très malchanceux s'il devait travailler dessus après nous.
Pour éviter de futurs problèmes avec les noms, n'utilisez pas de mots réservés SQL, de caractères spéciaux ou d'espaces.
Donc, avant de commencer à créer des noms, créez un document simple (peut-être quelques pages seulement) qui décrit la convention de dénomination que vous avez utilisée. Cela augmentera la lisibilité de l'ensemble du modèle et simplifiera les travaux futurs.
Vous pouvez en savoir plus sur les conventions de dénomination dans ces deux articles :
- Conventions de dénomination dans la modélisation de base de données
- Un regard logique sans émotion sur les conventions de dénomination de SQL Server
#5 Problèmes de normalisation
La normalisation est une partie essentielle de la conception de la base de données. Chaque base de données doit être normalisée à au moins 3NF (les clés primaires sont définies, les colonnes sont atomiques et il n'y a pas de groupes répétitifs, de dépendances partielles ou de dépendances transitives). Cela réduit la duplication des données et garantit l'intégrité référentielle.
Vous pouvez en savoir plus sur la normalisation dans cet article. En bref, chaque fois que nous parlons du modèle de base de données relationnelle, nous parlons de la base de données normalisée. Si une base de données n'est pas normalisée, nous rencontrerons un tas de problèmes liés à l'intégrité des données.
Dans certains cas, nous pouvons vouloir dénormaliser notre base de données. Si vous faites cela, ayez une très bonne raison. Vous pouvez en savoir plus sur la dénormalisation de la base de données ici.
#6 Utilisation du modèle Entity-Attribute-Value (EAV)
EAV signifie entité-attribut-valeur. Cette structure peut être utilisée pour stocker des données supplémentaires sur n'importe quoi dans notre modèle. Prenons un exemple.
Supposons que nous souhaitions stocker des attributs client supplémentaires. Le "customer ” table est notre entité, le “attribute ” table est évidemment notre attribut, et le “attribute_value ” table contient la valeur de cet attribut pour ce client.
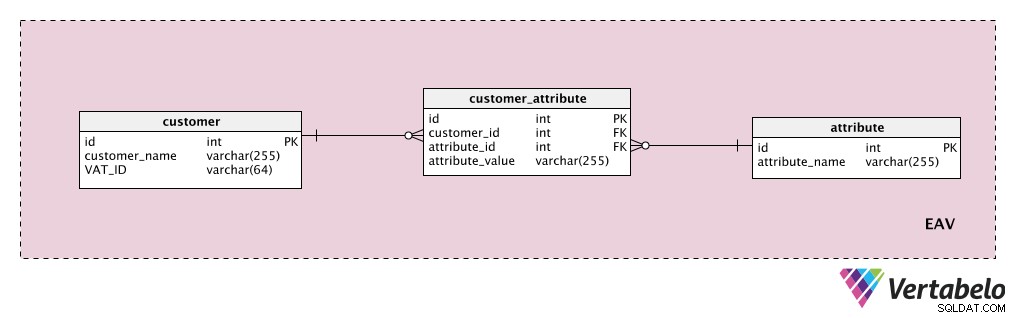
Tout d'abord, nous allons ajouter un dictionnaire avec une liste de toutes les propriétés possibles que nous pourrions attribuer à un client. Il s'agit de l'"attribute " table. Il peut contenir des propriétés telles que "valeur client", "coordonnées", "informations supplémentaires", etc. Le "customer_attribute ” contient une liste de tous les attributs, avec des valeurs, pour chaque client. Pour chaque client, nous n'aurons que des enregistrements pour les attributs dont ils disposent, et nous stockerons le "attribute_value ” pour cet attribut.
Cela pourrait sembler vraiment génial. Cela nous permettrait d'ajouter facilement de nouvelles propriétés (car nous les ajoutons en tant que valeurs dans le "customer_attribute " table). Ainsi, nous éviterions de faire des changements dans la base de données. Presque trop beau pour être vrai.
Et c'est trop bien. Bien que le modèle stocke les données dont nous avons besoin, travailler avec de telles données est beaucoup plus compliqué. Et cela inclut presque tout, de l'écriture de simples requêtes SELECT à l'obtention de toutes les valeurs liées au client, en passant par l'insertion, la mise à jour ou la suppression de valeurs.
Bref, il faut éviter la structure EAV. Si vous devez l'utiliser, ne l'utilisez que lorsque vous êtes sûr à 100 % qu'il est vraiment nécessaire.
#7 Utilisation d'un GUID/UUID comme clé primaire
Un GUID (Globally Unique Identifier) est un nombre de 128 bits généré selon les règles définies dans la RFC 4122. Ils sont parfois également appelés UUID (Universally Unique Identifiers). Le principal avantage d'un GUID est qu'il est unique; la chance que vous frappiez le même GUID deux fois est vraiment peu probable. Par conséquent, les GUID semblent être un excellent candidat pour la colonne de clé primaire. Mais ce n'est pas le cas.
Une règle générale pour les clés primaires est que nous utilisons une colonne d'entiers avec la propriété d'auto-incrémentation définie sur "oui". Cela ajoutera des données dans un ordre séquentiel à la clé primaire et fournira des performances optimales. Sans clé séquentielle ou horodatage, il n'y a aucun moyen de savoir quelles données ont été insérées en premier. Ce problème se pose également lorsque nous utilisons des valeurs réelles UNIQUES (par exemple, un numéro de TVA). Bien qu'ils contiennent des valeurs UNIQUES, ils ne font pas de bonnes clés primaires. Utilisez-les plutôt comme clés alternatives.
Une remarque supplémentaire : Je préfère utiliser des attributs entiers générés automatiquement sur une seule colonne comme clé primaire. C'est certainement la meilleure pratique. Je vous recommande d'éviter d'utiliser des clés primaires composites.
#8 Indexation insuffisante
Les index sont une partie très importante du travail avec les bases de données, mais une discussion approfondie à leur sujet sort du cadre de cet article. Heureusement, nous avons déjà quelques articles liés aux index que vous pouvez consulter pour en savoir plus :- Qu'est-ce qu'un index de base de données ?
- Tout sur les index :les bases
- Tout sur les index, partie 2 :Structure et performances de l'index MySQL
La version courte est que je vous recommande d'ajouter un index là où vous pensez qu'il sera nécessaire. Vous pouvez également les ajouter une fois la base de données en production si vous constatez que l'ajout d'un index à un certain endroit améliorera les performances.
#9 Données redondantes
Les données redondantes doivent généralement être évitées dans tout modèle. Non seulement cela prend de l'espace disque supplémentaire, mais cela augmente également considérablement les risques de problèmes d'intégrité des données. Si quelque chose doit être redondant, nous devons veiller à ce que les données d'origine et la « copie » soient toujours dans des états cohérents. En fait, il existe certaines situations où des données redondantes sont souhaitables :
- Dans certains cas, nous devons attribuer une priorité à une certaine action. Pour ce faire, nous devons effectuer des calculs complexes. Ces calculs peuvent utiliser de nombreuses tables et consommer beaucoup de ressources. Dans de tels cas, il serait judicieux d'effectuer ces calculs pendant les heures creuses (évitant ainsi les problèmes de performances pendant les heures de travail). Si nous le faisons de cette façon, nous pourrions stocker cette valeur calculée et l'utiliser plus tard sans avoir à la recalculer. Bien sûr, la valeur est redondante; cependant, ce que nous gagnons en performances est bien supérieur à ce que nous perdons (un peu d'espace sur le disque dur).
- Nous pouvons également stocker un petit ensemble de données de rapport dans la base de données. Par exemple, à la fin de la journée, nous stockerons le nombre d'appels que nous avons passés ce jour-là, le nombre de ventes réussies, etc. Les données de rapport ne doivent être stockées de cette manière que si nous devons les utiliser souvent. Encore une fois, on va perdre un peu d'espace disque, mais on évitera de recalculer les données ou de se connecter à la base de données de reporting (si on en a une).
Dans la plupart des cas, nous ne devrions pas utiliser de données redondantes car :
- Le stockage des mêmes données plusieurs fois dans la base de données peut avoir un impact sur l'intégrité des données. Si vous stockez le nom d'un client à deux endroits différents, vous devez apporter des modifications (insérer/mettre à jour/supprimer) aux deux endroits en même temps. Cela complique également le code dont vous aurez besoin, même pour les opérations les plus simples.
- Bien que nous puissions stocker des chiffres agrégés dans notre base de données opérationnelle, nous ne devrions le faire que lorsque nous en avons vraiment besoin. Une base de données opérationnelle n'est pas destinée à stocker des données de rapport, et mélanger les deux est généralement une mauvaise pratique. Toute personne produisant des rapports devra utiliser les mêmes ressources que les utilisateurs travaillant sur des tâches opérationnelles ; les requêtes de création de rapports sont généralement plus complexes et peuvent affecter les performances. Par conséquent, vous devez séparer votre base de données opérationnelle et votre base de données de rapports.
Maintenant, c'est à vous de donner votre avis
J'espère que la lecture de cet article vous a donné de nouvelles idées et vous encouragera à suivre les meilleures pratiques de modélisation des données. Ils vous feront gagner du temps !
Avez-vous rencontré l'un des problèmes mentionnés dans cet article ? Pensez-vous que nous avons manqué quelque chose d'important? Ou pensez-vous que nous devrions supprimer quelque chose de notre liste ? Veuillez nous le dire dans les commentaires ci-dessous.