J'ai écrit précédemment sur la propriété Actual Rows Read. Il vous indique combien de lignes sont réellement lues par une recherche d'index, afin que vous puissiez voir à quel point le prédicat de recherche est sélectif, par rapport à la sélectivité du prédicat de recherche et du prédicat résiduel combinés.
Mais regardons ce qui se passe réellement à l'intérieur de l'opérateur Seek. Parce que je ne suis pas convaincu que "Actual Rows Read" soit nécessairement une description précise de ce qui se passe.
Je souhaite examiner un exemple qui interroge des adresses de types d'adresses particuliers pour un client, mais le principe ici s'appliquerait facilement à de nombreuses autres situations si la forme de votre requête correspond, comme la recherche d'attributs dans une table de paires clé-valeur, par exemple.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Je sais que je ne vous ai rien montré sur les métadonnées - j'y reviendrai dans une minute. Réfléchissons à cette requête et au type d'index que nous aimerions avoir pour elle.
Tout d'abord, nous connaissons exactement le CustomerID. Une correspondance d'égalité comme celle-ci en fait généralement un excellent candidat pour la première colonne d'un index. Si nous avions un index sur cette colonne, nous pourrions plonger directement dans les adresses de ce client - donc je dirais que c'est une hypothèse sûre.
La prochaine chose à considérer est ce filtre sur AddressTypeID. Ajouter une deuxième colonne aux clés de notre index est parfaitement raisonnable, alors faisons-le. Notre index est maintenant activé (CustomerID, AddressTypeID). Et INCLUONS également FullAddress, afin que nous n'ayons pas besoin de faire de recherche pour compléter l'image.
Et je pense que nous avons terminé. Nous devrions pouvoir supposer en toute sécurité que l'index idéal pour cette requête est :
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Nous pourrions potentiellement le déclarer en tant qu'index unique - nous en examinerons l'impact plus tard.
Créons donc une table (j'utilise tempdb, car je n'en ai pas besoin pour persister au-delà de cet article de blog) et testons-la.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Je ne suis pas intéressé par les contraintes de clé étrangère, ou quelles autres colonnes il pourrait y avoir. Je ne m'intéresse qu'à mon indice idéal. Alors créez-le aussi, si vous ne l'avez pas déjà fait.
Mon plan semble plutôt parfait.
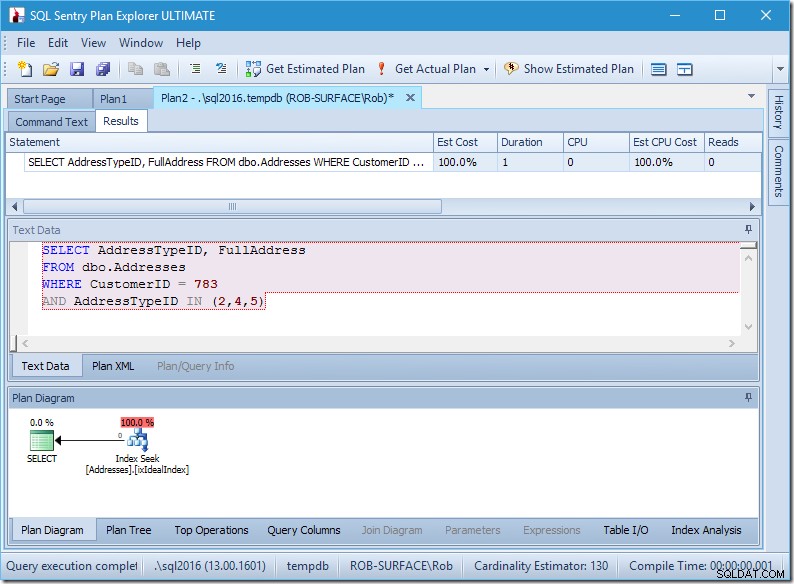
J'ai une recherche d'index, et c'est tout.
Certes, il n'y a pas de données, donc il n'y a pas de lectures, pas de processeur, et cela fonctionne assez rapidement aussi. Si seulement toutes les requêtes pouvaient être réglées aussi bien que celle-ci.
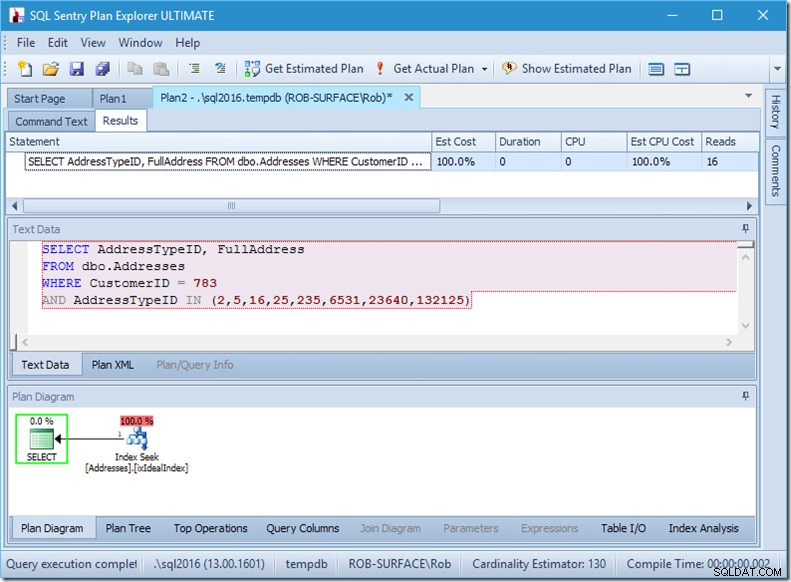
Voyons ce qui se passe d'un peu plus près, en regardant les propriétés du Seek.
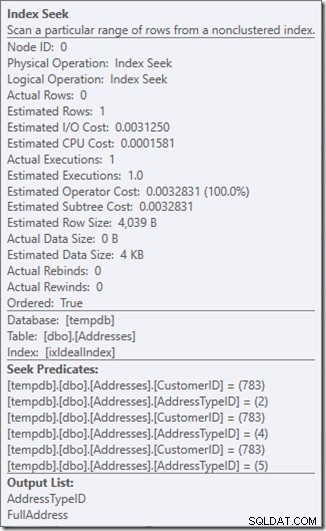
Nous pouvons voir les prédicats Seek. Il y a six. Trois sur le CustomerID et trois sur le AddressTypeID. Ce que nous avons en réalité ici, ce sont trois ensembles de prédicats de recherche, indiquant trois opérations de recherche au sein d'un seul opérateur Seek. La première recherche recherche Customer 783 et AddressType 2. La seconde recherche 783 et 4, et la dernière 783 et 5. Notre opérateur Seek est apparu une fois, mais il y avait trois recherches en cours à l'intérieur.
Nous n'avons même pas de données, mais nous pouvons voir comment notre index va être utilisé.
Introduisons quelques données factices, afin que nous puissions examiner une partie de l'impact de cela. Je vais mettre des adresses pour les types 1 à 6. Chaque client (plus de 2000, basé sur la taille de master..spt_values ) aura une adresse de type 1. C'est peut-être l'adresse principale. Je laisse 80 % avoir une adresse de type 2, 60 % une adresse de type 3, etc., jusqu'à 20 % pour le type 5. La ligne 783 obtiendra des adresses de type 1, 2, 3 et 4, mais pas 5. J'aurais préféré utiliser des valeurs aléatoires, mais je veux m'assurer que nous sommes sur la même page pour les exemples.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Examinons maintenant notre requête avec des données. Deux rangées sortent. C'est comme avant, mais nous voyons maintenant les deux lignes sortant de l'opérateur Seek, et nous voyons six lectures (en haut à droite).
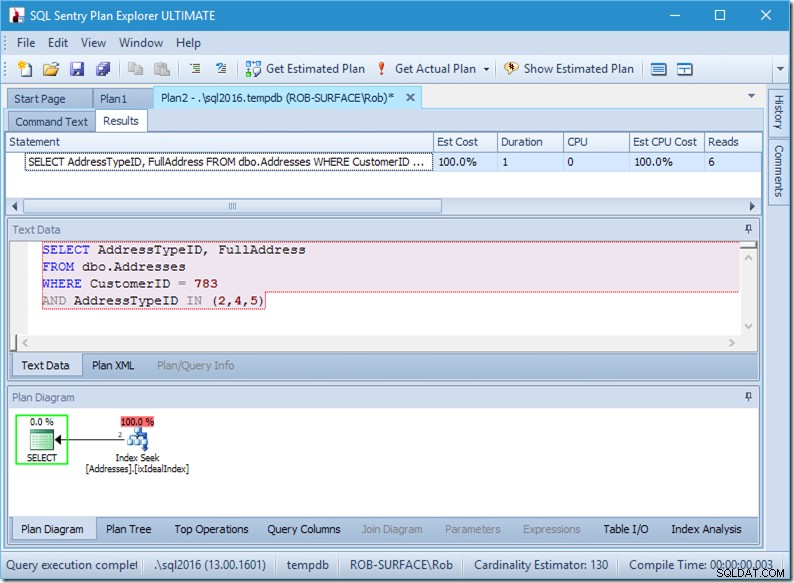
Six lectures ont du sens pour moi. Nous avons une petite table et l'index tient sur seulement deux niveaux. Nous effectuons trois recherches (au sein de notre opérateur unique), donc le moteur lit la page racine, trouve à quelle page descendre et lit cela, et le fait trois fois.
Si nous devions simplement rechercher deux AddressTypeID, nous ne verrions que 4 lectures (et dans ce cas, une seule ligne en sortie). Parfait.
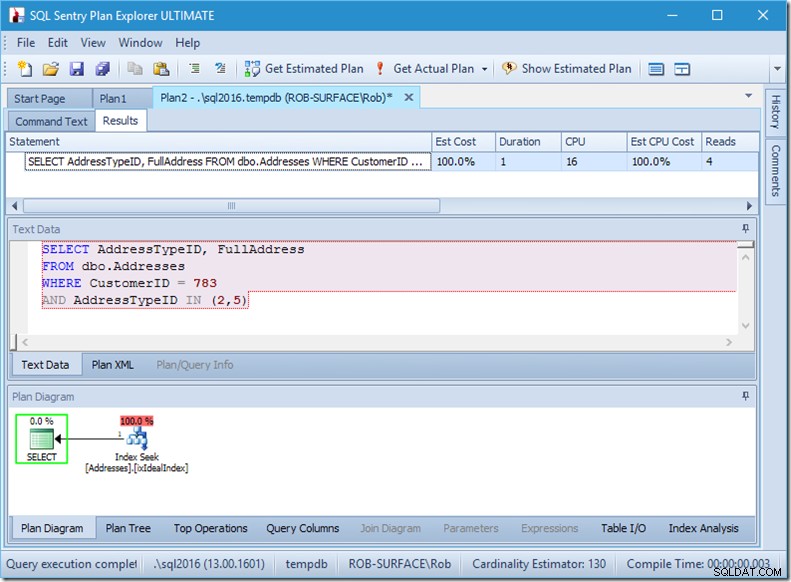
Et si nous cherchions 8 types d'adresses, nous en verrions 16.
Pourtant, chacun d'entre eux montre que la lecture des lignes réelles correspond exactement aux lignes réelles. Aucune inefficacité du tout !
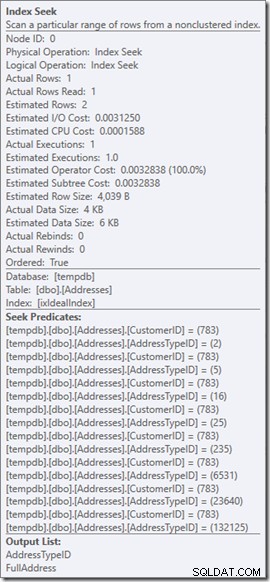
Revenons à notre requête d'origine, en recherchant les types d'adresse 2, 4 et 5 (qui renvoient 2 lignes) et réfléchissons à ce qui se passe à l'intérieur de la recherche.
Je vais supposer que le moteur de requête a déjà fait le travail pour déterminer que la recherche d'index est la bonne opération et qu'il a le numéro de page de la racine de l'index à portée de main.
À ce stade, il charge cette page en mémoire, si elle n'y est pas déjà. C'est la première lecture qui est comptée dans l'exécution de la recherche. Ensuite, il localise le numéro de page de la ligne qu'il recherche et lit cette page. C'est la deuxième lecture.
Mais nous oublions souvent ce bit "localise le numéro de page".
En utilisant DBCC IND(2, N'dbo.Address', 2); (le premier 2 est l'identifiant de la base de données car j'utilise tempdb ; le deuxième 2 est l'identifiant d'index de ixIdealIndex ), je peux découvrir que le 712 dans le fichier 1 est la page avec le plus haut IndexLevel. Dans la capture d'écran ci-dessous, je peux voir que la page 668 est IndexLevel 0, qui est la page racine.

Alors maintenant, je peux utiliser DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); pour voir le contenu de la page 712. Sur ma machine, j'obtiens 84 lignes qui reviennent, et je peux dire que CustomerID 783 va être à la page 1004 du fichier 5.
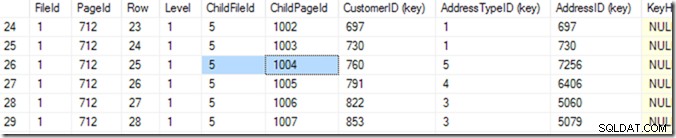
Mais je le sais en faisant défiler ma liste jusqu'à ce que je vois celui que je veux. J'ai commencé par faire défiler un peu vers le bas, puis je suis remonté jusqu'à ce que je trouve la ligne que je voulais. Un ordinateur appelle cela une recherche binaire, et c'est un peu plus précis que moi. Il recherche la ligne où la combinaison (CustomerID, AddressTypeID) est plus petite que celle que je recherche, la page suivante étant plus grande ou identique à celle-ci. Je dis "le même" parce qu'il pourrait y en avoir deux qui correspondent, répartis sur deux pages. Il sait qu'il y a 84 lignes (0 à 83) de données dans cette page (il le lit dans l'en-tête de la page), il commencera donc par vérifier la ligne 41. À partir de là, il sait dans quelle moitié rechercher et (dans cet exemple), il lira la ligne 20. Quelques lectures supplémentaires (ce qui fait 6 ou 7 au total)* et il sait que la ligne 25 (veuillez regarder la colonne appelée 'Row' pour cette valeur, pas le numéro de ligne fourni par SSMS ) est trop petit, mais la ligne 26 est trop grande - donc 25 est la réponse !
*Dans une recherche binaire, la recherche peut être légèrement plus rapide si elle a de la chance lorsqu'elle divise le bloc en deux s'il n'y a pas d'emplacement du milieu, et selon que l'emplacement du milieu peut être éliminé ou non.
Maintenant, il peut aller à la page 1004 du fichier 5. Utilisons DBCC PAGE sur celui-ci.
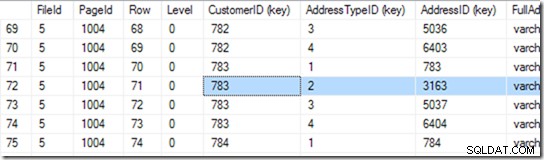
Celui-ci me donne 94 lignes. Il effectue une autre recherche binaire pour trouver le début de la plage qu'il recherche. Il doit parcourir 6 ou 7 lignes pour trouver cela.
« Début de gamme ? » Je peux vous entendre demander. Mais nous recherchons l'adresse de type 2 du client 783.
D'accord, mais nous n'avons pas déclaré cet index comme unique. Il pourrait donc y en avoir deux. S'il est unique, la recherche peut effectuer une recherche singleton et peut tomber dessus pendant la recherche binaire, mais dans ce cas, elle doit terminer la recherche binaire pour trouver la première ligne de la plage. Dans ce cas, c'est la ligne 71.
Mais nous ne nous arrêtons pas là. Maintenant, il faut voir s'il y en a vraiment un deuxième ! Il lit donc également la ligne 72 et trouve que la paire CustomerID+AddressTypeiD est en effet trop grande, et sa recherche est terminée.
Et cela arrive trois fois. La troisième fois, il ne trouve pas de ligne pour le client 783 et le type d'adresse 5, mais il ne le sait pas à l'avance et doit encore terminer la recherche.
Ainsi, les lignes réellement lues sur ces trois recherches (pour trouver deux lignes à produire) sont bien supérieures au nombre renvoyé. Il y en a environ 7 au niveau d'index 1, et environ 7 autres au niveau feuille juste pour trouver le début de la plage. Ensuite, il lit la ligne qui nous intéresse, puis la ligne suivante. Cela ressemble plus à 16 pour moi, et il le fait trois fois, ce qui fait environ 48 lignes.
Mais la lecture réelle des lignes ne concerne pas le nombre de lignes réellement lues, mais le nombre de lignes renvoyées par le prédicat Seek, qui sont testées par rapport au prédicat résiduel. Et en cela, seules les 2 lignes sont trouvées par les 3 recherches.
Vous pensez peut-être à ce stade qu'il y a une certaine inefficacité ici. La deuxième recherche aurait également lu la page 712, vérifié les mêmes 6 ou 7 lignes, puis lu la page 1004, et l'aurait parcourue... comme l'aurait fait la troisième recherche.
Alors peut-être aurait-il été préférable de l'obtenir en une seule recherche, en lisant la page 712 et la page 1004 une seule fois chacune. Après tout, si je faisais cela avec un système papier, j'aurais fait une recherche pour trouver le client 783, puis j'aurais scanné tous leurs types d'adresses. Parce que je sais qu'un client n'a généralement pas beaucoup d'adresses. C'est un avantage que j'ai sur le moteur de base de données. Le moteur de base de données sait grâce à ses statistiques qu'une recherche sera la meilleure, mais il ne sait pas que la recherche ne doit descendre que d'un niveau, alors qu'il peut dire qu'il a ce qui semble être l'indice idéal.
Si je modifie ma requête pour saisir une plage de types d'adresses, de 2 à 5, j'obtiens presque le comportement souhaité :
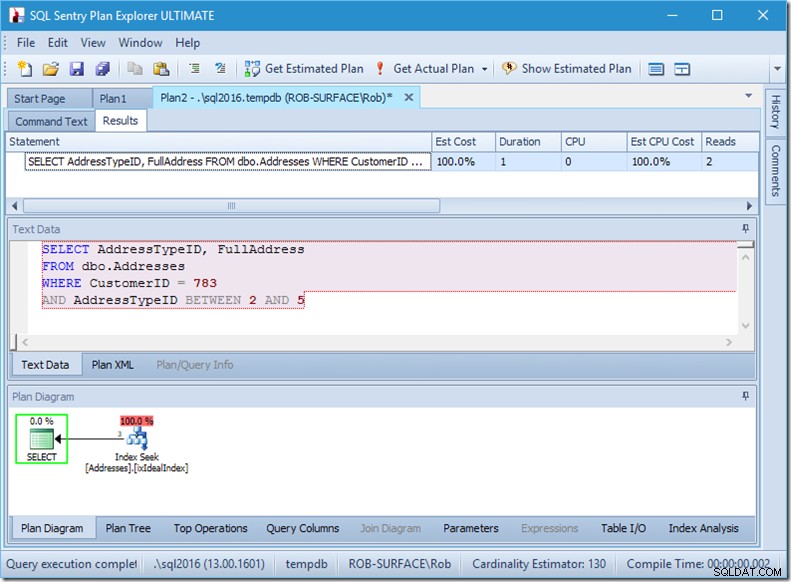
Regardez - les lectures sont réduites à 2, et je sais de quelles pages il s'agit…
… mais mes résultats sont faux. Parce que je ne veux que les types d'adresse 2, 4 et 5, pas 3. Je dois lui dire de ne pas en avoir 3, mais je dois faire attention à la façon dont je le fais. Regardez les deux exemples suivants.
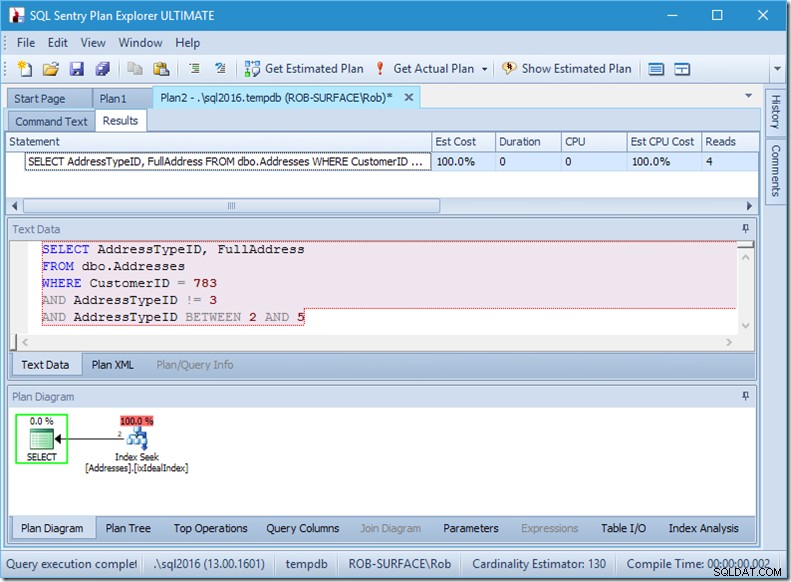
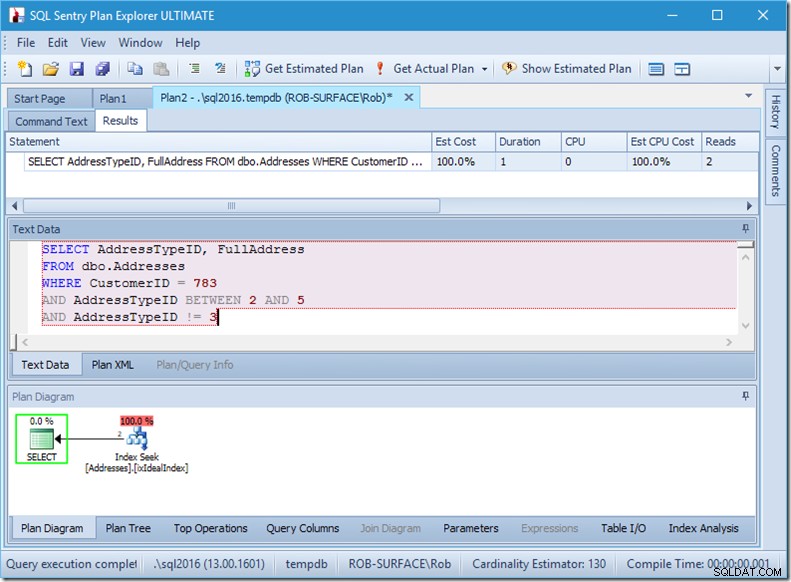
Je peux vous assurer que l'ordre des prédicats n'a pas d'importance, mais ici c'est clairement le cas. Si nous mettons le "pas 3" en premier, il fait deux recherches (4 lectures), mais si nous mettons le "pas 3" en second, il fait une seule recherche (2 lectures).
Le problème est que AddressTypeID !=3 est converti en (AddressTypeID> 3 OR AddressTypeID <3), qui est alors considéré comme deux prédicats de recherche très utiles.
Et donc ma préférence est d'utiliser un prédicat non sargable pour lui dire que je ne veux que les types d'adresse 2, 4 et 5. Et je peux le faire en modifiant AddressTypeID d'une manière ou d'une autre, comme en y ajoutant zéro.
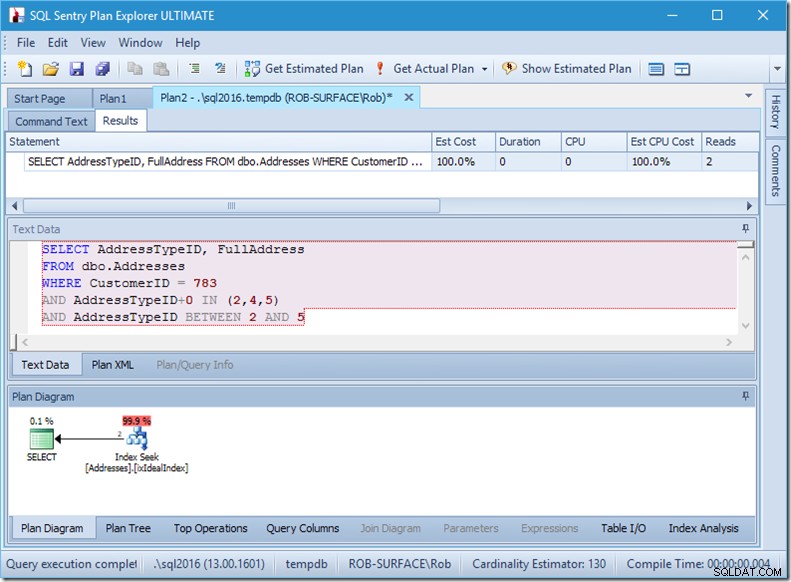
Maintenant, j'ai une analyse de plage agréable et étroite dans une seule recherche, et je m'assure toujours que ma requête ne renvoie que les lignes que je veux.
Oh, mais cette propriété Actual Rows Read ? C'est maintenant plus élevé que la propriété Actual Rows, car le Seek Predicate trouve le type d'adresse 3, que le Residual Predicate rejette.
J'ai échangé trois recherches parfaites contre une seule recherche imparfaite, que je corrige avec un prédicat résiduel.
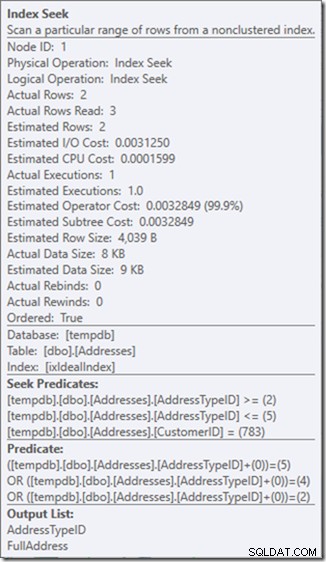
Et pour moi, c'est parfois un prix qui vaut la peine d'être payé, me procurer un plan de requête dont je suis beaucoup plus heureux. Ce n'est pas considérablement moins cher, même s'il n'a qu'un tiers des lectures (car il n'y aurait jamais que deux lectures physiques), mais quand je pense au travail qu'il fait, je suis beaucoup plus à l'aise avec ce que je lui demande faire de cette façon.



