Les opérateurs ROLLUP et CUBE sont utilisés pour renvoyer des résultats agrégés par les colonnes dans la clause GROUP BY.
Les fonctions GROUPING et GROUPING_ID sont utilisées pour identifier si les colonnes de la liste GROUP BY sont agrégées (à l'aide des opérateurs ROLLUP ou CUBE) ou non.
Il existe deux différences majeures entre les fonctions GROUPING et GROUPING_ID.
Ils sont les suivants :
- La fonction GROUPING est applicable sur une seule colonne, tandis que la liste des colonnes de la fonction GROUPING_ID doit correspondre à la liste des colonnes dans la clause GROUP BY.
- La fonction GROUPING indique si une colonne de la liste GROUP BY est agrégée ou non. Elle renvoie 1 si le jeu de résultats est agrégé et 0 si le jeu de résultats n'est pas agrégé.
D'autre part, la fonction GROUPING_ID renvoie également un entier. Cependant, il effectue la conversion binaire en décimal après avoir concaténé le résultat de toutes les fonctions GROUPING.
Dans cet article, nous verrons les fonctions GROUPING et GROUPING_ID en action à l'aide d'exemples.
Préparer des données factices
Comme toujours, créons des données factices que nous allons utiliser pour l'exemple avec lequel nous allons travailler dans cet article.
Exécutez le script suivant :
CREATE Database company;
USE company;
CREATE TABLE employee
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
salary INT NOT NULL,
department VARCHAR(50) NOT NULL
)
INSERT INTO employee
VALUES
(1, 'David', 'Male', 5000, 'Sales'),
(2, 'Jim', 'Female', 6000, 'HR'),
(3, 'Kate', 'Female', 7500, 'IT'),
(4, 'Will', 'Male', 6500, 'Marketing'),
(5, 'Shane', 'Female', 5500, 'Finance'),
(6, 'Shed', 'Male', 8000, 'Sales'),
(7, 'Vik', 'Male', 7200, 'HR'),
(8, 'Vince', 'Female', 6600, 'IT'),
(9, 'Jane', 'Female', 5400, 'Marketing'),
(10, 'Laura', 'Female', 6300, 'Finance'),
(11, 'Mac', 'Male', 5700, 'Sales'),
(12, 'Pat', 'Male', 7000, 'HR'),
(13, 'Julie', 'Female', 7100, 'IT'),
(14, 'Elice', 'Female', 6800,'Marketing'),
(15, 'Wayne', 'Male', 5000, 'Finance')
Dans le script ci-dessus, nous avons créé une base de données nommée "Société". Nous avons ensuite créé une table « Employé » dans la base de données de l'entreprise. Enfin, nous avons inséré des enregistrements factices dans la table Employee.
Fonction de GROUPEMENT
Comme mentionné ci-dessus, la fonction GROUPING renvoie 1 si le jeu de résultats est agrégé et 0 si le jeu de résultats n'est pas agrégé.
Jetez un œil au script suivant pour voir la fonction GROUPING en action.
SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, GROUPING(department) as GP_Department, GROUPING(gender) as GP_Gender FROM employee GROUP BY ROLLUP (department, gender)
Le script ci-dessus compte la somme des salaires de tous les employés masculins et féminins, qui sont d'abord regroupés par la colonne Service, puis par la colonne Sexe. Deux colonnes supplémentaires sont ajoutées pour afficher le résultat de la fonction GROUPING appliquée aux colonnes Department et Gender.
L'opérateur ROLLUP permet d'afficher la somme des salaires sous forme de totaux généraux et de sous-totaux.
La sortie du script ci-dessus ressemble à ceci.
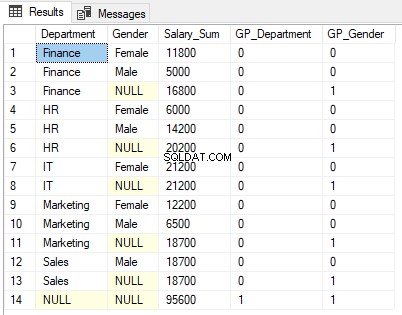
Jetez un oeil attentif à la sortie. La somme des salaires est affichée par sexe et par département (lignes 1, 2, 4, 5, 7, 9, 10 et 12). Il est ensuite également agrégé par sexe uniquement (lignes 3, 6, 8, 11 et 13). Enfin, le total général des salaires agrégés par département et par sexe est affiché à la ligne 14.
1 s'affiche dans la colonne de la fonction GROUPING GP_Gender pour les lignes où les résultats sont agrégés par sexe, c'est-à-dire les lignes 3, 6, 8, 11 et 13. Cela est dû au fait que la colonne GP_Gender contient le résultat de la fonction GROUPING appliquée à la colonne Gender.
De même, la ligne 14 contient la somme agrégée de tous les départements et de toutes les colonnes. Par conséquent, 1 est renvoyé pour les colonnes GP_Department et GP_Gender.
Vous pouvez voir que NULL est affiché dans les colonnes Département et Genre dans la sortie où les résultats sont agrégés. Par exemple, dans la ligne 3, NULL est affiché dans la colonne Sexe car les résultats sont agrégés par colonne de sexe et il n'y a donc aucune valeur de colonne à afficher. Nous ne voulons pas que nos utilisateurs voient NULL, un meilleur mot ici pourrait être "Tous les genres".
Pour cela, nous devons modifier notre script comme suit :
SELECT CASE WHEN GROUPING(department) = 1 THEN 'All Departments' ELSE ISNULL(department, 'Unknown') END as Department, CASE WHEN GROUPING(gender) = 1 THEN 'All Genders' ELSE ISNULL(gender, 'Unknown') END as Gender, sum(salary) as Salary_Sum FROM employee GROUP BY ROLLUP (department, gender)
Dans le script ci-dessus, si la fonction GROUPING appliquée à la colonne Department renvoie 1 et que « All Departments » s'affiche dans la colonne Department. Sinon, si la colonne Département contient la valeur NULL, elle affichera « Inconnu ». La colonne sexe a été modifiée de la même manière.
L'exécution du script ci-dessus renvoie les résultats suivants :
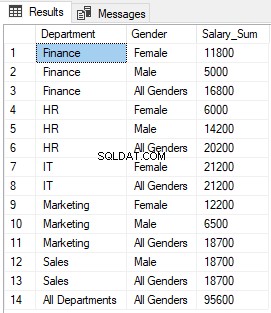
Vous pouvez voir que NULL dans les colonnes Department et Gender où la fonction GROUPING renvoie 1, a été remplacé par "All Departments" et "All Genders", respectivement.
Fonction GROUPING_ID
La fonction GROUPING_ID concatène la sortie des fonctions GROUPING appliquées à toutes les colonnes spécifiées dans la clause GROUP BY. Il effectue ensuite une conversion binaire en décimal avant de renvoyer la sortie finale.
Commençons par concaténer la sortie renvoyée par la fonction GROUPING appliquée aux colonnes Department et Gender. Jetez un oeil au script suivant :
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping FROM employee GROUP BY ROLLUP (department, gender)
Dans la sortie, vous verrez des 0 et des 1 renvoyés par la fonction GROUPING concaténés ensemble. La sortie ressemble à ceci :
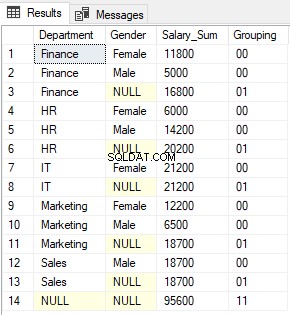
La fonction GROUPING_ID renvoie simplement l'équivalent décimal de la valeur binaire formée à la suite de la concaténation des valeurs renvoyées par les fonctions GROUPING.
Exécutez le script suivant pour voir la fonction GROUPING ID en action :
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping, GROUPING_ID(department, gender) as Grouping_Id FROM employee GROUP BY ROLLUP (department, gender)
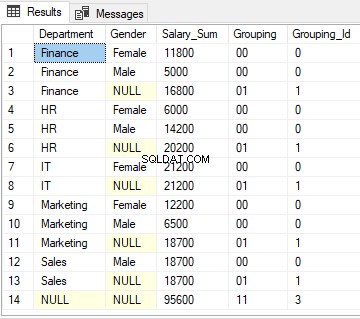
Pour la ligne 1, la fonction GROUPING ID renverra 0 puisque l'équivalent décimal de '00' est zéro.
Pour les lignes 3, 6, 8, 11 et 13, la fonction GROUPING_ID renvoie 1 puisque l'équivalent décimal de '01' est 1.
Enfin, pour la ligne 14, la fonction GROUPIND_ID renvoie 3, puisque l'équivalent binaire de '11' est 3.
La sortie du script ci-dessus ressemble à ceci :
Voir aussi :
Microsoft :Présentation de Grouping_ID
Microsoft :Présentation du regroupement
YouTube :Regroupement et Grouping_ID



