Si votre système repose sur PostgreSQL et que vous recherchez des solutions de clustering pour la haute disponibilité, nous souhaitons vous informer à l'avance qu'il s'agit d'une tâche complexe mais pas impossible à réaliser.
Compte tenu de vos exigences en matière de tolérance aux pannes, voici quelques solutions de clustering haute disponibilité parmi lesquelles choisir qui peuvent vous aider.
PostgreSQL ne supporte nativement aucune solution de clustering multi-maître comme MySQL ou Oracle. Néanmoins, de nombreux produits commerciaux et communautaires proposent cette implémentation, y compris la réplication et l'équilibrage de charge pour PostgreSQL.
Pour commencer, passons en revue quelques concepts de base :
Qu'est-ce que la haute disponibilité ?
La haute disponibilité fait référence à la durée pendant laquelle un service est disponible et est généralement définie par le niveau de performance convenu par une entreprise.
La redondance est la base de la haute disponibilité ; en cas d'incident, vous pouvez continuer à utiliser et à accéder aux systèmes sans problème.
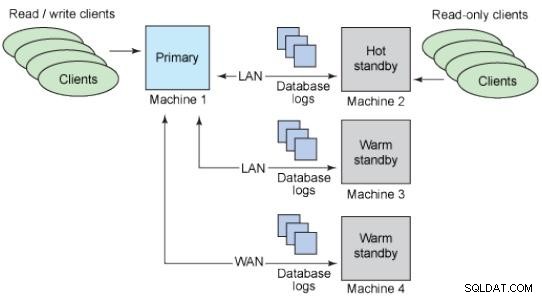
Récupération continue
Lorsqu'un incident survient, si vous deviez restaurer une sauvegarde puis appliquer les logs WAL (Write-Ahead Logging), le temps de récupération serait très élevé, et il ne serait pas hautement disponible.
Toutefois, si les sauvegardes et les journaux sont archivés sur un serveur de secours, vous pouvez appliquer les journaux au fur et à mesure qu'ils arrivent. Si les journaux sont envoyés et appliqués toutes les minutes, la base de contingence serait en récupération continue et aurait un état obsolète à la production d'au plus une minute.
Bases de données de secours
L'idée d'une base de données de secours est de conserver une copie d'une base de données de production qui contient toujours les mêmes données et est prête à être utilisée en cas d'incident.
Il existe plusieurs façons de classer une base de données de secours.
Par la nature de la réplication :
-
Veilles physiques :les blocs de disque sont copiés.
-
Secours logiques :streaming des modifications de données.
Par la synchronicité des transactions :
-
Asynchrone :il existe un risque de perte de données.
-
Synchrone :il n'y a aucune possibilité de perte de données ; Les commits dans le maître attendent la réponse du standby.
Par l'utilisation :
-
Warm standbys :ils ne prennent pas en charge les connexions.
-
Hot standby :prend en charge les connexions en lecture seule.
Clusters
Un cluster est un groupe d'hôtes travaillant ensemble et considérés comme un seul. Cela permet d'obtenir une évolutivité horizontale et la capacité de traiter plus de travail en ajoutant des serveurs.
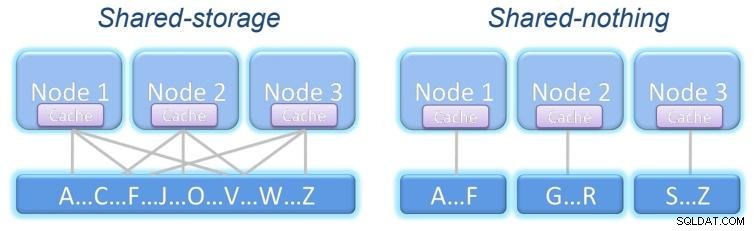
Il peut résister à la défaillance d'un nœud et continuer à fonctionner de manière transparente. Selon ce qui est partagé, il existe deux modèles de cluster :
-
Stockage partagé :tous les nœuds accèdent au même stockage avec les mêmes informations.
-
Rien partagé :chaque nœud a son propre stockage, qui peut ou non avoir les mêmes informations que l'autre nœuds, selon la structure de notre système.
Passons maintenant en revue certaines des options de clustering que nous avons dans PostgreSQL.
Périphérique de bloc répliqué distribué
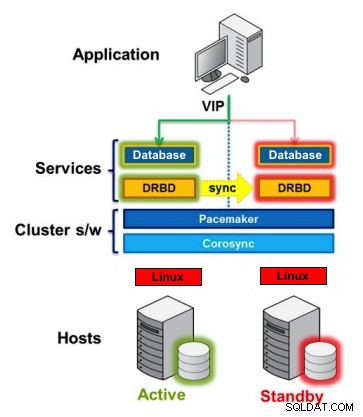
DRBD est un module du noyau Linux qui implémente la réplication de blocs synchrone à l'aide du réseau. En fait, il n'implémente pas de cluster et ne gère pas le basculement ou la surveillance. Vous avez besoin d'un logiciel complémentaire pour cela, par exemple, Corosync + Pacemaker + DRBD.
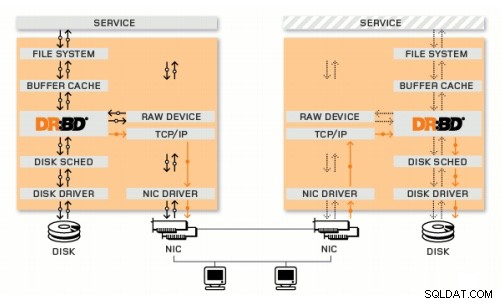
Exemple :
-
Corosync :gère les messages entre les hôtes.
-
Pacemaker :démarre et arrête les services, en s'assurant qu'ils ne s'exécutent que sur un seul hôte.
-
DRBD :synchronise les données au niveau des périphériques de bloc.
ClusterControl
ClusterControl est un logiciel de gestion et d'automatisation sans agent pour les clusters de bases de données. Il aide à déployer, surveiller, gérer et mettre à l'échelle votre serveur/cluster de base de données directement à partir de son interface utilisateur. Il peut gérer la plupart des tâches d'administration nécessaires à la maintenance des serveurs ou des clusters de bases de données.
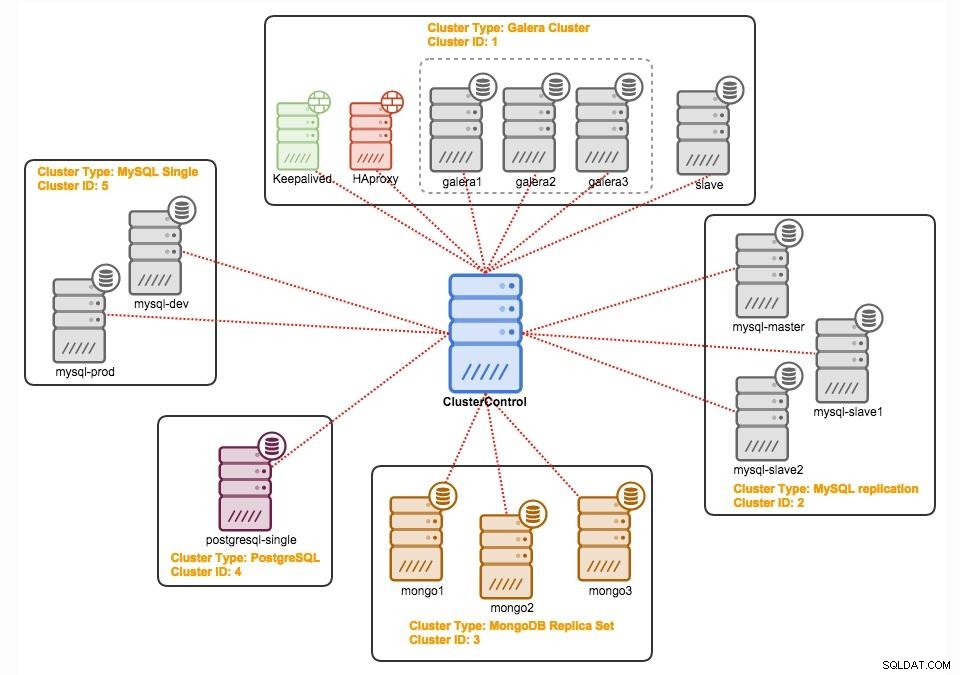
Avec ClusterControl, vous pouvez :
-
Déployez des bases de données autonomes, répliquées ou en cluster sur la pile technologique de votre choix.
-
Automatisez les basculements, la récupération et les tâches quotidiennes de manière uniforme sur les bases de données polyglottes et les infrastructures dynamiques.
-
Créez des sauvegardes complètes ou incrémentielles manuellement ou planifiez-les.
-
Effectuez une surveillance unifiée et complète en temps réel de l'ensemble de votre infrastructure de base de données et de serveur.
-
Ajouter ou supprimer facilement un nœud en une seule action.
-
Clonez votre cluster vers un autre centre de données/fournisseur de cloud
Si vous rencontrez un incident sur PostgreSQL, votre nœud Standby peut être automatiquement promu au rang de nœud principal.
Il s'agit d'un outil complet qui offre une gestion et une automatisation complètes du cycle de vie des opérations via une seule fenêtre. ClusterControl fournit également un essai gratuit de 30 jours afin que vous puissiez l'évaluer, sans aucune condition.
Rubyrep
Rubyrep est une solution de réplication asynchrone, multi-maître, multi-plateforme (implémentée en Ruby ou JRuby) et multi-SGBD (MySQL ou PostgreSQL).
Il est basé sur des déclencheurs et ne prend pas en charge DDL, les utilisateurs ou les autorisations. La simplicité d'utilisation et d'administration est son objectif premier.
Certaines fonctionnalités incluent :
-
Configuration simple
-
Installation simple
-
Indépendant de la plate-forme, indépendant de la conception de la table.
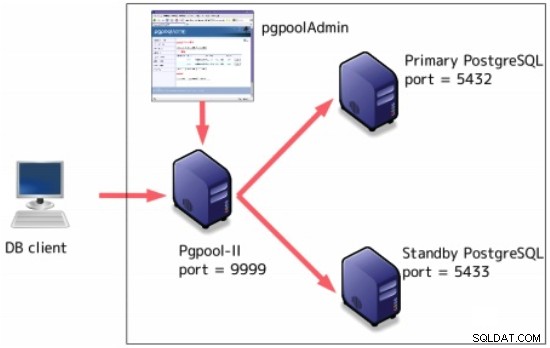
Pgpool-II
Pgpool-II est un middleware qui fonctionne entre les serveurs PostgreSQL et un client de base de données PostgreSQL.
Certaines fonctionnalités incluent :
-
Groupe de connexions
-
Réplication
-
Équilibrage de charge
-
Basculement automatique
-
Requêtes parallèles
Il peut être configuré en plus de la réplication en continu :
Bucardo
Bucardo offre une réplication maître-esclave en cascade asynchrone, basée sur les lignes, utilisant des déclencheurs et une mise en file d'attente dans la base de données, et une réplication maître-maître asynchrone, basée sur les lignes, utilisant des déclencheurs et une résolution de conflit personnalisée.
Bucardo nécessite une base de données dédiée et s'exécute comme un démon Perl qui communique avec cette base de données et toutes les autres bases de données impliquées dans la réplication. Il peut fonctionner en tant que multi-maître ou multi-esclave.
La réplication maître-esclave implique une ou plusieurs sources allant vers une ou plusieurs cibles. La source doit être PostgreSQL, mais les cibles peuvent être PostgreSQL, MySQL, Redis, Oracle, MariaDB, SQLite ou MongoDB.
Certaines fonctionnalités incluent :
-
Équilibrage de charge
-
Les esclaves ne sont pas contraints et peuvent être écrits
-
Réplication partielle
-
Réplication à la demande (les modifications peuvent être appliquées automatiquement ou lorsque vous le souhaitez)
-
Les esclaves peuvent être "préchauffés" pour une configuration rapide
Inconvénients :
-
Impossible de gérer DDL
-
Impossible de gérer des objets volumineux
-
Impossible de répliquer de manière incrémentielle des tables sans clé unique
-
Ne fonctionnera pas sur les versions antérieures à Postgres 8
Postgres-XC
Postgres-XC est un projet open-source pour fournir une solution de cluster PostgreSQL évolutive en écriture, synchrone, symétrique et transparente. Il s'agit d'un ensemble de composants de base de données étroitement couplés qui peuvent être installés sur plusieurs matériels ou machines virtuelles.
Évolutif en écriture signifie que Postgres-XC peut être configuré avec autant de serveurs de base de données que vous le souhaitez et gérer beaucoup plus d'écritures (mise à jour des instructions SQL) par rapport à ce qu'un seul serveur de base de données peut faire.
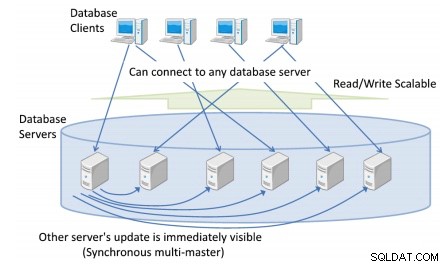
Vous pouvez avoir plusieurs serveurs de base de données auxquels les clients se connectent, offrant une vue unique et cohérente de la base de données à l'échelle du cluster.
Toute mise à jour de base de données à partir de n'importe quel serveur de base de données est immédiatement visible pour toutes les autres transactions exécutées sur différents maîtres.
Transparent signifie que vous n'avez pas à vous soucier de la façon dont vos données sont stockées dans plus d'un serveur de base de données en interne.
Vous pouvez configurer Postgres-XC pour qu'il s'exécute sur plusieurs serveurs. Vos données sont stockées de manière distribuée, partitionnée ou répliquée, selon votre choix pour chaque table. Lorsque vous émettez des requêtes, Postgres-XC détermine où les données cibles sont stockées et envoie les requêtes correspondantes aux serveurs contenant les données cibles.
Citus
Citus est un remplacement direct de PostgreSQL avec des fonctionnalités intégrées de haute disponibilité telles que le partitionnement automatique et la réplication. Citus partitionne votre base de données et réplique plusieurs copies de chaque partition sur le cluster de nœuds de base. Si un nœud du cluster devient indisponible, Citus redirige de manière transparente toutes les écritures ou requêtes vers l'un des autres nœuds qui hébergent une copie du fragment impacté.
Certaines fonctionnalités incluent :
-
Sharding logique automatique
-
Réplication intégrée
-
Réplication compatible datacenter pour reprise après sinistre
-
Tolérance aux pannes à mi-requête avec équilibrage de charge avancé
Vous pouvez augmenter la disponibilité de vos applications en temps réel optimisées par PostgreSQL et minimiser l'impact des pannes matérielles sur les performances. Vous pouvez y parvenir grâce à des outils de haute disponibilité intégrés qui minimisent les interventions manuelles coûteuses et sujettes aux erreurs.
PostgresXL
PostgresXL est une solution de clustering multimaître sans partage qui peut distribuer de manière transparente une table sur un ensemble de nœuds et exécuter des requêtes en parallèle avec ces nœuds. Il dispose d'un composant supplémentaire appelé Global Transaction Manager (GTM) pour fournir une vue globalement cohérente du cluster.
PostgresXL est un cluster de base de données SQL open source évolutif horizontalement, suffisamment flexible pour gérer différentes charges de travail de base de données :
-
Charges de travail intensives en écriture OLTP
-
Business Intelligence nécessitant le parallélisme MPP
-
Magasin de données opérationnel
-
Magasin clé-valeur
-
SIG géospatial
-
Environnements à charges de travail mixtes
-
Environnements mutualisés hébergés par un fournisseur

Composants :
-
Global Transaction Monitor (GTM) :le Global Transaction Monitor assure la cohérence des transactions à l'échelle du cluster.
-
Coordinateur :le coordinateur gère les sessions utilisateur et interagit avec GTM et les nœuds de données.
-
Nœud de données :le nœud de données est l'endroit où les données réelles sont stockées.
Conclusion
Il existe de nombreux autres produits disponibles pour implémenter votre environnement haute disponibilité pour PostgreSQL, mais vous devez être prudent avec :
-
Nouveaux produits, pas suffisamment testés
-
Projets abandonnés
-
Limites
-
Coûts de licence
-
Implémentations très complexes
-
Solutions dangereuses
Lors de la sélection de la solution que vous utiliserez, tenez également compte de votre infrastructure. Si vous n'avez qu'un seul serveur d'application, peu importe à quel point vous avez configuré la haute disponibilité des bases de données, si le serveur d'application tombe en panne, vous êtes inaccessible. Vous devez bien analyser les points de défaillance uniques de l'infrastructure et essayer de les résoudre.
En tenant compte de ces points, vous pouvez trouver une solution de cluster haute disponibilité qui s'adapte à vos besoins et exigences, sans prise de tête. Si vous recherchez des ressources HA supplémentaires pour votre base de données PG, consultez cet article sur le déploiement de PostgreSQL pour une haute disponibilité.
Pour rester informé sur les solutions de gestion de base de données et les meilleures pratiques, suivez-nous sur Twitter et LinkedIn et abonnez-vous à notre newsletter.