Les journaux de transactions sont un composant vital et important de l'architecture de la base de données. Dans cet article, nous aborderons les journaux de transactions SQL Server, leur importance et leur rôle dans la migration de la base de données.
Présentation
Parlons des différentes options pour effectuer des sauvegardes SQL Server. SQL Server prend en charge trois types de sauvegardes différents.
1. Complète
2. Différentiel
3. Journal des transactions
Avant de passer aux concepts de journal des transactions, discutons d'autres types de sauvegarde de base dans SQL Server.
Une sauvegarde complète est une copie de tout. Comme son nom l'indique, il sauvegardera tout. Il sauvegardera toutes les données, chaque objet de la base de données tel qu'un fichier, un groupe de fichiers, une table, etc. :- Une sauvegarde complète est une base pour tout autre type de sauvegarde.
Une sauvegarde différentielle sauvegardera les données qui ont changé depuis la dernière sauvegarde complète.
La troisième option est une sauvegarde du journal des transactions, qui enregistrera toutes les instructions que nous émettons dans la base de données dans le journal des transactions. Le journal des transactions est un mécanisme appelé « WAL » (Write-Ahead-Logging). Il écrit d'abord chaque élément d'information dans le journal des transactions, puis dans la base de données. En d'autres termes, le processus ne met généralement pas directement à jour la base de données. Il s'agit de la seule option complète disponible avec le modèle de récupération complète de la base de données. Dans d'autres modèles de récupération, les données sont soit partielles, soit il n'y a pas assez de données dans le journal. Par exemple, l'enregistrement de journal lors de l'enregistrement du début d'une nouvelle transaction (l'enregistrement de journal LOP_BEGIN_XACT) contiendra l'heure à laquelle la transaction a commencé, et les enregistrements de journal LOP_COMMIT_XACT (ou LOP_ABORT_XACT) enregistreront l'heure à laquelle la transaction a été validée (ou abandonnée).
Pour trouver les éléments internes du journal des transactions en ligne, vous pouvez interroger la fonction sys.fn_dblog.
La fonction système sys.fn_dblog accepte deux paramètres, le premier LSN de début et le LSN de fin de la transaction. Par défaut, il est défini sur NULL. S'il est défini sur NULL, il renverra tous les enregistrements du journal du fichier journal des transactions.
USE WideWorldImporters GO SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], [Log Record Fixed Length], [Log Record Length] [Transaction SID], [SPID], [Begin Time], * FROM fn_dblog(null,null)

Comme nous le savons tous, les transactions sont stockées au format binaire et non dans un format lisible. Pour lire le fichier journal des transactions hors ligne, vous pouvez utiliser fn_dump_dblog.
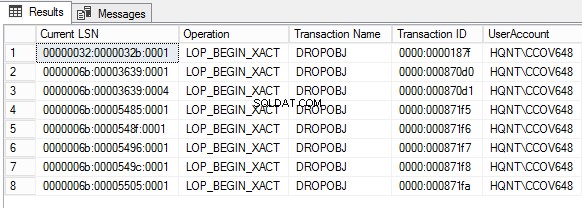
Interrogeons le fichier journal des transactions pour voir qui a supprimé l'objet à l'aide de fn_dump_dblog.
SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], SUSER_SNAME ([Transaction SID]) AS DBUser
FROM fn_dump_dblog (
NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn',
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT)
WHERE
Context IN ('LCX_NULL') AND Operation IN ('LOP_BEGIN_XACT')
AND [Transaction Name] LIKE '%DROP%'
Nous utiliserons la fonction fn_dblog() pour lire la partie active du journal des transactions afin de rechercher l'activité effectuée sur les données. Une fois le journal des transactions effacé, vous devez interroger les données d'un fichier journal à l'aide de fn_dump_dblog().
Cette fonction fournit le même jeu de lignes que fn_dblog(), mais possède des fonctionnalités intéressantes qui la rendent utile dans certains scénarios de dépannage et de récupération. Plus précisément, il peut lire non seulement le journal des transactions de la base de données actuelle, mais également les sauvegardes du journal des transactions sur disque ou sur bande.
Pour obtenir la liste des objets supprimés à l'aide du fichier de transaction, exécutez la requête suivante. Initialement, les données sont déversées dans la table temporaire. Dans certains cas, l'exécution de fun_dump_dblog() prend un peu plus de temps à s'exécuter. Il est donc préférable de capturer les données dans la table temporaire.
Pour obtenir un ID d'objet à partir de la colonne Informations sur le verrou, exécutez la requête suivante.
SELECT * INTO TEMP FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction ID] in( SELECT DISTINCT [Transaction ID] FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction Name] LIKE '%DROP%') and [Lock Information] like '%ACQUIRE_LOCK_SCH_M OBJECT%'
Pour obtenir un ID d'objet à partir de la colonne Informations sur le verrou, exécutez la requête suivante.
SELECT DISTINCT [Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4,
Substring([Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4) objectid
from temp
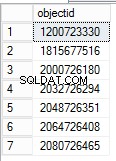
L'object_id peut être trouvé en manipulant la valeur de la colonne Lock Information. Afin de trouver le nom d'objet pour l'ID d'objet correspondant, restaurez la base de données à partir de la sauvegarde juste avant que la table ne soit supprimée. Après la restauration, vous pouvez interroger la vue système pour obtenir le nom de l'objet.
USE AdventureWorks2016; GO SELECT name, object_id from sys.objects WHERE object_id = '1815677516';
Voyons maintenant les différentes formes des mêmes détails de transaction en utilisant sys.dn_dblog, sys.fn_full_dblog. La fonction système fn_full_dblog fonctionne uniquement avec SQL Server 2017.
Requête pour récupérer les 10 meilleures transactions à l'aide de fn_dblog.
SELECT TOP 10 * FROM sys.fn_dblog(null,null)

À partir de SQL Server 2017, vous pouvez utiliser fn_full dblog.
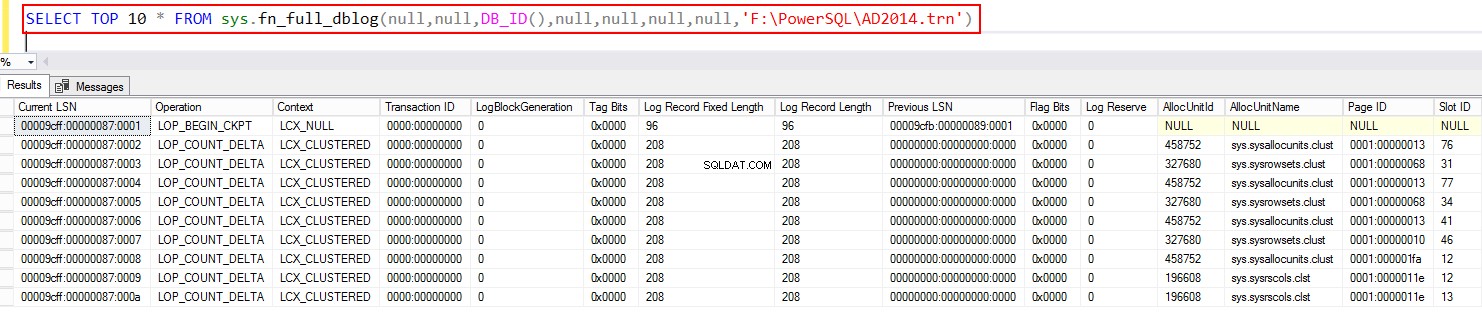
SELECT TOP 10 * FROM sys.fn_full_dblog(null,null,DB_ID(),null,null,null,null,NULL)

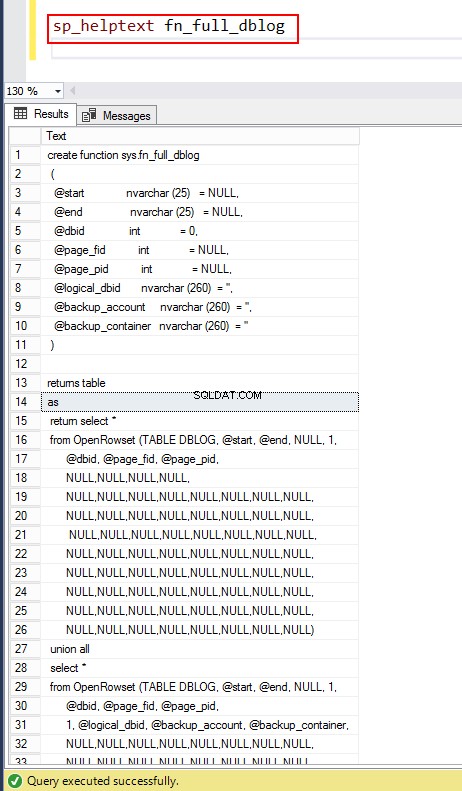
Vous pouvez approfondir la fonction système en utilisant le sp_helptext fn_full_dblog.
Ensuite, interrogez le fichier de sauvegarde à l'aide de la fonction système à l'aide de fn_full_dblog. Encore une fois, cela s'applique uniquement à partir de SQL Server 2017.
Restauration ponctuelle
Supposons que vous ayez la liste de la sauvegarde complète du journal, puis lorsque vous avez l'intention de restaurer les journaux, vous avez la possibilité d'effectuer une restauration ponctuelle des données. Ainsi, dans le processus de restauration du journal, vous n'avez pas nécessairement besoin de restaurer toutes les données, vous pouvez les restaurer jusqu'à, avant ou après toute transaction individuelle. Donc, si la base de données tombe en panne à un moment précis et que nous avons à la fois une sauvegarde complète et des sauvegardes de journaux, nous devrions pouvoir d'abord restaurer la sauvegarde complète, puis restaurer la sauvegarde du journal, et dans le processus, restaurer le dernier journal jusqu'à un certain temps , et cela laisserait la base de données dans l'état exact où elle se trouvait avant que ce problème ne se produise.
Les sauvegardes de journaux sont des VLDB (Very Large Database) assez courantes et les bases de données les plus critiques. Il est toujours recommandé de tester le processus de restauration. Chaque fois que vous effectuez des sauvegardes de base de données, il est conseillé de bien réfléchir au processus de restauration et de toujours tester le processus de restauration plus souvent.
Il est toujours bon d'alléger le test du processus de restauration de temps en temps, alors assurez-vous simplement que le processus passe normalement par les sauvegardes.
Scénarios
Parlons d'un scénario, lorsque vous avez besoin de restaurer une très grande base de données et que nous savons tous que cela peut normalement prendre plusieurs heures, et c'est quelque chose dont tout le monde devrait être conscient. Si vous prévoyez une migration de base de données sans aucune perte de données et avec des fenêtres d'indisponibilité plus petites, cela pourrait toujours être un problème assez important. Assurez-vous donc de vous fier à la sauvegarde du journal des transactions pour accélérer le processus.
Considérons un autre scénario dans lequel vous effectuez une migration de base de données côte à côte entre deux versions différentes de SQL Server ; vous êtes impliqué dans la migration de la base de données vers la même version logicielle sur la cible et cela inclut le transfert du système d'exploitation, de la base de données, de l'application et du réseau, etc. :- ; migration de la base de données d'un matériel à un autre ; changer à la fois le logiciel et le matériel. Le processus de migration de base de données est toujours un défi où la perte de données est toujours possible et soumise à l'environnement.
Meilleures pratiques de migration de base de données
Discutons des pratiques standard de gestion de la migration des bases de données.
La migration doit être effectuée de manière transactionnelle pour éviter les incohérences dans les données. Les étapes habituelles du processus de migration sont classiquement les suivantes :
- Arrêtez le service d'application :c'est là que commence le temps d'arrêt
- Lancez la sauvegarde du journal, cela dépend de vos besoins
- Mettez la base de données en mode de récupération afin qu'aucune autre modification ne soit apportée à la base de données
- Déplacer le ou les fichiers journaux
- Restaurer le(s) fichier(s) du journal des transactions de la base de données :à condition que vous ayez déjà restauré la sauvegarde complète de la base de données sur la cible et laissé la base de données en état de restauration.
- Clonez les identifiants et corrigez les utilisateurs orphelins
- Créer des emplois
- Installer l'application
- Configurer le réseau – Modifier les entrées DNS
- Reconfigurer les paramètres de l'application
- Démarrer le service d'application
- Tester l'application
Commencer
Dans cet article, nous verrons comment gérer la migration de bases de données OLTP très volumineuses. Nous discuterons des stratégies d'utilisation des techniques de serveur SQL et des outils tiers pour la sécurité des données, ainsi que d'une interruption nulle ou minimale de la disponibilité du système de production. Pendant le processus, il y a toujours une chance de perdre les données. Pensez-vous que la gestion transparente des transactions est une bonne stratégie ? Si "oui", quelles sont vos options préférées ?
Plongeons-nous dans les options disponibles :
- Sauvegarde et restauration
- Envoi de journaux
- Mise en miroir de bases de données
- Outils tiers
Sauvegarde et restauration
La technique de base de données de sauvegarde et de restauration est l'option la plus viable pour toute migration de base de données. S'il est planifié et testé correctement, nous éviterons de nombreuses erreurs de migration imprévues. Nous savons tous que la sauvegarde est un processus en ligne, il est facile de lancer la sauvegarde du journal des transactions en temps opportun pour réduire le nombre de transactions à fournir à la nouvelle base de données. Pendant la fenêtre de migration, nous pouvons limiter l'accès des utilisateurs à la base de données et lancer une dernière sauvegarde du journal et la transférer vers la destination. De cette façon, les temps d'arrêt peuvent être considérablement raccourcis.
Envoi de journaux
Nous comprenons tous l'importance des fichiers journaux dans le monde des bases de données. La technique d'envoi de journaux offre une bonne solution de récupération après sinistre et prend en charge un accès limité en lecture seule aux bases de données secondaires, pendant l'intervalle entre les tâches de restauration. Il s'agit essentiellement d'un concept de sauvegarde du journal des transactions et est rejoué sur une sauvegarde complète sur une autre base de données secondaire. Ces bases de données secondaires sont des copies en double de la base de données principale et restaurent en permanence les sauvegardes du journal des transactions sur leur propre copie, afin de la maintenir synchronisée avec la base de données principale. Comme la base de données secondaire se trouve sur un matériel séparé, en cas de défaillance de la base de données principale pour une raison quelconque, la copie entièrement sauvegardée du système est immédiatement disponible et le trafic réseau peut simplement être redirigé vers le serveur secondaire, sans qu'aucun utilisateur ne sache qu'un faute s'est produite. L'envoi de journaux fournit un moyen simple et efficace de gérer la migration dans une plus grande mesure dans la plupart des cas.
Mise en miroir
La mise en miroir de bases de données est également une option pour la migration de bases de données à condition que la source et la cible soient des mêmes versions et éditions. Essentiellement, la mise en miroir crée deux copies en double d'une base de données sur deux instances matérielles. Les transactions auraient lieu sur les deux bases de données simultanément. Vous avez la possibilité de mettre une base de données de production hors ligne, de basculer vers la version miroir de cette base de données et de permettre aux utilisateurs de continuer à accéder aux données comme si de rien n'était. En termes de mise en œuvre, nous avons affaire à un serveur principal, un serveur miroir et un témoin. Mais ce sera une fonctionnalité obsolète et elle sera supprimée des futures versions de SQL Server.
Résumé
Dans cet article, nous avons discuté des types de sauvegardes, de la sauvegarde du journal des transactions en détail, des normes de migration des données, du processus et de la stratégie, appris à utiliser les techniques SQL pour une gestion efficace des étapes de migration des données.
Le mécanisme d'écriture du journal des transactions WAL garantit que les transactions sont toujours écrites dans le fichier journal en premier. De cette manière, SQL Server garantit que les effets de toutes les transactions validées seront finalement écrits dans les fichiers de données (sur le disque) et que toute modification de données sur le disque provenant de transactions incomplètes sera ROLLBACK et non reflétée dans les fichiers de données.
Dans la plupart des cas, le retard de synchronisation des données est imprévu et la perte de données est permanente. Le plus souvent, tout dépend de la taille de la base de données et de l'infrastructure disponible. En tant que pratique recommandée, il est préférable d'exécuter les migrations manuellement plutôt que dans le cadre du déploiement pour garder les choses séparées afin que la sortie puisse être plus prévisible.
Personnellement, je préférerais l'envoi de journaux pour diverses raisons :vous pouvez effectuer une sauvegarde complète des données de l'ancien serveur bien à l'avance, les transférer sur le nouveau serveur, les restaurer, puis appliquer les transactions résiduelles (sauvegarde t-log ) du point jusqu'au moment de la transition. Le processus est en fait assez simple.
La migration de base de données n'est pas difficile si elle est effectuée correctement. J'espère que cet article vous aidera à exécuter les migrations de bases de données de manière plus fluide.