Un scénario courant dans de nombreuses applications client-serveur permet à l'utilisateur final de dicter l'ordre de tri des résultats. Certaines personnes veulent voir les articles les moins chers en premier, certaines veulent voir les articles les plus récents en premier, et certaines veulent les voir par ordre alphabétique. C'est une chose complexe à réaliser dans Transact-SQL car vous ne pouvez pas simplement dire :
CREATE PROCEDURE dbo.SortOnSomeTable @SortColumn NVARCHAR(128) = N'key_col', @SortDirection VARCHAR(4) = 'ASC' AS BEGIN ... ORDER BY @SortColumn; -- or ... ORDER BY @SortColumn @SortDirection; END GO
En effet, T-SQL n'autorise pas les variables à ces emplacements. Si vous utilisez simplement @SortColumn, vous recevez :
Msg 1008, niveau 16, état 1, ligne xL'élément SELECT identifié par le numéro ORDER BY 1 contient une variable dans le cadre de l'expression identifiant une position de colonne. Les variables ne sont autorisées que lorsqu'elles sont triées par une expression référençant un nom de colonne.
(Et lorsque le message d'erreur indique "une expression faisant référence à un nom de colonne", vous pouvez le trouver ambigu, et je suis d'accord. Mais je peux vous assurer que cela ne signifie pas qu'une variable est une expression appropriée.)
Si vous essayez d'ajouter @SortDirection, le message d'erreur est un peu plus opaque :
Msg 102, Niveau 15, État 1, Ligne xSyntaxe incorrecte près de '@SortDirection'.
Il existe plusieurs façons de contourner cela, et votre premier réflexe pourrait être d'utiliser du SQL dynamique ou d'introduire l'expression CASE. Mais comme pour la plupart des choses, il y a des complications qui peuvent vous forcer à emprunter une voie ou une autre. Alors, lequel devriez-vous utiliser? Explorons comment ces solutions pourraient fonctionner et comparons les impacts sur les performances pour quelques approches différentes.
Exemple de données
En utilisant une vue de catalogue que nous comprenons probablement tous assez bien, sys.all_objects, j'ai créé la table suivante basée sur une jointure croisée, limitant la table à 100 000 lignes (je voulais des données qui remplissaient de nombreuses pages mais qui ne prenaient pas beaucoup de temps pour interroger et tester):
CREATE DATABASE OrderBy;
GO
USE OrderBy;
GO
SELECT TOP (100000)
key_col = ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- a BIGINT with clustered index
s1.[object_id], -- an INT without an index
name = s1.name -- an NVARCHAR with a supporting index
COLLATE SQL_Latin1_General_CP1_CI_AS,
type_desc = s1.type_desc -- an NVARCHAR(60) without an index
COLLATE SQL_Latin1_General_CP1_CI_AS,
s1.modify_date -- a datetime without an index
INTO dbo.sys_objects
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]; (L'astuce COLLATE est due au fait que de nombreuses vues de catalogue ont des colonnes différentes avec des classements différents, ce qui garantit que les deux colonnes correspondront aux fins de cette démo.)
Ensuite, j'ai créé une paire d'index cluster/non cluster typique qui pourrait exister sur une telle table, avant l'optimisation (je ne peux pas utiliser object_id pour la clé, car la jointure croisée crée des doublons) :
CREATE UNIQUE CLUSTERED INDEX key_col ON dbo.sys_objects(key_col); CREATE INDEX name ON dbo.sys_objects(name);
Cas d'utilisation
Comme mentionné ci-dessus, les utilisateurs peuvent vouloir voir ces données triées de différentes manières, alors exposons quelques cas d'utilisation typiques que nous voulons prendre en charge (et par prise en charge, je veux dire démontrer) :
- Ordonné par key_col croissant ** par défaut si l'utilisateur ne s'en soucie pas
- Classé par object_id (croissant/décroissant)
- Classé par nom (croissant/décroissant)
- Classé par type_desc (croissant/décroissant)
- Classé par modify_date (croissant/décroissant)
Nous laisserons l'ordre key_col par défaut car il devrait être le plus efficace si l'utilisateur n'a pas de préférence; étant donné que key_col est un substitut arbitraire qui ne devrait rien signifier à l'utilisateur (et peut même ne pas lui être exposé), il n'y a aucune raison d'autoriser le tri inversé sur cette colonne.
Approches qui ne fonctionnent pas
L'approche la plus courante que je vois lorsque quelqu'un commence à s'attaquer à ce problème consiste à introduire une logique de contrôle de flux dans la requête. Ils s'attendent à pouvoir le faire :
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
IF @SortColumn = 'key_col'
key_col
IF @SortColumn = 'object_id'
[object_id]
IF @SortColumn = 'name'
name
...
IF @SortDirection = 'ASC'
ASC
ELSE
DESC; Cela ne fonctionne évidemment pas. Ensuite, je vois CASE être introduit de manière incorrecte, en utilisant une syntaxe similaire :
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
WHEN 'name' THEN name
...
END CASE @SortDirection WHEN 'ASC' THEN ASC ELSE DESC END; C'est plus proche, mais cela échoue pour deux raisons. La première est que CASE est une expression qui renvoie exactement une valeur d'un type de données spécifique ; cela fusionne les types de données qui sont incompatibles et cassera donc l'expression CASE. L'autre est qu'il n'y a aucun moyen d'appliquer conditionnellement la direction de tri de cette façon sans utiliser SQL dynamique.
Approches qui fonctionnent
Les trois approches principales que j'ai vues sont les suivantes :
Regrouper les types et directions compatibles
Pour utiliser CASE avec ORDER BY, il doit y avoir une expression distincte pour chaque combinaison de types et de directions compatibles. Dans ce cas, nous devrions utiliser quelque chose comme ceci :
CREATE PROCEDURE dbo.Sort_CaseExpanded
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN key_col
WHEN 'object_id' THEN [object_id]
END
END DESC,
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
END
END DESC,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'ASC' THEN modify_date
END,
CASE WHEN @SortColumn = 'modify_date'
AND @SortDirection = 'DESC' THEN modify_date
END DESC;
END Vous pourriez dire, wow, c'est un vilain morceau de code, et je serais d'accord avec vous. Je pense que c'est la raison pour laquelle beaucoup de gens cachent leurs données sur le front-end et laissent le niveau de présentation s'occuper de jongler dans différents ordres. :-)
Vous pouvez réduire un peu plus cette logique en convertissant tous les types non-chaînes en chaînes qui seront triées correctement, par exemple
CREATE PROCEDURE dbo.Sort_CaseCollapsed
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY
CASE WHEN @SortDirection = 'ASC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END,
CASE WHEN @SortDirection = 'DESC' THEN
CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
END DESC;
END Pourtant, c'est un gâchis assez laid, et vous devez répéter les expressions deux fois pour gérer les différentes directions de tri. Je soupçonnerais également que l'utilisation de OPTION RECOMPILE sur cette requête vous empêcherait d'être piqué par le reniflage de paramètres. Sauf dans le cas par défaut, ce n'est pas comme si la majorité du travail effectué ici allait être de la compilation.
Appliquer un classement à l'aide des fonctions de fenêtre
J'ai découvert cette astuce d'AndriyM, bien qu'elle soit plus utile dans les cas où toutes les colonnes de commande potentielles sont de types compatibles, sinon l'expression utilisée pour ROW_NUMBER() est tout aussi complexe. La partie la plus intelligente est que pour basculer entre l'ordre croissant et décroissant, nous multiplions simplement le ROW_NUMBER() par 1 ou -1. Nous pouvons l'appliquer dans cette situation comme suit :
CREATE PROCEDURE dbo.Sort_RowNumber
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
;WITH x AS
(
SELECT key_col, [object_id], name, type_desc, modify_date,
rn = ROW_NUMBER() OVER (
ORDER BY CASE @SortColumn
WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12)
WHEN 'object_id' THEN
RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0')
+ REPLICATE('0', 23) + RTRIM([object_id]), 24)
WHEN 'name' THEN name
WHEN 'type_desc' THEN type_desc
WHEN 'modify_date' THEN CONVERT(CHAR(19), modify_date, 120)
END
) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END
FROM dbo.sys_objects
)
SELECT key_col, [object_id], name, type_desc, modify_date
FROM x
ORDER BY rn;
END
GO Encore une fois, OPTION RECOMPILE peut aider ici. En outre, vous remarquerez peut-être dans certains de ces cas que les liens sont gérés différemment par les différents plans - lors de la commande par nom, par exemple, vous verrez généralement key_col apparaître dans l'ordre croissant dans chaque ensemble de noms en double, mais vous pouvez également voir les valeurs mélangées. Pour fournir un comportement plus prévisible en cas d'égalité, vous pouvez toujours ajouter une clause ORDER BY supplémentaire. Notez que si vous deviez ajouter key_col au premier exemple, vous devrez en faire une expression afin que key_col ne soit pas répertorié deux fois dans ORDER BY (vous pouvez le faire en utilisant key_col + 0, par exemple).
SQL dynamique
Beaucoup de gens ont des réserves sur le SQL dynamique - c'est impossible à lire, c'est un terreau fertile pour l'injection SQL, cela conduit à un gonflement du cache du plan, cela va à l'encontre de l'utilisation de procédures stockées... Certaines d'entre elles sont tout simplement fausses, et certaines d'entre elles sont faciles à atténuer. J'ai ajouté ici une validation qui pourrait tout aussi bien être ajoutée à l'une des procédures ci-dessus :
CREATE PROCEDURE dbo.Sort_DynamicSQL
@SortColumn NVARCHAR(128) = N'key_col',
@SortDirection VARCHAR(4) = 'ASC'
AS
BEGIN
SET NOCOUNT ON;
-- reject any invalid sort directions:
IF UPPER(@SortDirection) NOT IN ('ASC','DESC')
BEGIN
RAISERROR('Invalid parameter for @SortDirection: %s', 11, 1, @SortDirection);
RETURN -1;
END
-- reject any unexpected column names:
IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date')
BEGIN
RAISERROR('Invalid parameter for @SortColumn: %s', 11, 1, @SortColumn);
RETURN -1;
END
SET @SortColumn = QUOTENAME(@SortColumn);
DECLARE @sql NVARCHAR(MAX);
SET @sql = N'SELECT key_col, [object_id], name, type_desc, modify_date
FROM dbo.sys_objects
ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';';
EXEC sp_executesql @sql;
END Comparaisons des performances
J'ai créé une procédure stockée wrapper pour chaque procédure ci-dessus, afin de pouvoir facilement tester tous les scénarios. Les quatre procédures wrapper ressemblent à ceci, le nom de la procédure variant bien sûr :
CREATE PROCEDURE dbo.Test_Sort_CaseExpanded AS BEGIN SET NOCOUNT ON; EXEC dbo.Sort_CaseExpanded; -- default EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC'; END
Ensuite, à l'aide de SQL Sentry Plan Explorer, j'ai généré des plans d'exécution réels (et les mesures qui vont avec) avec les requêtes suivantes, et j'ai répété le processus 10 fois pour résumer la durée totale :
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; EXEC dbo.Test_Sort_CaseExpanded; --EXEC dbo.Test_Sort_CaseCollapsed; --EXEC dbo.Test_Sort_RowNumber; --EXEC dbo.Test_Sort_DynamicSQL; GO 10
J'ai également testé les trois premiers cas avec OPTION RECOMPILE (cela n'a pas beaucoup de sens pour le cas SQL dynamique, car nous savons que ce sera un nouveau plan à chaque fois), et les quatre cas avec MAXDOP 1 pour éliminer les interférences de parallélisme. Voici les résultats :
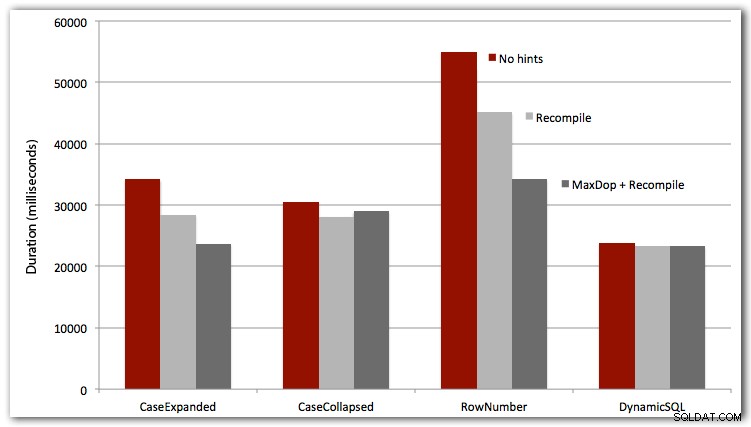
Conclusion
Pour des performances absolues, le SQL dynamique gagne à chaque fois (mais seulement par une petite marge sur cet ensemble de données). L'approche ROW_NUMBER(), bien qu'intelligente, a été perdante à chaque test (désolé AndriyM).
Cela devient encore plus amusant lorsque vous souhaitez introduire une clause WHERE, sans parler de la pagination. Ces trois éléments sont comme la tempête parfaite pour introduire de la complexité dans ce qui commence par une simple requête de recherche. Plus votre requête comporte de permutations, plus vous souhaiterez probablement jeter la lisibilité par la fenêtre et utiliser le SQL dynamique en combinaison avec le paramètre "optimiser pour les charges de travail ad hoc" afin de minimiser l'impact des plans à usage unique dans votre cache de plan.