Dans la première partie de ce blog, nous avons couvert une procédure de déploiement de MySQL InnoDB Cluster avec un exemple sur la façon dont les applications peuvent se connecter au cluster via un port de lecture/écriture dédié.
Dans cette procédure pas à pas, nous allons montrer des exemples sur la façon de surveiller, gérer et mettre à l'échelle le cluster InnoDB dans le cadre des opérations de maintenance en cours du cluster. Nous utiliserons le même cluster que celui que nous avons déployé dans la première partie du blog. Le schéma suivant montre notre architecture :
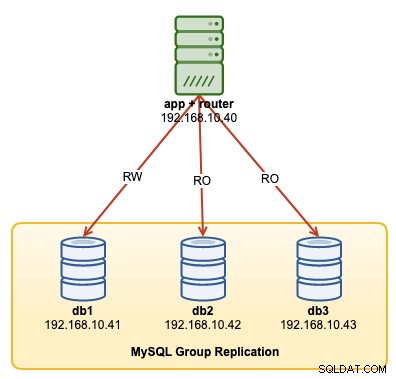
Nous avons une réplication de groupe MySQL à trois nœuds et un serveur d'applications fonctionnant avec Routeur MySQL. Tous les serveurs fonctionnent sur Ubuntu 18.04 Bionic.
Options de commande de cluster MySQL InnoDB
Avant d'aller plus loin avec quelques exemples et explications, il est bon de savoir que vous pouvez obtenir une explication de chaque fonction du cluster MySQL pour le composant cluster en utilisant la fonction help(), comme indiqué ci-dessous :
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()La liste suivante montre les fonctions disponibles sur MySQL Shell 8.0.18, pour MySQL Community Server 8.0.18 :
- addInstance(instance[, options])- ajoute une instance au cluster.
- checkInstanceState(instance) : vérifie l'état du gtid de l'instance par rapport au cluster.
- describe()- Décrit la structure du cluster.
- disconnect()- Déconnecte toutes les sessions internes utilisées par l'objet cluster.
- dissolve([options])- Désactive la réplication et désenregistre les ReplicaSets du cluster.
- forceQuorumUsingPartitionOf(instance[, password])- Restaure le cluster à partir de la perte de quorum.
- getName()- Récupère le nom du cluster.
- help([member])- Fournit de l'aide sur cette classe et ses membres
- options([options]) :répertorie les options de configuration du cluster.
- rejoinInstance(instance[, options]) : rejoint une instance au cluster.
- removeInstance(instance[, options])- Supprime une instance du cluster.
- rescan([options])- Rescanne le cluster.
- resetRecoveryAccountsPassword(options)- Réinitialiser le mot de passe des comptes de récupération du cluster.
- setInstanceOption(instance, option, value) : modifie la valeur d'une option de configuration dans un membre du cluster.
- setOption(option, value)- Modifie la valeur d'une option de configuration pour l'ensemble du cluster.
- setPrimaryInstance(instance)- Élit un membre de cluster spécifique comme nouveau principal.
- status([options]) – Décrivez l'état du cluster.
- switchToMultiPrimaryMode()- Bascule le cluster en mode multi-primaire.
- switchToSinglePrimaryMode([instance])- Bascule le cluster en mode primaire unique.
Nous allons examiner la plupart des fonctions disponibles pour nous aider à surveiller, gérer et faire évoluer le cluster.
Surveillance des opérations du cluster MySQL InnoDB
État du cluster
Pour vérifier l'état du cluster, utilisez d'abord la ligne de commande du shell MySQL, puis connectez-vous en tant qu'example@sqldat.com{one-of-the-db-nodes} :
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");Ensuite, créez un objet appelé "cluster" et déclarez-le comme objet global "dba" qui donne accès aux fonctions d'administration du cluster InnoDB à l'aide de l'AdminAPI (consultez la documentation de l'API MySQL Shell) :
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>Ensuite, nous pouvons utiliser le nom de l'objet pour appeler les fonctions de l'API pour l'objet "dba" :
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}La sortie est assez longue mais nous pouvons la filtrer en utilisant la structure de la carte. Par exemple, si nous souhaitons afficher le délai de réplication pour db3 uniquement, nous pourrions procéder comme suit :
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Notez que le décalage de réplication est quelque chose qui se produira dans la réplication de groupe, en fonction de l'intensité d'écriture du membre principal dans le jeu de répliques et des variables group_replication_flow_control_*. Nous n'allons pas aborder ce sujet en détail ici. Consultez cet article de blog pour en savoir plus sur les performances de réplication de groupe et le contrôle de flux.
Une autre fonction similaire est la fonction describe(), mais celle-ci est un peu plus simple. Il décrit la structure du cluster, y compris toutes ses informations, ReplicaSets et Instances :
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}De même, nous pouvons filtrer la sortie JSON à l'aide de la structure de la carte :
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryLorsque le nœud principal est tombé en panne (dans ce cas, il s'agit de db1), la sortie a renvoyé ce qui suit :
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Faites attention au statut OK_NO_TOLERANCE, où le cluster est toujours opérationnel mais il ne peut plus tolérer d'échec après qu'un nœud sur trois ne soit plus disponible. Le rôle principal a été repris automatiquement par db2 et les connexions à la base de données de l'application seront redirigées vers le nœud approprié si elles se connectent via MySQL Router. Une fois que db1 revient en ligne, nous devrions voir l'état suivant :
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Il montre que db1 est maintenant disponible mais a servi de secondaire avec la lecture seule activée. Le rôle principal est toujours attribué à db2 jusqu'à ce que quelque chose se passe mal sur le nœud, où il sera automatiquement basculé vers le prochain nœud disponible.
Vérifier l'état de l'instance
Nous pouvons vérifier l'état d'un nœud MySQL avant de planifier son ajout au cluster en utilisant la fonction checkInstanceState(). Il analyse les GTID exécutés par l'instance avec les GTID exécutés/purgés sur le cluster pour déterminer si l'instance est valide pour le cluster.
Ce qui suit montre l'état de l'instance de db3 lorsqu'elle était en mode autonome, avant une partie du cluster :
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Si le nœud fait déjà partie du cluster, vous devriez obtenir ce qui suit :
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Surveiller tout état "interrogeable"
Avec MySQL Shell, nous pouvons désormais utiliser les commandes intégrées \show et \watch pour surveiller toute requête administrative en temps réel. Par exemple, nous pouvons obtenir la valeur en temps réel des threads connectés en utilisant :
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';Ou obtenez la liste de processus MySQL actuelle :
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTNous pouvons ensuite utiliser la commande \watch pour exécuter un rapport de la même manière que la commande \show, mais elle actualise les résultats à intervalles réguliers jusqu'à ce que vous annuliez la commande à l'aide de Ctrl + C. Comme indiqué dans les exemples suivants :
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTL'intervalle d'actualisation par défaut est de 2 secondes. Vous pouvez modifier la valeur en utilisant l'indicateur --interval et spécifier une valeur comprise entre 0,1 et 86 400.
Opérations de gestion du cluster MySQL InnoDB
Basculement principal
L'instance principale est le nœud qui peut être considéré comme le leader dans un groupe de réplication, qui a la capacité d'effectuer des opérations de lecture et d'écriture. Une seule instance principale par cluster est autorisée en mode de topologie à une seule instance principale. Cette topologie est également connue sous le nom de jeu de réplicas et est le mode de topologie recommandé pour la réplication de groupe avec protection contre les conflits de verrouillage.
Pour effectuer le basculement de l'instance principale, connectez-vous à l'un des nœuds de la base de données en tant qu'utilisateur clusteradmin et spécifiez le nœud de la base de données que vous souhaitez promouvoir à l'aide de la fonction setPrimaryInstance() :
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Nous venons de promouvoir db1 en tant que nouveau composant principal, remplaçant db2 tandis que db3 reste le nœud secondaire.
Arrêter le cluster
La meilleure façon d'arrêter le cluster proprement en arrêtant d'abord le service MySQL Router (s'il est en cours d'exécution) sur le serveur d'applications :
$ myrouter/stop.shL'étape ci-dessus fournit une protection du cluster contre les écritures accidentelles par les applications. Ensuite, arrêtez un nœud de base de données à la fois à l'aide de la commande d'arrêt standard de MySQL, ou effectuez l'arrêt du système comme vous le souhaitez :
$ systemctl stop mysqlDémarrer le cluster après un arrêt
Si votre cluster souffre d'une panne complète ou si vous souhaitez démarrer le cluster après un arrêt propre, vous pouvez vous assurer qu'il est reconfiguré correctement à l'aide de la fonction dba.rebootClusterFromCompleteOutage(). Il ramène simplement un cluster EN LIGNE lorsque tous les membres sont HORS LIGNE. Dans le cas où un cluster est complètement arrêté, les instances doivent être démarrées et alors seulement le cluster peut être démarré.
Ainsi, assurez-vous que tous les serveurs MySQL sont démarrés et en cours d'exécution. Sur chaque nœud de la base de données, vérifiez si le processus mysqld est en cours d'exécution :
$ ps -ef | grep -i mysqlEnsuite, choisissez un serveur de base de données comme nœud principal et connectez-vous via le shell MySQL :
MySQL|JS> shell.connect("example@sqldat.com:3306");Exécutez la commande suivante à partir de cet hôte pour les démarrer :
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Les questions suivantes vous seront posées :
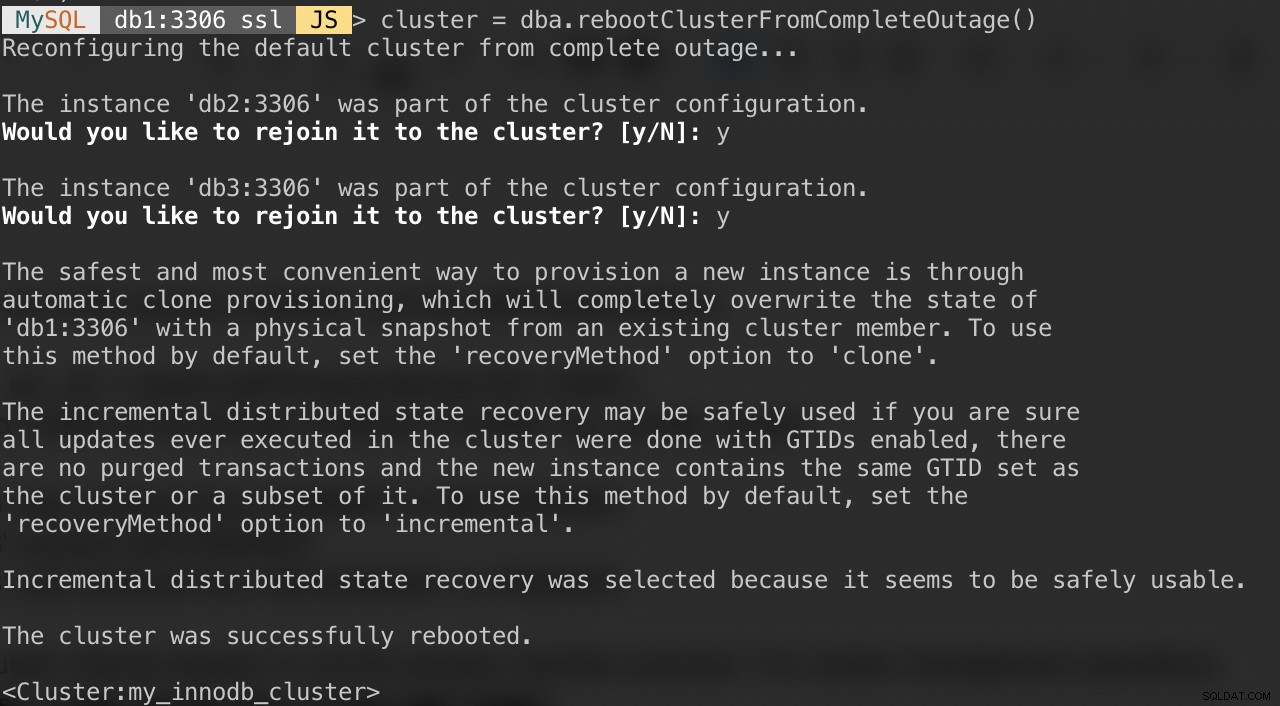
Une fois les étapes ci-dessus terminées, vous pouvez vérifier l'état du cluster :
MySQL|db1:3306 ssl|JS> cluster.status()À ce stade, db1 est le nœud principal et le rédacteur. Les autres seront les membres secondaires. Si vous souhaitez démarrer le cluster avec db2 ou db3 comme primaire, vous pouvez utiliser la fonction shell.connect() pour vous connecter au nœud correspondant et effectuer le rebootClusterFromCompleteOutage() à partir de ce nœud particulier.
Vous pouvez ensuite démarrer le service MySQL Router (s'il ne l'est pas) et laisser l'application se reconnecter au cluster.
Définition des options de membre et de cluster
Pour obtenir les options à l'échelle du cluster, exécutez simplement :
MySQL|db1:3306 ssl|JS> cluster.options()Ce qui précède répertorie les options globales pour le jeu de répliques ainsi que les options individuelles par membre du cluster. Cette fonction modifie une option de configuration InnoDB Cluster dans tous les membres du cluster. Les options prises en charge sont :
- clusterName :valeur de chaîne pour définir le nom du cluster.
- exitStateAction :valeur de chaîne indiquant l'action d'état de sortie de réplication de groupe.
- memberWeight :valeur entière avec un pourcentage de pondération pour l'élection primaire automatique en cas de basculement.
- failoverConsistency :valeur de chaîne indiquant les garanties de cohérence fournies par le cluster.
- cohérence : valeur de chaîne indiquant les garanties de cohérence fournies par le cluster.
- expelTimeout :valeur entière pour définir la période de temps en secondes pendant laquelle les membres du cluster doivent attendre un membre qui ne répond pas avant de l'expulser du cluster.
- autoRejoinTries :valeur entière pour définir le nombre de fois qu'une instance tentera de rejoindre le cluster après avoir été expulsée.
- disableClone :valeur booléenne utilisée pour désactiver l'utilisation du clone sur le cluster.
Semblable à d'autres fonctions, la sortie peut être filtrée dans la structure de la carte. La commande suivante répertorie uniquement les options pour db2 :
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]Vous pouvez également obtenir la liste ci-dessus en utilisant la fonction help() :
MySQL|db1:3306 ssl|JS> cluster.help("setOption")La commande suivante montre un exemple pour définir une option appelée memberWeight sur 60 (au lieu de 50) sur tous les membres :
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.Nous pouvons également effectuer la gestion de la configuration automatiquement via MySQL Shell en utilisant la fonction setInstanceOption() et transmettre l'hôte de la base de données, le nom et la valeur de l'option en conséquence :
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)Les options prises en charge sont :
- exitStateAction : valeur de chaîne indiquant l'action d'état de sortie de réplication de groupe.
- memberWeight :valeur entière avec un pourcentage de pondération pour l'élection primaire automatique en cas de basculement.
- autoRejoinTries :valeur entière pour définir le nombre de fois qu'une instance tentera de rejoindre le cluster après avoir été expulsée.
- étiqueter un identifiant de chaîne de l'instance.
Passage en mode multi-primaire/mono-primaire
Par défaut, InnoDB Cluster est configuré avec un seul primaire, un seul membre capable d'effectuer des lectures et des écritures à un moment donné. Il s'agit de la méthode la plus sûre et la plus recommandée pour exécuter le cluster et convient à la plupart des charges de travail.
Cependant, si la logique de l'application peut gérer les écritures distribuées, il est probablement judicieux de passer en mode multi-primaire, où tous les membres du cluster peuvent traiter les lectures et les écritures en même temps. Pour passer du mode mono-primaire au mode multi-primaire, il suffit d'utiliser la fonction switchToMultiPrimaryMode() :
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Vérifiez avec :
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}En mode multi-primaire, tous les nœuds sont principaux et capables de traiter les lectures et les écritures. Lors de l'envoi d'une nouvelle connexion via MySQL Router sur le port à écriture unique (6446), la connexion sera envoyée à un seul nœud, comme dans cet exemple, db1 :
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Si l'application se connecte au port multi-écrivain (6447), la connexion sera équilibrée en charge via l'algorithme round robin vers tous les membres :
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Comme vous pouvez le voir dans la sortie ci-dessus, tous les nœuds sont capables de traiter les lectures et les écritures avec read_only =OFF. Vous pouvez distribuer des écritures sécurisées à tous les membres en vous connectant au port multi-écrivain (6447) et envoyer les écritures conflictuelles ou lourdes au port mono-écrivain (6446).
Pour revenir au mode principal unique, utilisez la fonction switchToSinglePrimaryMode() et spécifiez un membre comme nœud principal. Dans cet exemple, nous avons choisi db1 :
MySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.À ce stade, db1 est maintenant le nœud principal configuré avec la lecture seule désactivée et le reste sera configuré comme secondaire avec la lecture seule activée.
Opérations de mise à l'échelle du cluster MySQL InnoDB
Scaling Up (Ajout d'un nouveau nœud de base de données)
Lors de l'ajout d'une nouvelle instance, un nœud doit d'abord être provisionné avant d'être autorisé à participer au groupe de réplication. Le processus de provisionnement sera géré automatiquement par MySQL. En outre, vous pouvez d'abord vérifier l'état de l'instance si le nœud est valide pour rejoindre le cluster en utilisant la fonction checkInstanceState() comme expliqué précédemment.
Pour ajouter un nouveau nœud de base de données, utilisez la fonction addInstances() et spécifiez l'hôte :
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Voici ce que vous obtiendriez lors de l'ajout d'une nouvelle instance :
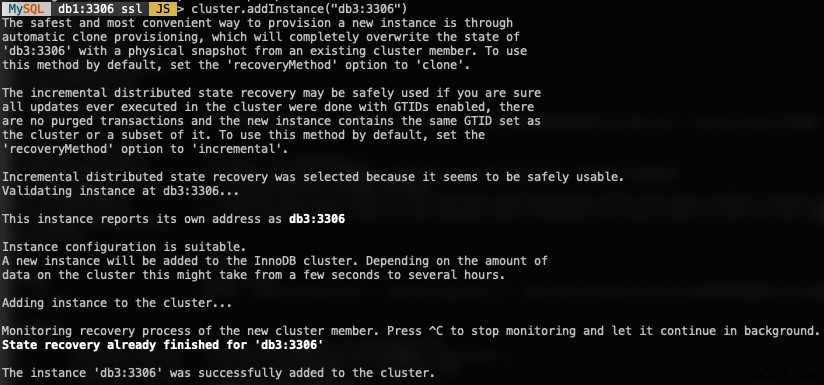
Vérifiez la nouvelle taille de cluster avec :
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router inclura automatiquement le nœud ajouté, db3, dans l'ensemble d'équilibrage de charge.
Réduction d'échelle (suppression d'un nœud)
Pour supprimer un nœud, connectez-vous à l'un des nœuds de la base de données à l'exception de celui que nous allons supprimer et utilisez la fonction removeInstance() avec le nom de l'instance de la base de données :
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")Ce qui suit est ce que vous obtiendriez lors de la suppression d'une instance :
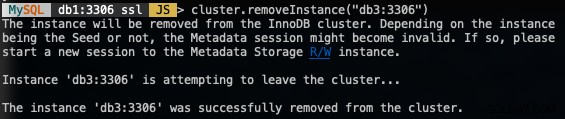
Vérifiez la nouvelle taille de cluster avec :
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router exclura automatiquement le nœud supprimé, db3 de l'ensemble d'équilibrage de charge.
Ajout d'un nouvel esclave de réplication
Nous pouvons faire évoluer le cluster InnoDB avec des répliques esclaves de réplication asynchrone à partir de n'importe quel nœud du cluster. Un esclave est faiblement couplé au cluster et pourra gérer une charge importante sans affecter les performances du cluster. L'esclave peut également être une copie dynamique de la base de données à des fins de reprise après sinistre. En mode multi-primaire, vous pouvez utiliser l'esclave en tant que processeur MySQL dédié en lecture seule pour faire évoluer la charge de travail de lecture, effectuer des opérations d'analyse ou en tant que serveur de sauvegarde dédié.
Sur le serveur esclave, téléchargez le dernier package de configuration APT, installez-le (choisissez MySQL 8.0 dans l'assistant de configuration), installez la clé APT, mettez à jour le repolist et installez le serveur MySQL.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellModifiez le fichier de configuration MySQL pour préparer le serveur pour l'esclave de réplication. Ouvrez le fichier de configuration via l'éditeur de texte :
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfEt ajoutez les lignes suivantes :
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Redémarrez le serveur MySQL sur l'esclave pour appliquer les modifications :
$ systemctl restart mysqlSur l'un des serveurs du cluster InnoDB (nous avons choisi db3), créez un utilisateur esclave de réplication suivi d'un vidage MySQL complet :
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlTransférez le fichier de vidage de db3 vers l'esclave :
$ scp dump.sql example@sqldat.com:~Et effectuez la restauration sur l'esclave :
$ mysql -uroot -p < dump.sqlAvec master-data=1, notre fichier de vidage MySQL configurera automatiquement la valeur GTID exécutée et purgée. Nous pouvons le vérifier avec la déclaration suivante sur le serveur esclave après la restauration :
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Cela semble bon. On peut alors configurer le lien de réplication et démarrer les threads de réplication sur l'esclave :
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Vérifiez l'état de la réplication et assurez-vous que l'état suivant renvoie "Oui" :
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...À ce stade, notre architecture ressemble maintenant à ceci :
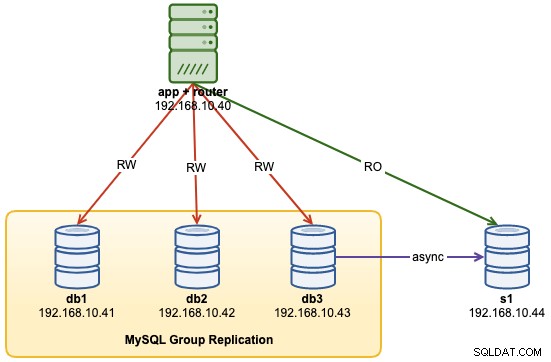
Problèmes courants avec les clusters MySQL InnoDB
Épuisement de la mémoire
Lors de l'utilisation de MySQL Shell avec MySQL 8.0, nous obtenions constamment l'erreur suivante lorsque les instances étaient configurées avec 1 Go de RAM :
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)La mise à niveau de la RAM de chaque hôte à 2 Go de RAM a résolu le problème. Apparemment, les composants MySQL 8.0 nécessitent plus de RAM pour fonctionner efficacement.
Connexion perdue au serveur MySQL
In case the primary node goes down, you would probably see the "lost connection to MySQL server error" when trying to query something on the current session:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.
Conclusion
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).



