Peu importe de quel côté de l'équation vous vous trouvez, il est parfois difficile de trouver une personne qualifiée pour un travail spécifique. Dans cet article, nous examinons un modèle de données pour aider les recruteurs et les services RH à rester organisés pendant le processus d'embauche.
La plupart d'entre nous ont été impliqués dans le processus d'embauche - le plus souvent en tant que demandeur d'emploi. Cependant, nous pouvons également nous retrouver impliqués du côté de l'embauche, peut-être en testant les connaissances techniques du candidat. Le processus de recrutement prend un certain temps et le groupe de candidats ne cesse de se réduire à mesure que nous nous rapprochons de la décision finale. Le résultat devrait être la sélection de la meilleure personne pour le poste.
Le recrutement en soi est assez compliqué, nous allons donc discuter d'un modèle de données assez complet pour couvrir tous les aspects du processus. Asseyez-vous dans votre fauteuil et profitez de l'article d'aujourd'hui !
Comment fonctionne le processus de recrutement
La plupart des étapes du processus de recrutement sont de notoriété publique, mais nous verrons exactement comment cela fonctionne avant de passer au modèle de données.
-
Détecter un besoin
C'est un must absolu dans le processus de recrutement; il n'y aura pas de processus si la direction n'est pas au courant de la nécessité d'embaucher un nouvel employé. Ce besoin peut être le résultat du démarrage d'une nouvelle entreprise, de la croissance d'une entreprise existante ou du départ d'un employé actuel.
À moins qu'une entreprise n'ait des postes strictement définis (par exemple, les banques), il n'est pas toujours facile de déterminer quand embaucher un nouvel employé. Parler avec les employés et voir beaucoup d'heures supplémentaires peut inciter une nouvelle embauche. Les réglementations internes ou externes peuvent également exiger que certains postes ne soient attribués qu'à des personnes ayant des compétences spécifiques et une expérience de travail pertinente (par exemple, réviseur interne).
-
Décrivez le poste et ses compétences requises
Pour avoir une idée de cette étape, pensez à une description de poste vraiment bien rédigée. Il contient :
- Une liste de toutes les tâches liées au poste
- Qualifications minimales en matière d'études et d'expérience professionnelle
- Compétences spécifiques essentielles aux fonctions professionnelles
- Compétences supplémentaires ou préférées
- Un résumé de ce que l'employeur attend du candidat et de ce que le candidat peut attendre de cet emploi
- Une fourchette de salaire et peut-être un ensemble d'avantages sociaux
Ces informations sont importantes pour les recruteurs comme pour les candidats. Il ne sert à rien d'inviter dix candidats au processus de sélection si aucun d'entre eux ne sera satisfait de l'offre financière. Et plus la description de poste est détaillée, plus il sera facile d'attirer des candidats qualifiés.
-
Définir qui gérera le processus et quand chaque tâche doit se produire
L'étape suivante consiste à définir des dates précises auxquelles chaque partie du processus aura lieu. De plus, les entreprises peuvent affecter des employés à chaque étape. Si l'entreprise dispose d'un service des ressources humaines, celui-ci gérera probablement chaque partie du processus de recrutement, bien que d'autres employés puissent apporter leurs connaissances spécifiques si nécessaire (par exemple, si nous embauchons un spécialiste informatique, le responsable du service informatique doit évaluer les candidats ' compétences techniques).
S'il n'y a pas de département RH, on peut s'attendre à ce que le personnel de gestion soit en charge du processus. Dans les petites et moyennes entreprises, cela n'est pas seulement nécessaire, c'est souhaité.
-
Publier le poste
Nous sommes maintenant prêts à publier une description de poste sur notre site, sur des sites d'emploi ou des agrégateurs, ou dans un journal. L'offre d'emploi doit contenir les puces énumérées à l'étape 2. Cela aidera les candidats potentiels à décider s'ils souhaitent postuler pour le poste. Il est essentiel de rendre la description de poste précise; nous avons tous perdu notre temps à passer des entretiens pour un poste qui ne correspondait pas à sa description ou à nos attentes.
-
Sélectionner, tester et interviewer les candidats
Une fois la période de candidature terminée, les candidats possédant les compétences et l'expérience les plus pertinentes seront invités à une phase d'évaluation initiale (généralement un entretien ou un test). Les autres candidats seront informés qu'ils n'ont pas été retenus pour le poste. Une grande entreprise doit inviter un nombre minimum prédéfini de candidats à l'évaluation initiale. C'est un gain de temps tant pour les candidats que pour l'entreprise.
Les petites et moyennes entreprises pourraient décider de poursuivre le processus jusqu'à ce qu'elles trouvent la meilleure solution. Dans de tels cas, la période de candidature restera ouverte jusqu'à ce que le bon candidat soit trouvé et toutes les autres dates seront définies en cours de route.
Le processus d'entrevue et de test variera selon la taille de l'entreprise et l'organisation. Dans les grandes entreprises dotées de services RH, il y aura probablement une série de tests pour vérifier les compétences professionnelles des candidats. D'autres tests peuvent mesurer les traits psychologiques et de personnalité pour déterminer la correspondance candidat-emploi, la correspondance candidat-entreprise ou même la santé mentale du candidat. ☺
Ces tests seront généralement divisés en plusieurs étapes, et chaque étape réduira le nombre de candidats.
-
L'entretien final
Cette étape sera probablement une entrevue avec les quelques meilleurs candidats. C'est l'étape la plus importante du processus car les candidats peuvent parler pour eux-mêmes, démontrer leur compétence et leur personnalité et déterminer si l'entreprise et le poste leur conviendront. Après cette étape, le meilleur candidat recevra une offre. S'ils acceptent, le processus de recrutement pour ce poste est terminé. Si le candidat refuse l'offre d'emploi, l'entreprise fera une offre à son prochain choix.
-
Existe-t-il des différences dans le processus de recrutement pour les petites, moyennes et grandes entreprises ? Comment allons-nous les résoudre dans notre modèle ?
Il y aura certaines différences dans les processus de recrutement des petites, moyennes et grandes entreprises. De plus, le processus variera selon les postes à pourvoir. Pensez à quel point les compétences et les expériences requises sont différentes pour un gestionnaire de contenu, un ornithologue et un capitaine de bateau de croisière. Certains emplois auront plus de tests et d'entretiens, d'autres n'en auront que quelques-uns. Mais en fin de compte, tout se résume à obtenir les bonnes réponses et à classer les candidats.
Dans ce modèle, je traiterai tous les tests et entretiens de la même manière. Nous stockerons les réponses de chaque candidat, les relierons à la question pertinente et stockerons le score du candidat pour chaque étape du processus.
-
Qui peut utiliser ce modèle de données ?
Ce modèle est très spécifique et ne doit être utilisé que pour le processus de recrutement. Mais cela ne se limite pas aux départements RH; vous pouvez également utiliser ce modèle pour gérer un service de recrutement professionnel.
-
Le modèle de données
Le modèle de données se compose de cinq domaines principaux :
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Je décrirai chaque domaine séparément, dans le même ordre qu'ils sont répertoriés.
Section 1 :Emplois
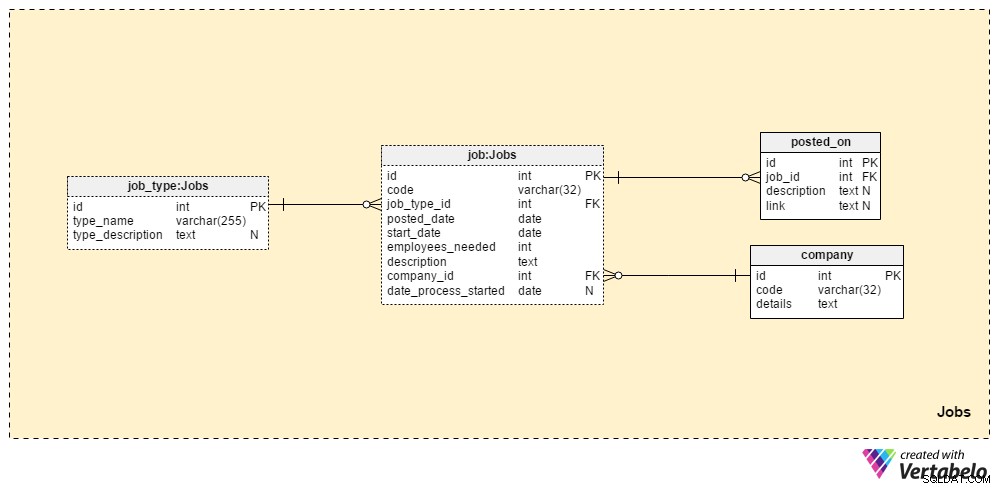
Les Jobs La section stockera tous les détails de tous les postes que nous avons publiés. Les deux tables de dictionnaire, la company table et le job_type table, font partie de la configuration initiale. Les deux tables restantes, job et posted_on , contiennent des données "réelles" liées aux offres d'emploi.
Le job_type dictionnaire contient une liste de types de travaux différents et UNIQUES. Nous pouvons nous attendre à des valeurs telles que "administrateur principal de la base de données" ou "journaliste informatique" à stocker dans le type_name attribut. Le type_description L'attribut peut stocker une description plus détaillée du travail.
La company dictionnaire contient une liste de toutes les entreprises avec lesquelles nous travaillons. Si nous embauchons des employés uniquement pour notre entreprise, ce dictionnaire ne contiendra que le nom de notre entreprise. Si nous sommes une agence de recrutement, elle stockera les noms de toutes les entreprises qui nous ont embauchés.
Une liste de tous les postes que nous avons publiés est stockée dans la table "job". Les attributs de ce tableau sont :
code– Notre ID UNIQUE interne utilisé pour désigner un emploi.job_type_id– Fait référence au type de travail associé.posted_date– La date à laquelle ce poste a été publié.start_date– La date de début prévue (premier jour ouvrable) pour cette tâche.employees_needed– Le nombre d'employés que nous souhaitons embaucher lors de ce processus de recrutement. Généralement, cela aura une valeur de "1", mais dans certains cas - par ex. lors du démarrage d'une nouvelle entreprise ou de la création d'un nouveau service, nous pouvons nous attendre à des valeurs plus importantes.description– Une description détaillée de ce poste. C'est ici que nous énumérerons toutes les compétences professionnelles requises, préférées et souhaitées.company_id– Références l'ID de l'entreprise qui nous a embauchés. Si nous sommes une agence de recrutement, cela fera référence à un nom commercial stocké dans lecompanytable. Sinon, ce sera l'ID de notre propre entreprise.date_process_started– La date de début du processus de recrutement. Cela pourrait être NULL si nous devons définir les étapes et actions futures concernant cette tâche.
Le dernier tableau de ce domaine est le posted_on table. Pour chaque job_id , nous stockerons un link à l'offre d'emploi et la description associée . Nous pourrions utiliser ces données pour savoir où les candidats trouvent nos offres d'emploi.
Section 2 :Candidats, recruteurs et documents
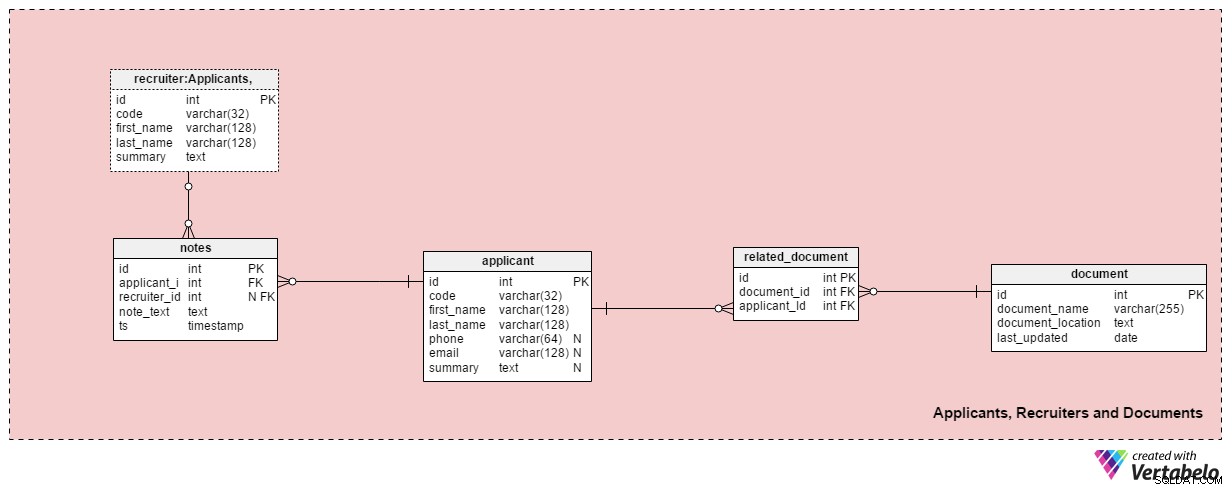
Ce domaine contient toutes les tables nécessaires pour stocker des informations sur les recruteurs, les candidats et leurs documents associés.
Le applicant le tableau répertorie tous les candidats avec lesquels nous avons eu des contacts. Chaque candidat est défini UNIQUEMENT dans notre système avec un « code ». En plus de cela, nous stockerons le prénom et le nom de chaque candidat, phone numéro, email adresse, et leur summary . Ce tableau peut être adapté à des besoins spécifiques, par ex. ajouter des numéros de téléphone, des adresses e-mail ou des adresses physiques supplémentaires.
Nous mettrons en relation les candidats avec les documents disponibles. Une liste de tous les documents disponibles (CV ou curriculum vitae, diplômes ou diplômes, relevés de notes, certifications, etc.) est stockée dans le document table. Pour chaque document, nous enregistrerons son nom dans le système, son emplacement et l'heure de la dernière mise à jour.
Nous mettrons en relation les candidats avec des documents en utilisant le related_document table. Il ne contient que deux clés étrangères, qui forment le document_id – applicant_id Paire UNIQUE.
Le recruiter Le tableau répertorie les employés qui pourraient être affectés à une demande d'emploi ou qui saisissent des notes relatives à un candidat. Chaque recruteur est UNIQUEMENT défini par son code . Nous ne stockerons que les informations de base telles que first_name , last_name et le summary du recruteur .
Le dernier tableau de ce domaine est les notes table. C'est ici que nous stockerons toutes les notes relatives à un candidat. Nous pourrions stocker des notes telles que "Le candidat a manqué la réunion" ou « Le candidat s'est très bien comporté lors du premier entretien » . Pour chaque note, nous stockerons l'identifiant du recruteur qui a rédigé cette note, l'identifiant du candidat associé, la note_text , et l'horodatage de création de la note.
Section 3 :Détails du test
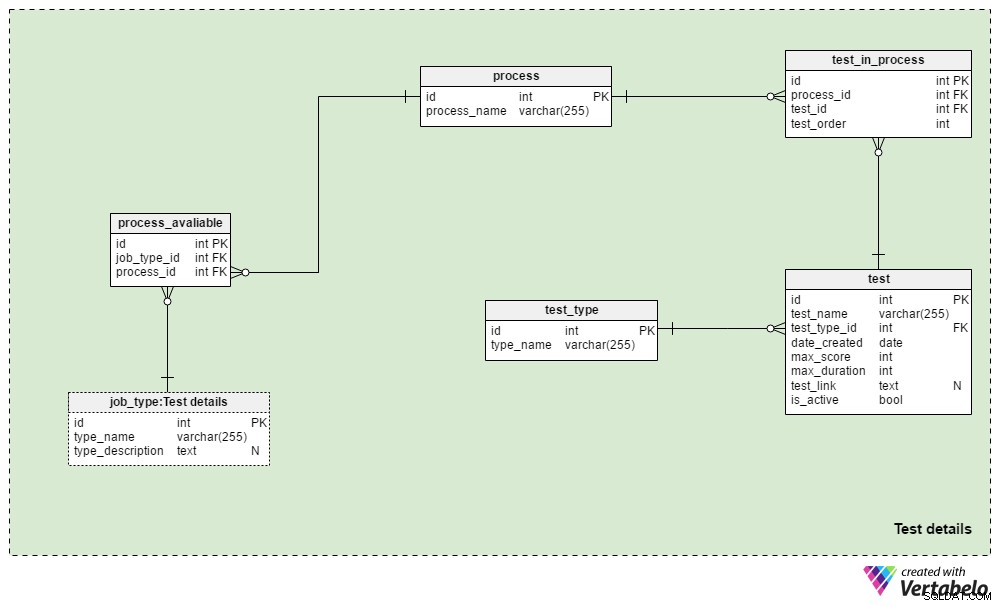
Les Test details contient les tableaux utilisés pour définir les processus de recrutement et les tests utilisés au cours de ces processus. Nous utiliserons généralement toujours le même processus de sélection pour le même type d'emploi :les modifications ne sont apportées que lorsqu'elles sont requises par les circonstances commerciales. Nous pourrions utiliser quelques processus différents pour chaque type de travail, et nous utiliserons presque certainement le même processus pour différents types de travail.
Le process table est un simple dictionnaire contenant uniquement un process_name UNIQUE attribut. Il répertorie tous les processus de recrutement que nous avons déjà utilisés et que nous utilisons actuellement.
Nous mettrons en relation les processus avec différents types de tâches. Nous stockerons ces relations dans le process_available table. Ses seuls attributs sont le couple UNIQUE job_type_id – process_id . Lorsque plusieurs processus sont disponibles pour un type d'emploi, cela permet au recruteur d'en choisir un.
Le test_in_process table est utilisée pour définir l'ordre des tests au cours de ce processus. Les attributs de ce tableau sont :
process_idettest_id– Fait référence au processus et au test associés.test_order– Le numéro ordinal de ce test ou de cette étape du processus. Avecprocess_id, cela forme la clé UNIQUE de la table. Nous ne pouvons avoir qu'une seule étape à la fois pendant le processus.
Le test Le tableau répertorie tous les tests actuellement et précédemment utilisés dans le processus de recrutement. Nous traiterons également les révisions de CV et les entretiens comme des tests. Bien qu'ils n'aient pas besoin de questions et de réponses définies, ils font partie d'une évaluation. Pour chaque test, nous stockerons :
test_name– Une désignation UNIQUE pour chaque test.test_type_id– Fait référence autest_typedictionnaire.date_created– La date à laquelle nous avons créé ce test dans notre système.max_score– Le score maximum atteignable pour ce test. Cette valeur est la somme de toutes les bonnes réponses à ce test ou la note la plus élevée que les recruteurs pourraient attribuer à un CV ou à un entretien.max_duration– Combien de temps (en minutes) le candidat doit passer le test.test_link– Contient un lien vers l'emplacement du test. Cette valeur peut être NULL lorsque nous n'utilisons pas de test dans le processus.is_active– Indique si nous utilisons actuellement ce test.
Nous avons déjà mentionné le test_type dictionnaire. Il contient tous les noms de test UNIQUE par format, par ex. « Examen du CV » , "test de compétence en ligne" , "test de compétence sur papier" et "entretien" .
Ce modèle n'inclut pas la structure nécessaire pour stocker les questions et les réponses des tests. Au lieu de cela, il stocke un lien vers les emplacements qui contiennent ces informations. Le même design sera utilisé dans les Applications Domaine.
Section 4 :Candidatures
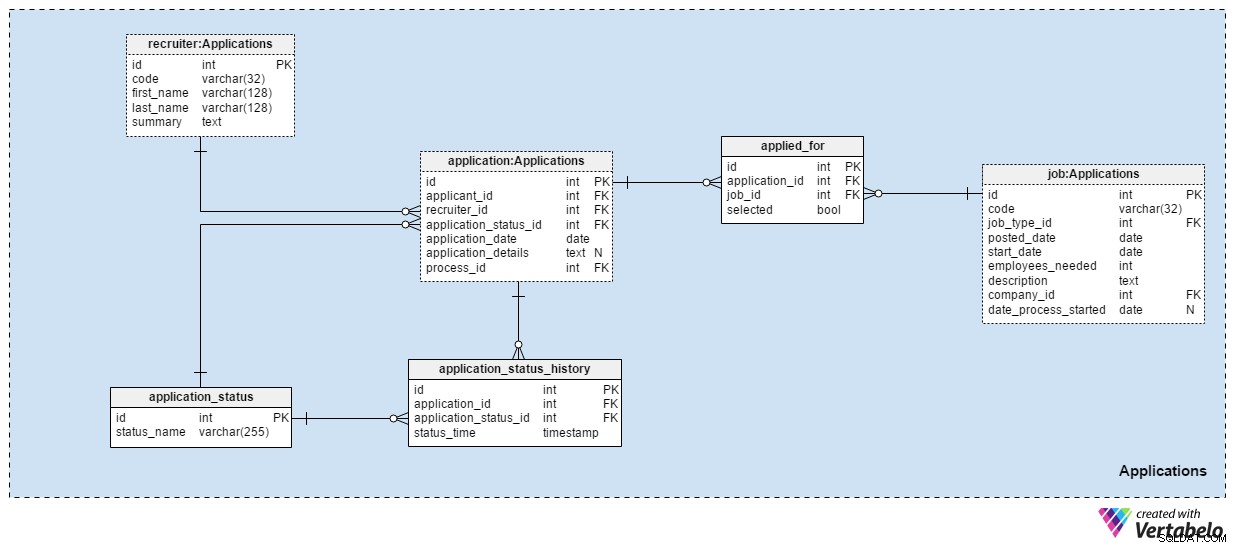
Les Applications domaine est probablement le plus important dans ce modèle de données. Tous les autres domaines mentionnés jusqu'à présent décrivent des applications. Celui-ci stocke les vraies choses.
Chaque candidature que nous avons reçue est enregistrée dans le application table. Pour chaque candidature, nous stockerons l'identifiant des candidats associés, l'identifiant des recruteurs et une référence à l'état actuel de cette candidature. Nous mettrons à jour ce statut en même temps que nous créerons une nouvelle entrée dans application_status_history table. La application_date L'attribut est utilisé pour stocker la date pertinente, tandis que tous les détails supplémentaires sont stockés au format texte. Le process_id L'attribut stocke une référence au processus sélectionné pour cette application.
Les demandes changeront de statut au fil du temps. Une liste de tous les statuts d'application est stockée dans le application_status dictionnaire. Le seul attribut est status_name et il ne peut contenir que des valeurs UNIQUES. Les valeurs attendues incluent :"appliqué" , "CV examiné" , "choisi pour le test" , "rejeté après examen du CV" , "a réussi le test" , "invité à un entretien" et "résilié par le demandeur" .
Nous stockerons tous les statuts d'application dans le application_status_history table. Ce tableau contient des références à l'application table et le application_status dictionnaire. Nous stockerons également le status_time exact lorsque ce statut a été attribué à l'application. Le application_id – status_time paire forme la clé UNIQUE de cette table.
Dans la plupart des cas, un candidat ne postulera qu'à un seul poste avec une seule candidature. Il est possible qu'un candidat postule pour plus d'un poste et nous choisirons le poste qui lui convient le mieux lors du processus de sélection. Dans le applied_for table, nous stockerons la paire UNIQUE application_id – job_id . Nous enregistrerons également si le candidat associé à cette candidature a été selected pour ce poste. Nous pouvons nous attendre à ce que tous les selected les valeurs seront définies sur "False" au début du processus de sélection et que nous mettrons à jour un seul pour chaque poste à "Vrai" .
Section 5 :Tests d'application
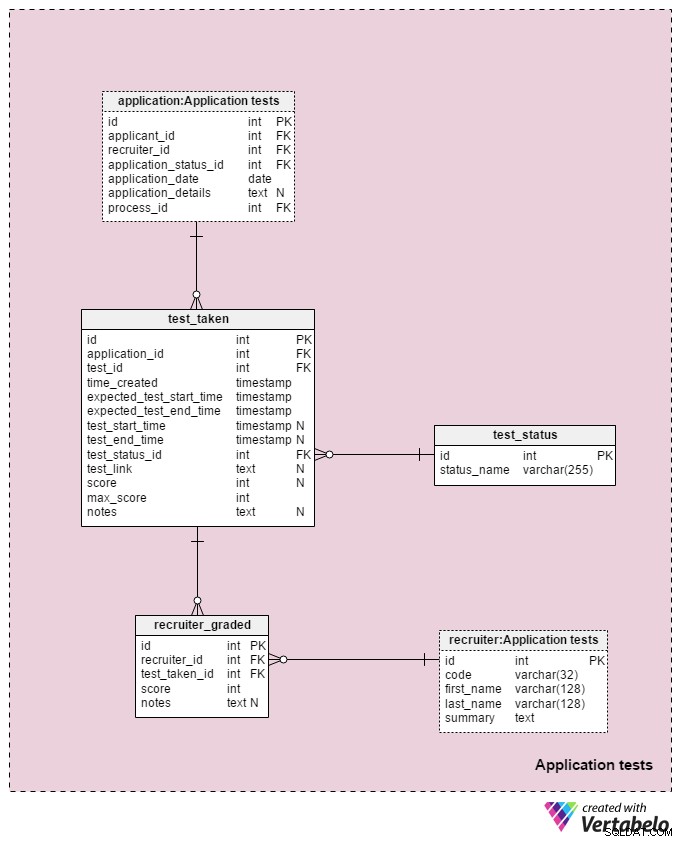
Le dernier domaine de notre modèle sera utilisé pour stocker les résultats de chaque test effectué au cours du processus de sélection. Deux tableaux utilisés dans ce domaine sont des copies d'autres domaines :application et recruiter . Ils sont utilisés ici pour simplifier le modèle.
Tous les détails liés à chaque test sont stockés dans le test_taken table. Ce tableau contient également toutes les autres étapes du processus qui pourraient être notées, comme une révision de CV. Les attributs de ce tableau sont :
application_id– Référence l'applicationtable. Cela concerne un test avec le candidat qui a passé ce test.test_id– Fait référence autestcatalogue. Nous pourrions également référencer letest_in_processtableau ici, qui nous fournirait plus d'informations sur le test passé. J'ai décidé de ne pas le faire car cette structure nous donne plus de flexibilité. (Par exemple, si nous voulons permettre aux candidats de passer un test deux fois ou en dehors des heures habituelles).time_created– L'heure à laquelle nous avons inséré ce test dans notre système.expected_test_start_timeetexpected_test_end_time– Les heures de début et de fin, telles que discutées avec le demandeur. Nous pourrions modifier ces valeurs au cas où le candidat ou le recruteur aurait besoin de reporter le test.test_start_timeettest_end_time–Les heures réelles de début et de fin du test. Celles-ci contiendront des valeurs NULL lors de la création du test ; les valeurs seront mises à jour lorsque le candidat commencera et terminera ce test.test_status_id– Référence letest_statusdictionnaire.test_link– Liens vers le test avec les réponses du candidat. Il sera mis à jour lorsque le candidat soumettra le test.score– Le score du candidat à ce test. Ceci est soit déterminé manuellement par un recruteur (par exemple pour une révision de CV) soit automatiquement (la somme de tous les scores des éléments de test). Il peut également contenir une valeur NULL pour les tests qui ne sont pas notés ou notés sur une échelle prédéfinie. De plus, un test planifié mais pas encore terminé peut avoir une valeur NULL.max_score– Le score maximum réalisable du test. C'est la même que la valeur stockée dans letest.”max_scoreattribut. Je souhaite conserver cette valeur car le recruteur pourrait modifier le test en cours de passation et donc changer la note maximale pouvant être atteinte.notes– Toutes les notes ou remarques supplémentaires saisies par les recruteurs concernant ce test spécifique.
La combinaison de test_id – application_id – expected_test_start_time attributs forme la clé UNIQUE de cette table. Avant d'ajouter une nouvelle session de test, nous devons toujours vérifier les intervalles de test qui se chevauchent pour le candidat associé et tous les recruteurs associés.
Le test_status dictionnaire contient une liste de chaque status_name UNIQUE qui pourrait être affecté à un test. Certaines valeurs attendues incluent :"not started" , "en cours" , "terminé avec succès" , "terminé sans succès" , "reporté" , "annulé" et "candidat annulé" .
La dernière table de notre modèle est le recruiter_graded table, qui stocke toutes les notes attribuées par les recruteurs lors de la notation de chaque test. Par conséquent, nous stockerons les références au recruiter et test_taken les tables. Nous stockerons également le score atteint ainsi que toutes les notes . Ces informations sont très importantes, en particulier lorsque nous notons des tests manuellement (c'est-à-dire pour les révisions de CV et les entretiens).
Aujourd'hui, nous avons discuté d'un modèle de données qui peut couvrir presque toutes les situations du processus de sélection et de recrutement, y compris des exceptions peu courantes.
La plupart d'entre nous ont une certaine expertise sur ce sujet. Veuillez partager votre expérience lorsque vous étiez dans le rôle du recruteur ou de l'autre côté du bureau. Ce modèle couvre-t-il les situations que vous avez rencontrées ? Si non, quels changements proposeriez-vous ?