Bien qu'à l'avenir, la plupart des serveurs de base de données (en particulier ceux qui gèrent des charges de travail de type OLTP) utiliseront un stockage basé sur le flash, nous n'en sommes pas encore là :le stockage flash est encore considérablement plus cher que les disques durs traditionnels, et de nombreux systèmes utilisent une combinaison de disques SSD et HDD. Cela signifie cependant que nous devons décider comment diviser la base de données - ce qui devrait aller à la rouille tournante (HDD) et ce qui est un bon candidat pour le stockage flash qui est plus cher mais bien meilleur pour gérer les E/S aléatoires.
Il existe des solutions qui tentent de gérer cela automatiquement au niveau du stockage en utilisant automatiquement les SSD comme cache, en conservant automatiquement la partie active des données sur le SSD. Les appliances de stockage/SAN le font souvent en interne, il existe des disques hybrides SATA/SAS avec un grand disque dur et un petit SSD dans un seul package, et bien sûr il existe des solutions pour le faire directement sur l'hôte - par exemple, il y a dm-cache sous Linux, LVM a également obtenu une telle capacité (construite au-dessus de dm-cache) en 2014, et bien sûr ZFS a L2ARC.
Mais ignorons toutes ces options automatiques, et disons que nous avons deux appareils connectés directement au système - l'un basé sur les disques durs, l'autre basé sur le flash. Comment diviser la base de données pour tirer le meilleur parti du flash coûteux ? Un modèle couramment utilisé consiste à le faire par type d'objet, en particulier les tables par rapport aux index. Ce qui est logique en général, mais nous voyons souvent des personnes placer des index sur le stockage SSD, car les index sont associés à des E/S aléatoires. Bien que cela puisse sembler raisonnable, il s'avère que c'est exactement le contraire de ce que vous devriez faire.
Laissez-moi vous montrer une référence…
Permettez-moi de le démontrer sur un système avec à la fois un stockage HDD (RAID10 construit à partir de 4 disques SAS 10k) et un seul périphérique SSD (Intel S3700). Le système dispose de 16 Go de RAM, utilisons donc pgbench avec des échelles 300 (=4,5 Go) et 3000 (=45 Go), c'est-à-dire une qui s'intègre facilement dans la RAM et un multiple de RAM. Ensuite, plaçons les tables et les index sur différents systèmes de stockage (en utilisant des tablespaces) et mesurons les performances. Le cluster de bases de données a été raisonnablement configuré (tampons partagés, limites WAL, etc.) en ce qui concerne les ressources matérielles. Le WAL a été placé sur un périphérique SSD séparé, attaché à un contrôleur RAID partagé avec les disques SAS.
Sur le petit ensemble de données (4,5 Go), les résultats ressemblent à ceci (notez que l'axe des y commence à 3 000 tps) :
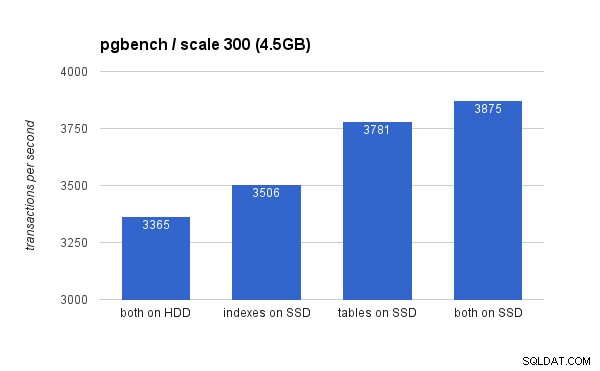
De toute évidence, placer les index sur SSD offre un avantage moindre par rapport à l'utilisation du SSD pour les tables. Bien que l'ensemble de données s'intègre facilement dans la RAM, les modifications doivent éventuellement être écrites sur le disque, et bien que le contrôleur RAID dispose d'un cache en écriture, il ne peut pas vraiment rivaliser avec le stockage flash. Les nouveaux contrôleurs RAID fonctionneraient probablement un peu mieux, mais les nouveaux disques SSD le feraient aussi.
Sur le grand ensemble de données, les différences sont beaucoup plus significatives (cette fois, l'axe des ordonnées commence à 0) :
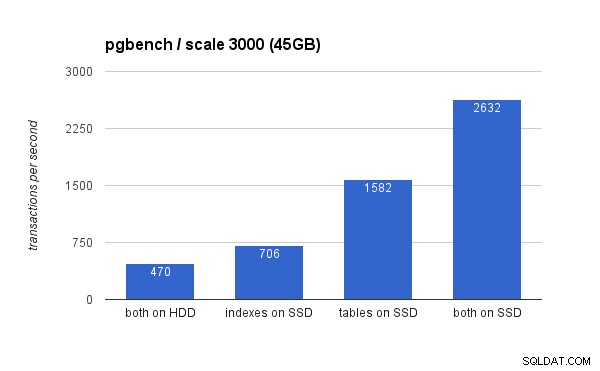
Le placement des index sur le SSD entraîne un gain de performances significatif (près de 50 %, en prenant le stockage sur disque dur comme référence), mais le déplacement des tables vers le SSD dépasse facilement ce chiffre en gagnant plus de 200 %. Bien sûr, si vous placez à la fois les tables et l'index sur les SSD, vous améliorerez encore les performances - mais si vous pouviez le faire, vous n'avez pas à vous soucier des autres cas.
Mais pourquoi ?
Obtenir de meilleures performances en plaçant des tables sur des SSD peut sembler un peu contre-intuitif, alors pourquoi se comporte-t-il ainsi ? Eh bien, c'est probablement une combinaison de plusieurs facteurs :
- les index sont généralement beaucoup plus petits que les tables, et s'intègrent donc plus facilement dans la mémoire
- les pages dans les niveaux d'index (dans l'arborescence) sont généralement assez chaudes, et restent donc en mémoire
- lors de la numérisation et de l'indexation, une grande partie des E/S réelles est de nature séquentielle (en particulier pour les pages feuilles)
La conséquence en est qu'une quantité surprenante d'E/S contre les index ne se produit pas du tout (grâce à la mise en cache) ou est séquentielle. D'un autre côté, les index sont une excellente source d'E/S aléatoires sur les tables.
C'est plus compliqué, cependant...
Bien sûr, ce n'était qu'un exemple simple, et les conclusions pourraient être différentes pour des charges de travail sensiblement différentes, par exemple. De même, comme les SSD sont plus chers, les systèmes ont tendance à avoir plus d'espace disque sur les disques durs que sur les disques SSD, de sorte que les tables peuvent ne pas tenir sur le SSD alors que les index le feraient. Dans ces cas, un placement plus élaboré est nécessaire - par exemple en tenant compte non seulement du type d'objet, mais aussi de la fréquence à laquelle il est utilisé (et en ne déplaçant que les tables les plus utilisées vers des SSD), ou même des sous-ensembles de tables (par exemple en déplaçant progressivement les anciens données du SSD vers le disque dur).