Qu'est-ce que ClickHouse ?

ClickHouse est un SGBD open source orienté colonne (ou système de gestion de base de données) principalement utilisé pour OLAP (ou le traitement analytique en ligne des requêtes). Il est capable de générer à une vitesse fulgurante des données analytiques en temps réel et des rapports à l'aide de requêtes SQL. Il est tolérant aux pannes, évolutif, hautement fiable et contient un ensemble d'outils riches en fonctionnalités.
Dans une base de données standard, les données sont stockées dans des tables, des colonnes et des lignes. Dans une table, les valeurs associées sont physiquement stockées côte à côte dans une ligne, ce qui est essentiel à son fonctionnement. C'est ainsi que fonctionnent la plupart des bases de données de type chaîne.
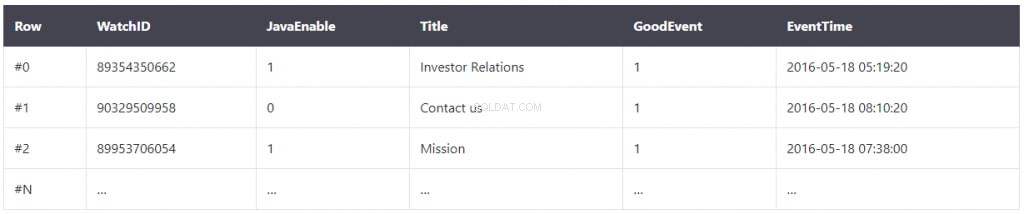
Voici quelques exemples de cette forme de base de données :
- MySQL
- Postgres
- SQLite
Les données sont stockées comme indiqué ci-dessous dans une base de données en colonnes :
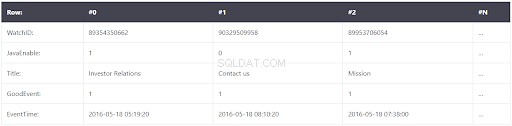
Cela semble similaire, mais les différences sont les suivantes :les valeurs de différentes colonnes sont stockées séparément, tandis que les données d'une colonne sont stockées ensemble. Exemples de tableaux orientés colonnes :
- Vertical
- InfiniDB
- Google Dremel
Ces SGBD stockent les enregistrements dans des blocs, regroupés par colonnes plutôt que par lignes. En ne chargeant pas les données des colonnes, ils passent moins de temps à lire les données lors de l'exécution des requêtes, ce qui permet aux SGBD de calculer les données et de renvoyer les résultats beaucoup plus rapidement que les bases de données regroupées en blocs. En règle générale, les bases de données orientées colonnes sont mieux appliquées dans les scénarios OLAP où elles sont généralement 100 fois plus rapides dans le traitement de la plupart des requêtes par rapport aux bases de données de type chaîne.
Comme nous pouvons le voir sur les illustrations ci-dessus, OLAP nous permet d'organiser de grandes quantités de données et d'effectuer des requêtes complexes de plusieurs ordres de grandeur plus rapidement qu'une base de données typique. Par conséquent, il est extrêmement utile de travailler avec de grandes quantités d'entrées lors de l'analyse de données et/ou d'une analyse commerciale.
Utilisation SQL
ClickHouse utilise un dialecte de SQL, qui est similaire au langage de requête structuré standard, mais il contient des extensions supplémentaires :divers tableaux, des fonctions d'ordre supérieur, des structures imbriquées, des fonctions pour travailler avec des URL et la possibilité de travailler avec un dictionnaire externe, etc.
Alors que nous gagnons en vitesse et en traitement de données volumineuses, nous perdons également d'autres aspects, notamment les options suivantes :
- Manque de transactions.
- Des types de données solides nécessitant une conversion explicite.
- Doit stocker les données intermédiaires dans la RAM pour certaines opérations.
- Absence d'un optimiseur de requêtes à part entière.
- Lecture ponctuelle de données dans une base de données.
Malgré cela, ClickHouse fait preuve de hautes performances et gagne face à ses nombreux concurrents. ClickHouse a été développé pour résoudre les problèmes d'analyse Web pour Yandex.Metrica, le troisième système d'analyse Web le plus populaire au monde. Il est également utilisé par Cloudflare pour traiter les statistiques de site Web pour ses utilisateurs.
Prérequis
Pour l'installer, nous avons besoin :
- Un serveur à 2 cœurs utilisant au moins 2 Go de RAM
- Un système d'exploitation Ubuntu 20.04 LTS
- Accès au compte utilisateur root (comme toutes les actions effectuées en tant que root).
Installation de ClickHouse sur Ubuntu 20.04
Avant l'installation, nous mettrons à jour le système et les packages sur le serveur.
root@host:~# apt update && apt -y upgrade
Hit:1 https://by.archive.ubuntu.com/ubuntu focal InRelease
Hit:2 https://by.archive.ubuntu.com/ubuntu focal-updates InRelease
Hit:3 https://by.archive.ubuntu.com/ubuntu focal-backports InRelease
Get:4 https://security.ubuntu.com/ubuntu focal-security InRelease [109 kB]
Hit:5 https://download.docker.com/linux/ubuntu focal InRelease
Hit:6 https://debian.neo4j.com stable InRelease
Fetched 109 kB in 0s (231 kB/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
All packages are up to date.
Reading package lists... Done
Building dependency tree
Reading state information... Done
Calculating upgrade... Done
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
root@host:~# Yandex maintient un référentiel avec la dernière version de ClickHouse, nous devons donc l'ajouter. Ajoutez également une clé GPG pour consulter le référentiel et installer en toute sécurité ClickHouse et les futures mises à jour.
root@host:~# apt-key adv --keyserver keyserver.ubuntu.com --recv E0C56BD4
Executing: /tmp/apt-key-gpghome.5KK4WZQb0R/gpg.1.sh --keyserver keyserver.ubuntu.com --recv E0C56BD4
gpg: key C8F1E19FE0C56BD4: public key "ClickHouse Repository Key <milovidov@yandex-team.ru>" imported
gpg: Total number processed: 1
gpg: imported: 1
root@host:~# Ajoutez le référentiel à la liste des référentiels APK.
root@host:~# echo "deb https://repo.yandex.ru/clickhouse/deb/stable/ main/" | tee /etc/apt/sources.list.d/clickhouse.list
deb https://repo.yandex.ru/clickhouse/deb/stable/ main/
root@host:~# Ensuite, nous mettons à jour nos packages de serveur.
root@host:~# apt update
Hit:1 https://by.archive.ubuntu.com/ubuntu focal InRelease
Hit:2 https://by.archive.ubuntu.com/ubuntu focal-updates InRelease
Hit:3 https://by.archive.ubuntu.com/ubuntu focal-backports InRelease
Get:4 https://security.ubuntu.com/ubuntu focal-security InRelease [109 kB]
Ign:5 https://repo.yandex.ru/clickhouse/deb/stable main/ InRelease
Get:6 https://repo.yandex.ru/clickhouse/deb/stable main/ Release [749 B]
Get:7 https://repo.yandex.ru/clickhouse/deb/stable main/ Release.gpg [836 B]
Hit:8 https://download.docker.com/linux/ubuntu focal InRelease
Get:9 https://repo.yandex.ru/clickhouse/deb/stable main/ Packages [152 kB]
Hit:10 https://debian.neo4j.com stable InRelease
Fetched 263 kB in 0s (536 kB/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
All packages are up to date.
root@host:~#Enfin, nous pouvons installer ClickHouse. Lorsque vous y êtes invité, saisissez un mot de passe.
root@host:~# apt install -y clickhouse-server clickhouse-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
clickhouse-common-static
Suggested packages:
clickhouse-common-static-dbg
The following NEW packages will be installed:
clickhouse-client clickhouse-common-static clickhouse-server
0 upgraded, 3 newly installed, 0 to remove and 0 not upgraded.
Need to get 119 MB of archives.
After this operation, 401 MB of additional disk space will be used.
...
Preconfiguring packages ...
Selecting previously unselected package clickhouse-common-static.
(Reading database ... 164995 files and directories currently installed.)
Preparing to unpack .../clickhouse-common-static_20.12.5.14_amd64.deb ...
Unpacking clickhouse-common-static (20.12.5.14) ...
Selecting previously unselected package clickhouse-client.
Preparing to unpack .../clickhouse-client_20.12.5.14_all.deb ...
Unpacking clickhouse-client (20.12.5.14) ...
Selecting previously unselected package clickhouse-server.
Preparing to unpack .../clickhouse-server_20.12.5.14_all.deb ...
Unpacking clickhouse-server (20.12.5.14) ...
Setting up clickhouse-common-static (20.12.5.14) ...
Setting up clickhouse-server (20.12.5.14) ...
ClickHouse init script has migrated to systemd. Please manually stop old server
and restart the service: killall clickhouse-server && sleep 5 && servi
ce clickhouse-server restart
Synchronizing state of clickhouse-server.service with SysV service script with /
lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable clickhouse-server
Created symlink /etc/systemd/system/multi-user.target.wants/clickhouse-server.se
rvice → /etc/systemd/system/clickhouse-server.service.
Copying ClickHouse binary to /usr/bin/clickhouse.new
/usr/bin/clickhouse already exists, will rename existing binary to /usr/bin/clic
khouse.old and put the new binary in place
Renaming /usr/bin/clickhouse.new to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-server already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-server to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-client already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-client to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-local already exists but it points to /clickhouse. W
ill replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-local to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-benchmark already exists but it points to /clickhous
e. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-benchmark to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-copier already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-copier to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-obfuscator already exists but it points to /clickhou
se. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-obfuscator to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-git-import to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-compressor already exists but it points to /clickhou
se. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-compressor to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-format already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-format to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-extract-from-config already exists but it points to
/clickhouse. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-extract-from-config to /usr/bin/clickhouse.
Creating clickhouse group if it does not exist.
groupadd -r clickhouse
Creating clickhouse user if it does not exist.
useradd -r --shell /bin/false --home-dir /nonexistent -g clickhouse clickhouse
Will set ulimits for clickhouse user in /etc/security/limits.d/clickhouse.conf.
Creating config directory /etc/clickhouse-server/config.d that is used for tweak
s of main server configuration.
Creating config directory /etc/clickhouse-server/users.d that is used for tweaks
of users configuration.
Config file /etc/clickhouse-server/config.xml already exists, will keep it and e
xtract path info from it.
/etc/clickhouse-server/config.xml has /var/lib/clickhouse/ as data path.
/etc/clickhouse-server/config.xml has /var/log/clickhouse-server/ as log path.
Users config file /etc/clickhouse-server/users.xml already exists, will keep it
and extract users info from it.
chown --recursive clickhouse:clickhouse '/etc/clickhouse-server'
Creating log directory /var/log/clickhouse-server/.
Creating data directory /var/lib/clickhouse/.
Creating pid directory /var/run/clickhouse-server.
chown --recursive clickhouse:clickhouse '/var/log/clickhouse-server/'
chown --recursive clickhouse:clickhouse '/var/run/clickhouse-server'
chown clickhouse:clickhouse '/var/lib/clickhouse/'
Password for default user is already specified. To remind or reset, see /etc/cli
ckhouse-server/users.xml and /etc/clickhouse-server/users.d.
Setting capabilities for clickhouse binary. This is optional.
command -v setcap >/dev/null && echo > /tmp/test_setcap.sh && chmod a+x /tmp/te
st_setcap.sh && /tmp/test_setcap.sh && setcap 'cap_net_admin,cap_ipc_lock,cap_sy
s_nice+ep' /tmp/test_setcap.sh && /tmp/test_setcap.sh && rm /tmp/test_setcap.sh
&& setcap 'cap_net_admin,cap_ipc_lock,cap_sys_nice+ep' /usr/bin/clickhouse || ec
ho "Cannot set 'net_admin' or 'ipc_lock' or 'sys_nice' capability for clickhouse
binary. This is optional. Taskstats accounting will be disabled. To enable task
stats accounting you may add the required capability later manually."
ClickHouse has been successfully installed.
Start clickhouse-server with:
clickhouse start
Start clickhouse-client with:
clickhouse-client --password
Setting up clickhouse-client (20.12.5.14) ...
Processing triggers for systemd (245.4-4ubuntu3.3) ...
root@host:~# Démarrer le service ClickHouse
Maintenant que nous avons installé ClickHouse, exécutons-le en arrière-plan.
root@host:~# service clickhouse-server start
root@host:~# Vérifier le statut
Dans cette étape, nous vérifions simplement que tout fonctionne comme prévu.
root@host:~# service clickhouse-server status
● clickhouse-server.service - ClickHouse Server (analytic DBMS for big data)
Loaded: loaded (/etc/systemd/system/clickhouse-server.service; enabled; ve>
Active: active (running) since Wed 2020-12-30 22:08:26 +03; 25s ago
Main PID: 5553 (clickhouse-serv)
Tasks: 48 (limit: 9489)
Memory: 45.8M
CGroup: /system.slice/clickhouse-server.service
└─5553 /usr/bin/clickhouse-server --config=/etc/clickhouse-server/>
сне 30 22:08:26 host clickhouse-server[5553]: Include not found: clickhouse_com>
сне 30 22:08:26 host clickhouse-server[5553]: Logging trace to /var/log/clickho>
сне 30 22:08:26 host clickhouse-server[5553]: Logging errors to /var/log/clickh>
сне 30 22:08:26 host clickhouse-server[5553]: Processing configuration file '/e>
сне 30 22:08:26 host clickhouse-server[5553]: Include not found: networks
сне 30 22:08:26 host clickhouse-server[5553]: Saved preprocessed configuration >
сне 30 22:08:28 host clickhouse-server[5553]: Processing configuration file '/e>
сне 30 22:08:28 host clickhouse-server[5553]: Include not found: clickhouse_rem>
сне 30 22:08:28 host clickhouse-server[5553]: Include not found: clickhouse_com>
сне 30 22:08:28 host clickhouse-server[5553]: Saved preprocessed configuration >
lines 1-19/19 (END)Les lignes ci-dessous sont celles auxquelles nous devons prêter une attention particulière.
Loaded: loaded (/etc/systemd/system/clickhouse-server.service; enabled; ve>
Active: active (running) since Wed 2020-12-30 22:08:26 +03; 25s agoConfigurer le pare-feu
Si vous n'utilisez pas de pare-feu, ignorez cette étape. Si vous prévoyez de vous connecter à distance et d'avoir un pare-feu activé, cette étape est nécessaire. Ouvrez et modifiez le fichier de configuration, et décommentez la ligne ci-dessous.
<!-- <listen_host>0.0.0.0</listen_host> →Une fois l'édition terminée, enregistrez le fichier à l'aide de Ctrl+S et Ctrl+X clés, puis redémarrez le service ClickHouse.
root@host:~# service clickhouse-server restart
root@host:~# Ouvrir les ports
Ensuite, ouvrez le port 8123 dans le pare-feu pour autoriser l'accès à votre adresse IP.
ufw allow from YOUR_IP_SERVER/32 to any port 8123Ensuite, ouvrez le port 9000 pour le clickhouse-client Adresse IP.
root@host:~# ufw allow from 192.168.13.1/32 to any port 8123
Rules updated
root@host:~#
root@host:~# ufw allow from 192.168.13.1/32 to any port 9000
Rules updated
root@host:~# Vérifier la connexion
Pour vérifier que tout fonctionne lors de la connexion à distance, utilisez la requête suivante.
clickhouse-client --host 192.168.13.1 --passwordroot@host:~# clickhouse-client --host 192.168.13.1 --password
Password for user (default):
Connecting to 192.168.13.1:9000 as user default.
Connected to ClickHouse server version 20.12.5 revision 54442.
host :)Apprentissage des commandes et interactions de base
Dans ClickHouse, nous pouvons créer et supprimer des bases de données en utilisant la syntaxe SQL modifiée. Jetons un coup d'œil aux exemples ci-dessous. Tout d'abord, connectons-nous à ClickHouse.
root@host:~# clickhouse-client
ClickHouse client version 20.12.5.14 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 20.12.5 revision 54442.
host :) Créer une base de données
Une fois que nous sommes dans la ligne de commande ClickHouse, nous créons une base de données nommée liquidweb en utilisant la syntaxe suivante.
host :) CREATE DATABASE liquidweb;
CREATE DATABASE liquidweb
Query id: 9169dbaa-402e-4d37-828f-5fde43d4a91d
Ok.
0 rows in set. Elapsed: 0.004 sec.
host :) Dans ClickHouse, le tableau est presque le même que dans d'autres bases de données avec un ensemble de données connexes dans un format structuré. Nous pouvons spécifier des colonnes et leurs types, ajouter des lignes et effectuer différents types de requêtes sur la base de données.
Créer un tableau
Avant de créer une table, il est important de connaître et de comprendre les types de colonnes disponibles. Les types de colonnes suivants sont viables :
- UInt64 — Cette table est utilisée pour stocker des nombres entiers allant de 0 à 18446744073709551615.
- Float64 — Chaque table qui utilise Float64 peut stocker des nombres à virgule flottante comme 10,5, 18754,067, etc.
- Chaîne — Ici, la table de chaînes remplace VARCHAR, BLOB, CLOB et d'autres types de différents SGBD
- Date — Cette table est utilisée pour stocker les dates au format AAAA-MM-JJ.
- DateHeure — Ici, la table DateTime est utilisée pour stocker les dates et les heures au format AAAA-MM-JJ HH :MM :SS
Structures de données
ClickHouse définit la structure des données sous-jacentes en décrivant les données exactes, la possibilité d'interroger la table, ses modes d'accès simultané à la table et la prise en charge des index. ClickHouse a différentes capacités qui conviennent à différentes conditions d'utilisation.
FusionnerArbre
Le mécanisme le plus largement utilisé est l'opération de moteur de table appelée MergeTree . Cette fonction est conçue pour insérer de grandes quantités de données dans une table. Il est fortement recommandé pour l'utilisation de bases de données de production en raison de sa prise en charge optimisée pour l'insertion de grandes quantités d'actifs en temps réel, ainsi que de sa fiabilité et de sa prise en charge des requêtes.
Sélectionner la base de données
Passons à une pratique plus poussée. Commençons par sélectionner une base de données dans laquelle nous allons créer une table.
host :) USE liquidweb;
USE liquidweb
Query id: aba15bcb-224b-426d-9f74-350a88346115
Ok.
0 rows in set. Elapsed: 0.001 sec.
host :) Créer un tableau
Ensuite, nous créons une table appelée collègues .
host :) CREATE TABLE colleagues ( id UInt64, name String, url String, created DateTime ) ENGINE = MergeTree() PRIMARY KEY id ORDER BY id;
CREATE TABLE colleagues
(
`id` UInt64,
`name` String,
`url` String,
`created` DateTime
)
ENGINE = MergeTree()
PRIMARY KEY id
ORDER BY id
Query id: 08223a2f-d365-43cb-8627-d22674d1c47c
Ok.
0 rows in set. Elapsed: 0.004 sec.
host :) Passons en revue les valeurs que nous avons ajoutées.
- identifiant - Il s'agit de la colonne de la clé primaire. Chaque ligne doit avoir un identifiant unique.
- nom - Une colonne avec une valeur de chaîne.
- URL - Une colonne avec une valeur de chaîne qui contient un lien vers le profil.
- créé - La date à laquelle l'employé est apparu dans le système.
Après avoir défini les colonnes dans le tableau, nous spécifions ensuite le MergeTree mécanisme de rangement de la table. Ensuite, nous désignons les colonnes, puis définissons les colonnes au niveau du tableau.
- CLÉ PRIMAIRE - Spécifie la colonne de clé primaire.
- ORDER PAR - Les valeurs de table stockées sont triées par colonne d'id.
Ajouter des données
Nous pouvons maintenant travailler avec la table. Ajoutons quelques données aux collègues tableau.
host :) INSERT INTO colleagues VALUES (1, 'margaret', 'https://1.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: 42dbde52-6d7e-4849-ac5e-280590f3232d
Ok.
1 rows in set. Elapsed: 0.002 sec.
host :) Ajoutons plus de données.
host :) INSERT INTO colleagues VALUES (2, 'john', 'https://2.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: a9b34f78-2caa-4b41-bd4e-91bf8049a04b
Ok.
1 rows in set. Elapsed: 0.001 sec.
host :)host :) INSERT INTO colleagues VALUES (3, 'kingsman', 'https://3.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: df5133c1-b404-4569-8123-f0728c172c87
Ok.
1 rows in set. Elapsed: 0.003 sec.
host :) host :) INSERT INTO colleagues VALUES (4, 'tor', 'https://4.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: 14f56b86-fae7-4af2-b506-18c351b92853
Ok.
1 rows in set. Elapsed: 0.001 sec.
host :) Ajouter une colonne
Alors que nous avons ajouté quelques valeurs, nous avons réalisé que nous avions oublié d'ajouter une autre colonne, nous devons donc l'ajouter ci-dessous.
host :) ALTER TABLE colleagues ADD COLUMN location String;
ALTER TABLE colleagues
ADD COLUMN `location` String
Query id: 002900f4-9fd9-4302-a10f-6aa5b818f9ae
Ok.
0 rows in set. Elapsed: 0.005 sec.
host :)Modifier les données
Maintenant, nous devons changer les anciennes données d'une manière ou d'une autre. Dans la version 19.13, ClickHouse ne prend pas en charge la mise à jour et la suppression de lignes individuelles en raison de sa mise en œuvre. Cependant, ClickHouse prend en charge les mises à jour et les suppressions en bloc et possède également sa propre syntaxe pour ces opérations.
Maintenant, nous mettons à jour nos lignes.
host :) ALTER TABLE colleagues UPDATE url ='https://1.com' WHERE id < 15;
ALTER TABLE colleagues
UPDATE url = 'https://1.com' WHERE id < 15
Query id: 6fc6620e-fd90-43aa-8d7f-8a34cfb73650
Ok.
0 rows in set. Elapsed: 0.004 sec.
host :)Après OÙ , nous définissons les paramètres du filtre et pouvons également supprimer les paramètres inutiles.
host :) ALTER TABLE colleagues DELETE WHERE id < 2;
ALTER TABLE colleagues
DELETE WHERE id < 2
Query id: 354e27fc-70c9-480b-bb1d-067591924c6e
Ok.
0 rows in set. Elapsed: 0.005 sec.
host :) Supprimer la colonne
Pour supprimer des colonnes d'un tableau, procédez comme suit.
host :) ALTER TABLE colleagues DROP COLUMN location;
ALTER TABLE colleagues
DROP COLUMN location
Query id: da361478-0619-4c31-8422-f59ee14a57d7
Ok.
0 rows in set. Elapsed: 0.008 sec.
host :) Récupération de données via des requêtes
Ensuite, nous passons à la démonstration de la récupération de données à l'aide de requêtes. ClickHouse utilise ici la syntaxe SQL avec ses ajouts. Essayons de rassembler quelques informations de base.
host :) SELECT url, name FROM colleagues WHERE url = 'https://1.com' LIMIT 1;
SELECT
url,
name
FROM colleagues WHERE url = 'https://1.com'
LIMIT 1
Query id: 8a5cbf9a-f187-440c-9a60-2d23029b4bd1
┌─url──────────┬─name─┐
│ https://1.com │ john │
└──────────────┴──────┘
1 rows in set. Elapsed: 0.003 sec.
host :) - SÉLECTIONNER - Sélectionnez plusieurs paramètres.
- DE - Déterminer quelle table nous allons recevoir des valeurs.
- OÙ - Définissez les paramètres et les filtres concernant quelle valeur et combien.
Nous pouvons également utiliser des paramètres de recherche supplémentaires, tels que :
- compter - Renvoie le nombre de lignes correspondant aux conditions.
- somme - Renvoie la somme des valeurs sélectionnées.
- moy - Renvoie la moyenne des éléments sélectionnés.
- unique - Renvoie le nombre approximatif de lignes uniques correspondantes.
- topK - Renvoie un tableau des valeurs les plus fréquentes d'une colonne spécifique à l'aide d'un algorithme.
Supprimer les tables et les bases de données
Ensuite, nous passons à la suppression des tables et des bases de données. Commençons par supprimer une table.
host :) DROP TABLE colleagues;
DROP TABLE colleagues
Query id: 21048fe4-d379-48ac-b9a7-71f0b3fe93e1
Ok.
0 rows in set. Elapsed: 0.001 sec.
host :) Maintenant, supprimez la base de données.
host :) DROP DATABASE liquidweb;
DROP DATABASE liquidweb
Query id: 4ad9a51a-f89d-4be5-be9c-92b8cb38614b
Ok.
0 rows in set. Elapsed: 0.001 sec.
host :) Pour quitter la base de données, entrez la valeur standard 'exit'.
host :) exit
Bye.
root@host:~# Créer un utilisateur
Maintenant que nous avons couvert toutes les fonctionnalités de base, nous allons créer plusieurs utilisateurs de base de données. Le fichier de configuration ClickHouse peut être situé dans le chemin suivant /etc/clickhouse-client/config.xml. Accédez à ce fichier, ouvrez-le avec vim ou nano et spécifiez les valeurs dans l'ordre suivant.
<config> <user>username</user> <password>password</password> <secure>False</secure></config>Nous utiliserons l'éditeur nano pour éditer le fichier.
root@host:~# nano /etc/clickhouse-client/config.xml
root@host:~# Entrez les informations requises, puis enregistrez les modifications à l'aide de Ctrl+S et Ctrl+X clés
Se connecter à ClickHouse
Enfin, pour vous connecter à ClickHouse, entrez la commande suivante dans le terminal.
root@host:~# clickhouse-client -u margaret --password
ClickHouse client version 20.12.5.14 (official build).
Password for user (margaret):
Connecting to localhost:9440 as user margaret.
Connected to ClickHouse server version 20.12.5 revision 54442.
host :) Conclusion
Dans ce tutoriel, nous avons découvert de nombreux aspects de ClickHouse. Nous avons découvert comment il fonctionne, quand il peut être appliqué et dans quelles circonstances il est utile. Nous avons identifié comment ajouter une clé, le référentiel, puis installer le logiciel ClickHouse. De même, nous avons ensuite installé et configuré le pare-feu pour autoriser l'accès. De plus, nous avons créé des bases de données et des tables, ajouté des colonnes et des données, puis les avons mises à jour et supprimées. Enfin, nous avons montré comment créer des utilisateurs dans le fichier de configuration.
Nous sommes fiers d'être The Most Helpful Humans In Hosting™ ! Nos équipes d'assistance sont composées de techniciens Linux expérimentés et d'administrateurs système talentueux qui ont une connaissance intime de plusieurs technologies d'hébergement Web, y compris celles abordées dans cet article.
Si vous avez des questions concernant cet article, nous sommes toujours disponible pour fournir des informations à toute question relative à cet article, 24 heures sur 24, 7 jours sur 7, 365 jours par an.
Si vous êtes un serveur VPS entièrement géré, un cloud dédié, un cloud privé VMWare, un serveur parent privé, des serveurs cloud gérés ou un propriétaire de serveur dédié, et que vous n'êtes pas à l'aise avec l'exécution de l'une des étapes décrites, nous sommes joignables par téléphone au 800.580.4985, un chat ou un ticket d'assistance pour vous aider dans ce processus.