Les index de hachage font partie intégrante des bases de données. Si vous avez déjà utilisé une base de données, il y a de fortes chances que vous les ayez vues en action sans même vous en rendre compte.
Les index de hachage diffèrent dans leur travail des autres types d'index car ils stockent des valeurs plutôt que des pointeurs vers des enregistrements situés sur un disque. Cela garantit une recherche et une insertion plus rapides dans l'index. C'est pourquoi les index de hachage sont souvent utilisés comme clés primaires ou identifiants uniques.
Comprendre les indices de hachage
Un index de hachage est un type d'index le plus couramment utilisé dans la gestion des données. Il est généralement créé sur une colonne contenant des valeurs uniques, telles qu'une clé primaire ou une adresse e-mail. Le principal avantage de l'utilisation des index de hachage est leur performance rapide.
Le concept derrière ces index peut être complexe à comprendre pour quelqu'un qui n'en a jamais entendu parler auparavant. Cependant, il est important de comprendre les index de hachage si vous avez besoin de comprendre le fonctionnement des bases de données. Il est nécessaire pour résoudre les problèmes courants liés aux bases de données et à leur vitesse.
La bonne nouvelle est qu'avec un peu de patience et un téléphone portable éteint, vous pourrez maîtriser les index de hachage à coup sûr ! Alors, regardons mieux.
Rapide et facile
Un index de hachage est une structure de données qui peut être utilisée pour accélérer les requêtes de base de données. Cela fonctionne en convertissant les enregistrements d'entrée en un tableau de compartiments. Chaque compartiment contient le même nombre d'enregistrements que tous les autres compartiments de la table. Ainsi, quel que soit le nombre de valeurs différentes que vous avez pour une colonne particulière, chaque ligne correspondra toujours à un compartiment.
Les index de hachage permettent des recherches rapides sur les données stockées dans des tables. Ils fonctionnent en créant une clé d'index à partir de la valeur, puis en la localisant en fonction du hachage résultant. Il est utile lorsqu'il y a beaucoup d'entrées avec des valeurs similaires ou des doublons, car il suffit de comparer les clés au lieu de parcourir tous les enregistrements.
Cela n'a-t-il été ni rapide ni facile ? Pour comprendre comment fonctionnent les index de hachage et pourquoi ils sont si puissants, vous devez comprendre ce que l'on entend par hachage.
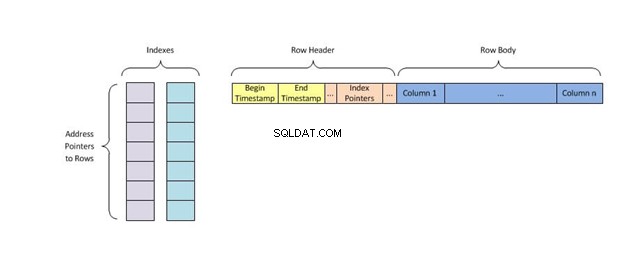
Hachage prend une information (une chaîne) et la transforme en une adresse ou un pointeur pour un accès rapide plus tard.
L'idée avec le hachage est que les données reçoivent un petit nombre. Lorsque vous recherchez les données, vous n'avez pas à passer au crible des masses. Au lieu de cela, recherchez simplement ce numéro. L'exemple le plus simple consiste à appuyer sur Ctrl+F pour saisir le mot que vous recherchez dans un texte au lieu de lire vous-même des dizaines de pages.
À quoi servent les index de hachage ?
Un index de hachage est un moyen d'accélérer le processus de recherche. Avec les index traditionnels, vous devez parcourir chaque ligne pour vous assurer que votre requête aboutit. Mais avec les index de hachage, ce n'est pas le cas !
Chaque clé de l'index contient une seule ligne des données de la table et utilise l'algorithme d'indexation appelé hachage qui leur attribue un emplacement unique en mémoire, éliminant toutes les autres clés avec des valeurs en double avant de trouver ce qu'il cherche.
Les index de hachage sont l'une des nombreuses façons d'organiser les données dans une base de données. Ils fonctionnent en prenant une entrée et en l'utilisant comme clé pour le stockage sur un disque. Ces clés ou valeurs de hachage , peut être n'importe quoi, des longueurs de chaîne aux caractères dans l'entrée.
Les index de hachage sont le plus souvent utilisés lors de l'interrogation d'entrées spécifiques avec des attributs spécifiques. Par exemple, il peut s'agir de trouver toutes les lettres A supérieures à 10 cm. Vous pouvez le faire rapidement en créant une fonction d'index de hachage.
Les index de hachage font partie du système de base de données PostgreSQL. Ce système a été développé pour augmenter la vitesse et les performances. Les index de hachage peuvent être utilisés conjointement avec d'autres types d'index, tels que B-tree ou GiST.
Un index de hachage stocke les clés en les divisant en petits morceaux appelés compartiments, où chaque compartiment reçoit un numéro d'identification entier pour le récupérer rapidement lors de la recherche de l'emplacement d'une clé dans la table de hachage. Les compartiments sont stockés séquentiellement sur un disque afin que les données qu'ils contiennent soient rapidement accessibles.
Des explications plus techniques peuvent être trouvées sur cette page (cliquez avec le bouton droit de la souris et choisissez "Traduire en anglais").
Avantages
Le principal avantage de l'utilisation d'index de hachage est qu'ils permettent un accès rapide lors de la récupération de l'enregistrement par la valeur de la clé. Il est souvent utile pour les requêtes avec une condition d'égalité. De plus, l'utilisation de références de hachage ne nécessitera pas beaucoup d'espace de stockage. C'est donc un outil efficace, mais non sans inconvénients.
Inconvénients
Les index de hachage sont une structure d'indexation relativement nouvelle avec le potentiel d'offrir des avantages significatifs en termes de performances. Vous pouvez les considérer comme une extension des arbres de recherche binaires (BST).
Les index de hachage fonctionnent en stockant les données dans des compartiments en fonction de leurs valeurs de hachage, ce qui permet une récupération rapide et efficace des données. Ils sont garantis en ordre.
Cependant, il est impossible de stocker des clés en double dans un bucket. Par conséquent, il y aura toujours des frais généraux. Mais jusqu'à présent, les avantages de l'utilisation des index de hachage l'emportent sur les inconvénients.
Comment tout cela fonctionne-t-il un peu plus en profondeur ?
Prenons une démo aviasales base de données pour mieux comprendre le fonctionnement des index de hachage.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Vous pouvez voir ici comment nous implémentons les index de hachage en compilant les données dans des ensembles.
Ceci est un exemple simple, mais notez que les limitations viennent avec moins d'infrastructure de code. Il peut y avoir un manque d'accès au journal WAL ou une incapacité à récupérer des index (indices ?) après un crash. De plus, les index peuvent ne pas participer à la réplication - cela est dû au fait que PostgreSQL est obsolète. Cependant, tout comme avec Python, vous recevez des avertissements qui vous permettent souvent d'éviter les erreurs.
Vous pouvez jeter un œil plus approfondi à l'intérieur de ces index si vous êtes suffisamment intrigué. Pour cela, nous créons une inspection de page exemple d'extension.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Si vous souhaitez inspecter complètement le code, commencez par README.
Résumé
Les index de hachage sont une structure de données qui accélère le processus de recherche d'informations dans de grandes bases de données. Ils fonctionnent en divisant les données en petits morceaux, puis en les triant. Ainsi, lorsque vous recherchez quelque chose, vous pouvez le trouver beaucoup plus rapidement.
Si vous voulez rechercher plus de choses, il existe des ressources pour DYOR. Gardez également un œil sur nos nouveaux articles, qui sortent plus vite que vous ne pouvez Ctrl + F le mot "hachage" sur cette page. J'espère que cela vous aidera !