Présentation
L'envoi de journaux de transactions est une technologie très connue utilisée dans SQL Server pour conserver une copie de la base de données en direct dans le site de récupération après sinistre. La technologie dépend de trois travaux clés :le travail de sauvegarde, le travail de copie et le travail de restauration. Pendant que la tâche de sauvegarde s'exécute sur le serveur principal, les tâches de copie et de restauration s'exécutent sur le serveur secondaire. Essentiellement, le processus implique des sauvegardes périodiques du journal des transactions sur un partage à partir duquel le travail de copie le déplace vers le serveur secondaire ; ensuite, le travail de restauration applique les sauvegardes du journal au serveur secondaire. Avant que tout cela ne commence, la base de données secondaire doit être initialisée avec une sauvegarde complète du serveur principal restauré avec l'option NORECOVERY.
Microsoft fournit un ensemble de procédures stockées qui peuvent être utilisées pour configurer l'envoi de journaux de bout en bout ainsi que des équivalents d'interface graphique à partir de l'élément de propriétés de chaque base de données pour laquelle vous souhaitez configurer l'envoi de journaux. Il est à noter que la Base de données secondaire peut être configurée en mode NORECOVERY ou en mode STANDBY. En mode NORECOVERY, la base de données n'est jamais disponible pour les requêtes, mais en mode STANDBY, la base de données secondaire peut être interrogée lorsqu'aucune opération de restauration du journal des transactions n'est en cours.
Configuration de l'environnement
Pour démarrer, nous créons deux instances SQL Server sur AWS avec une image Amazon EC2 identique. Cette instance Amazon EC2 exécute SQL Server 2017 RTM-CU5 sur Windows Server 2016. Ensuite, nous restaurons une copie de la base de données WideWorldImporters à l'aide d'un jeu de sauvegarde acquis auprès de GitHub vers la première instance, notre instance principale. Nous utilisons le même jeu de sauvegarde pour créer deux bases de données identiques nommées BranchDB et CorporateDB.
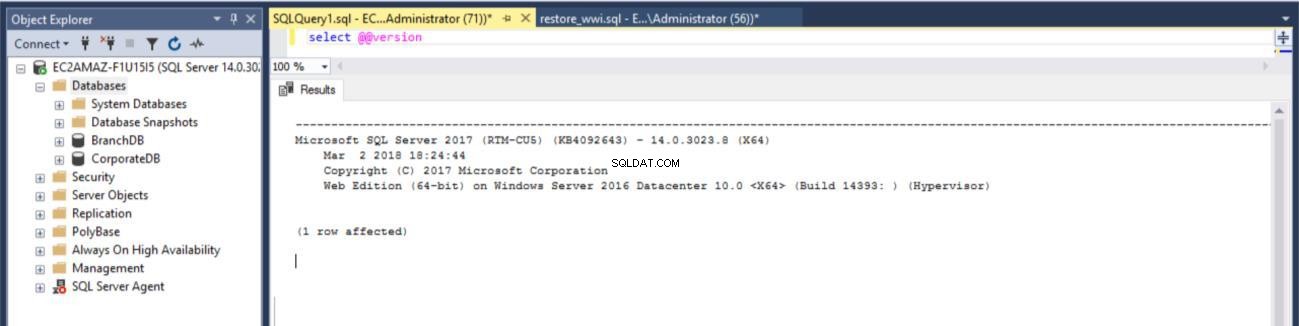
Fig. 1 version du serveur SQL
Fig. 2 BranchDB et CorporateDB sur l'instance principale (instance secondaire vide)
Liste 1 :Restauration de la base de données d'exemples de WideWorldImporters
restore filelistonly from disk='WideWorldImporters-Full.bak' restore database CorporateDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_1.ndf' restore database BranchDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary1.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData1.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log1.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_11.ndf
Nous avons maintenant deux instances, l'instance principale hébergeant les deux bases de données principales (BranchDB et CorporateDB et l'instance secondaire sans bases de données utilisateur. Nous procédons à la configuration de l'envoi des journaux de transactions sur les deux bases de données mais les différencions en appliquant un délai à la configuration de restauration de la première base de données. Rappelez-vous que les bases de données sont en fait identiques en termes de données qu'elles contiennent. Les graphiques suivants montrent les principales options sélectionnées dans la configuration de l'envoi de journaux.
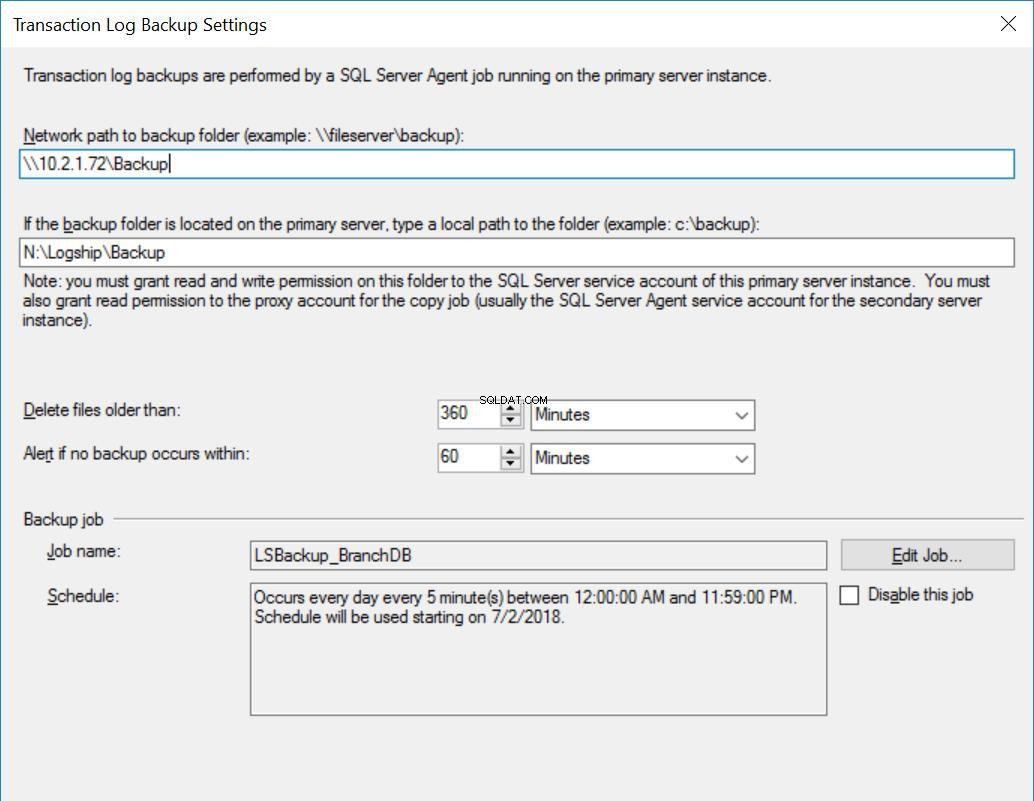
Fig. 3 Paramètres de sauvegarde pour BranchDB
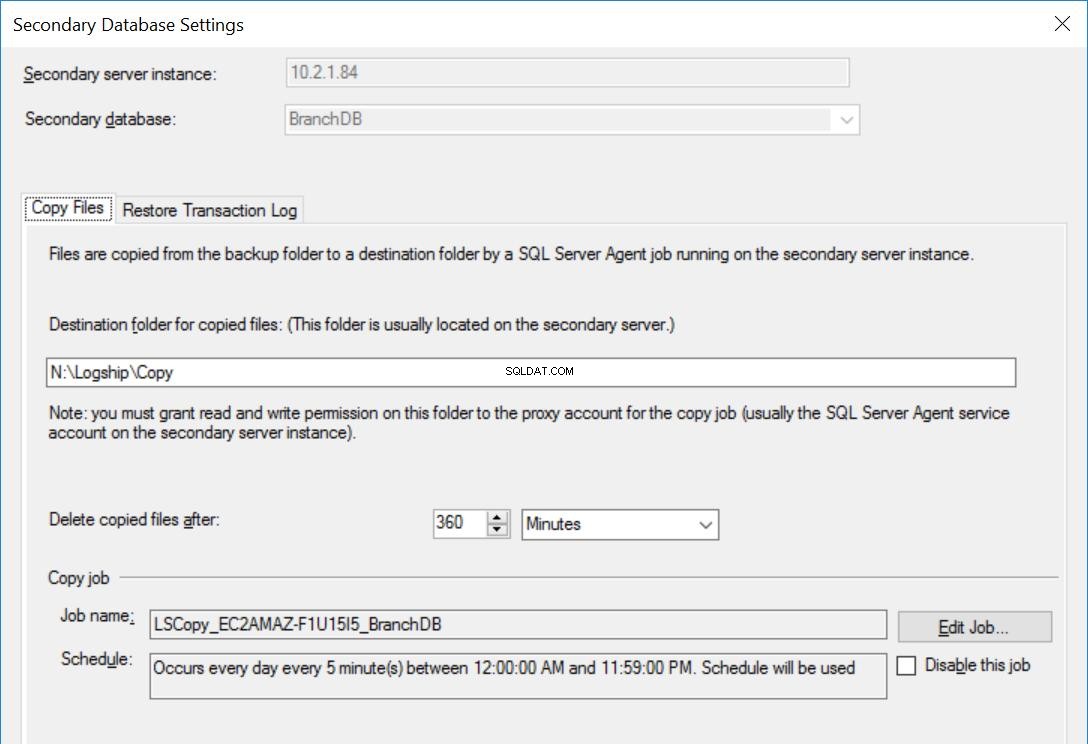
Fig. 4 Paramètres de copie pour BranchDB
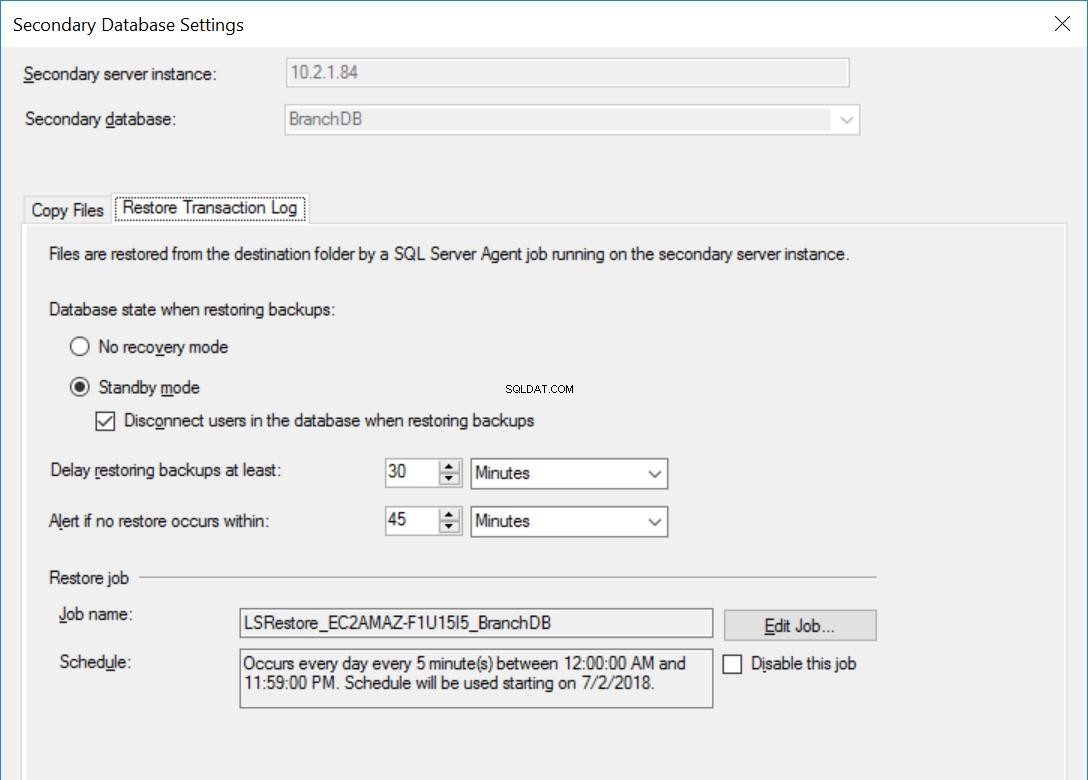
Fig. 5 Restaurer les paramètres de BranchDB
Chaque tâche d'envoi de journaux est configurée pour s'exécuter toutes les cinq minutes. Pour traiter les «sauvegardes de restauration différée», nous devons utiliser le mode de récupération en attente dans la configuration de l'envoi de journaux. C'est logique car il a la base de données secondaire en mode veille et indique que nous pouvons interroger la base de données secondaire chaque fois qu'une restauration du journal des transactions n'est pas en cours. La valeur que nous spécifions dans cette option (30 minutes dans ce cas) nous donne une bonne fenêtre pendant laquelle nous pouvons exécuter des rapports à partir de la base de données secondaire en dehors de l'exigence principale de cet article qui est de pouvoir récupérer d'une erreur de l'utilisateur.
En outre, nous devons mentionner que la restauration des sauvegardes du journal des transactions est en fait retardée. Son horodatage est postérieur à la valeur de retard. Cela signifie que toutes les sauvegardes du journal des transactions seront copiées sur le serveur secondaire, qui est basé sur la planification et spécifié dans le travail de copie. En fait, la tâche de restauration s'exécutera toujours selon la planification, mais les sauvegardes du journal des transactions (qui ne remontent pas à 30 minutes) ne seront pas restaurées. Essentiellement, la base de données de secours BranchDB a 30 minutes de retard sur la base de données principale BranchDB. Pour démontrer ce décalage, dans la section suivante, nous allons créer une table dans les deux bases de données et créer un travail qui insère un enregistrement toutes les minutes. Nous examinerons ce tableau dans les bases de données secondaires.
Les paramètres de la base de données CorporateDB sont les mêmes que dans les Fig. 3 à 5, sauf pour la tâche de restauration qui n'est PAS configurée pour retarder les sauvegardes du journal des transactions.
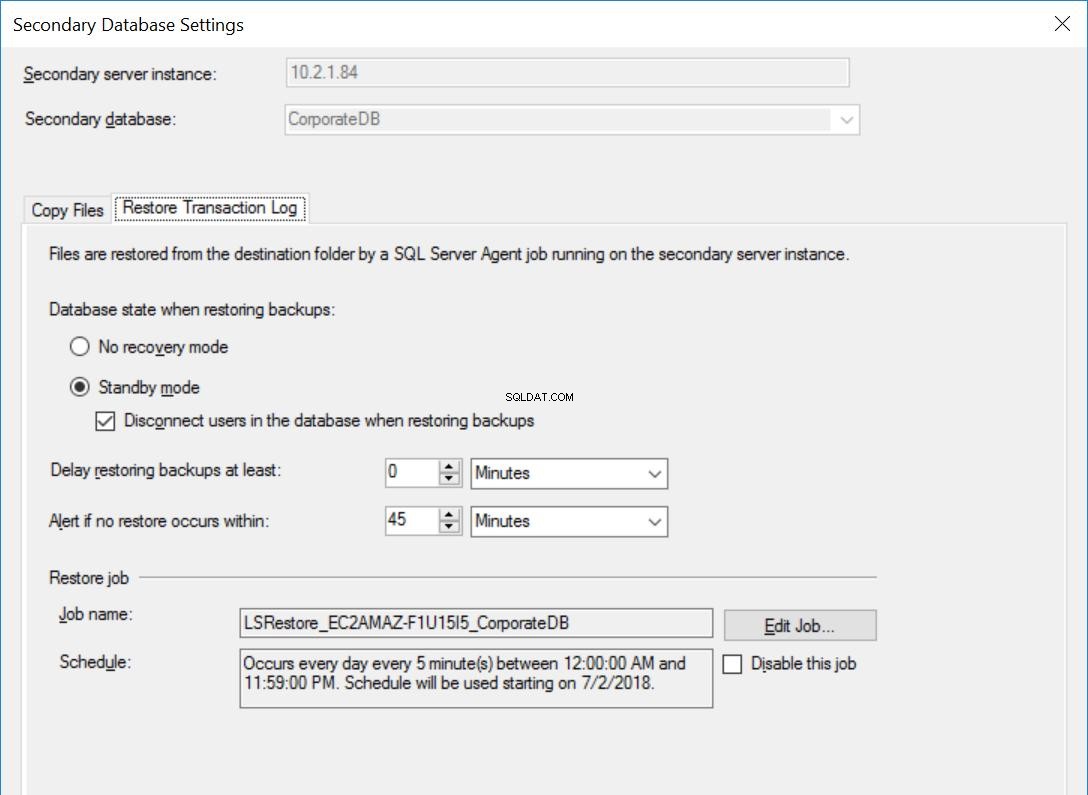
Fig. 6 Paramètres de restauration pour CorporateDB
Vérification de la configuration
Une fois la configuration terminée, nous pouvons vérifier que la configuration est OK et commencer par observer son travail. Le rapport Transaction Log Shipping nous montre que la Branch DB est en effet en retard sur CorporateDB en termes de restaurations :
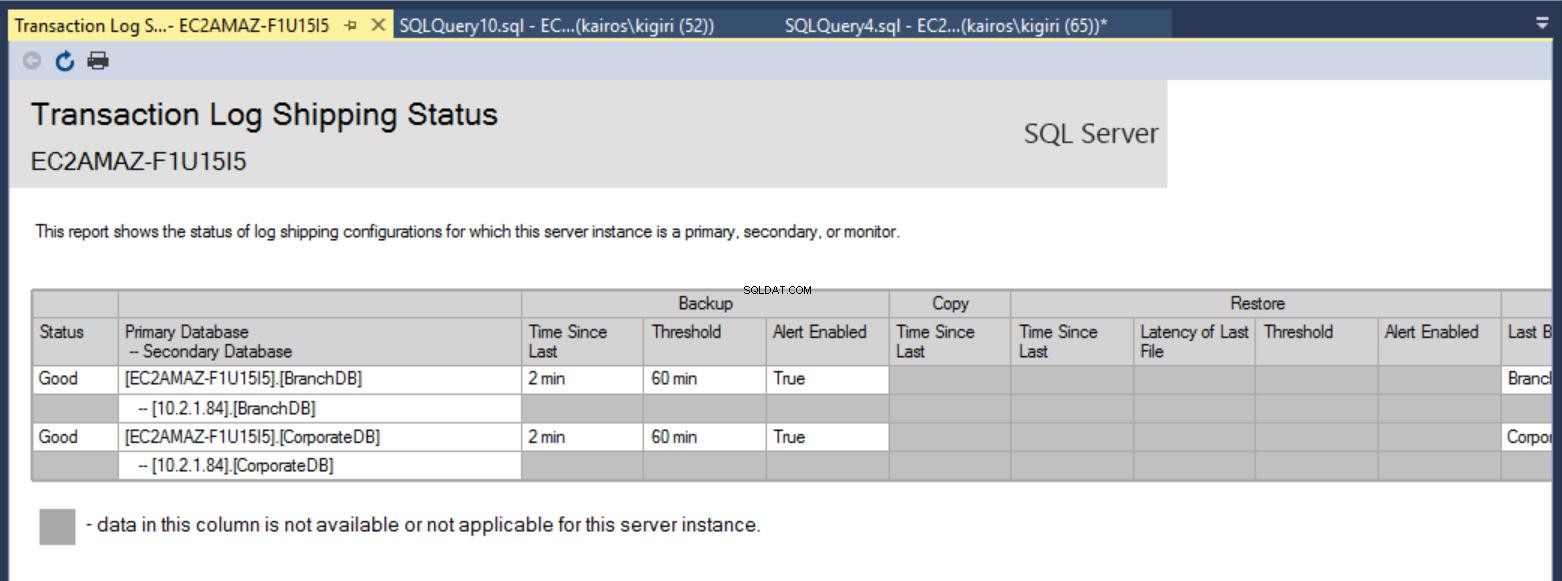
Fig. 7a Rapport d'envoi du journal des transactions sur le serveur principal
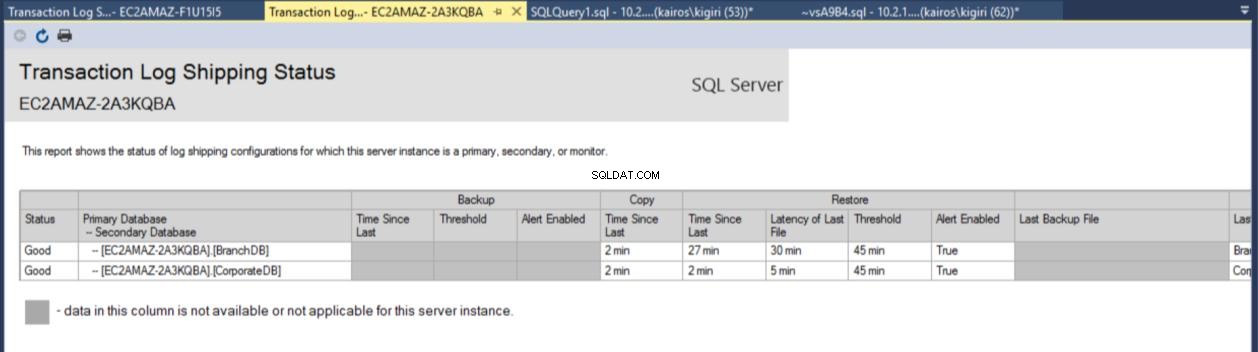
Fig. 7b Rapport d'envoi du journal des transactions sur le serveur secondaire
De plus, vous remarquerez le message ci-dessous dans l'historique des tâches de restauration pour BranchDB :
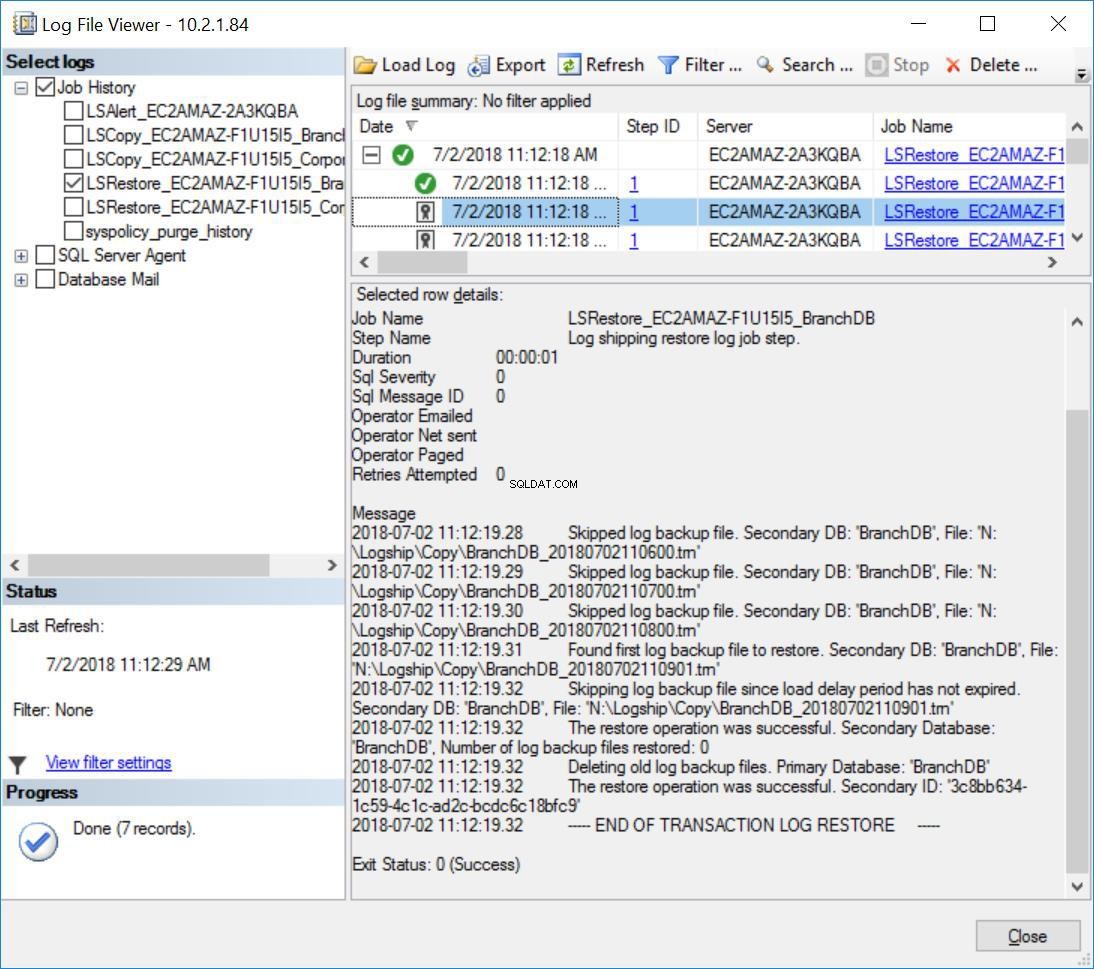
Fig. 8 Restaurations du journal des transactions ignorées sur le serveur secondaire
Nous pouvons aller plus loin dans cette vérification en créant une table et en utilisant un travail pour remplir cette table avec des lignes toutes les minutes. Le travail est un moyen simple de simuler ce qu'une application pourrait faire à une table utilisateur. Cela peut nous montrer que ce décalage est définitivement affiché dans les données utilisateur.
Liste 2 – Créer une table de suivi des journaux
use BranchDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername) use CorporateDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername)
Liste 3 – Créer une tâche pour remplir le tableau de suivi des journaux
/* ==Scripting Parameters== Source Server Version : SQL Server 2017 (14.0.3023) Source Database Engine Edition : Microsoft SQL Server Standard Edition Source Database Engine Type : Standalone SQL Server Target Server Version : SQL Server 2017 Target Database Engine Edition : Microsoft SQL Server Standard Edition Target Database Engine Type : Standalone SQL Server */ USE [msdb] GO /****** Object: Job [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ BEGIN TRANSACTION DECLARE @ReturnCode INT SELECT @ReturnCode = 0 /****** Object: JobCategory [[Uncategorized (Local)]] Script Date: 7/2/2018 3:32:00 PM ******/ IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback END DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'InsertRecords', @enabled=1, @notify_level_eventlog=0, @notify_level_email=0, @notify_level_netsend=0, @notify_level_page=0, @delete_level=0, @description=N'No description available.', @category_name=N'[Uncategorized (Local)]', @owner_login_name=N'kairos\kigiri', @job_id = @jobId OUTPUT IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback /****** Object: Step [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @example@sqldat.com, @step_name=N'InsertRecords', @step_id=1, @cmdexec_success_code=0, @on_success_action=1, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'TSQL', @command=N'use BranchDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) use CorporateDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) GO', @database_name=N'master', @flags=0 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @example@sqldat.com, @name=N'Schedule', @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=4, @freq_subday_interval=1, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20180702, @active_end_date=99991231, @active_start_time=0, @active_end_time=235959, @schedule_uid=N'03e5f1b2-2e0b-4b30-8d60-3643c84aa08d' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback COMMIT TRANSACTION GOTO EndSave QuitWithRollback: IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION EndSave: GO
Lorsque nous interrogeons la table sur les bases de données primaires respectivement, nous pouvons confirmer (en utilisant la colonne RecordTime) que les lignes correspondent dans BranchDB et CorporateDB. Lorsque nous examinons le tableau dans les bases de données secondaires, de la même manière, nous voyons clairement que nous avons un écart de 30 minutes entre BranchDB et CorporateDB.
Liste 4 – Interroger la table de suivi des journaux
select top 10 @@servername [Current_Server],* from BranchDB.dbo.log_ship_tracker order by RecordTime desc select top 10 @@servername [Current_Server], * from CorporateDB.dbo.log_ship_tracker order by RecordTime desc
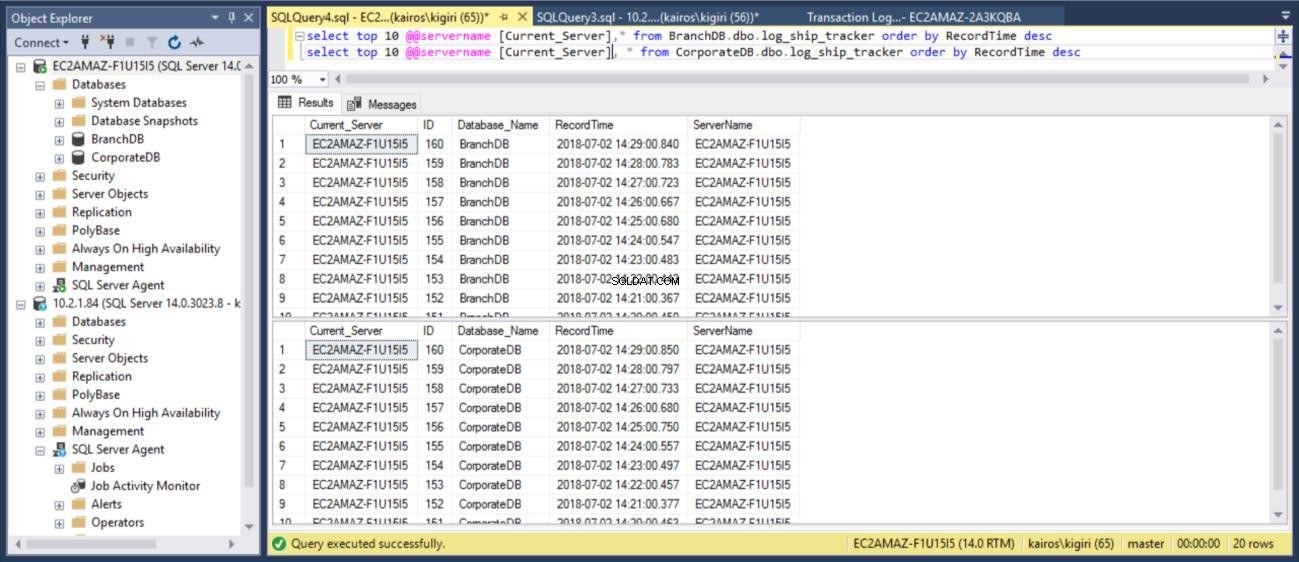
Fig. 9 tables de suivi des journaux correspondent dans les bases de données primaires
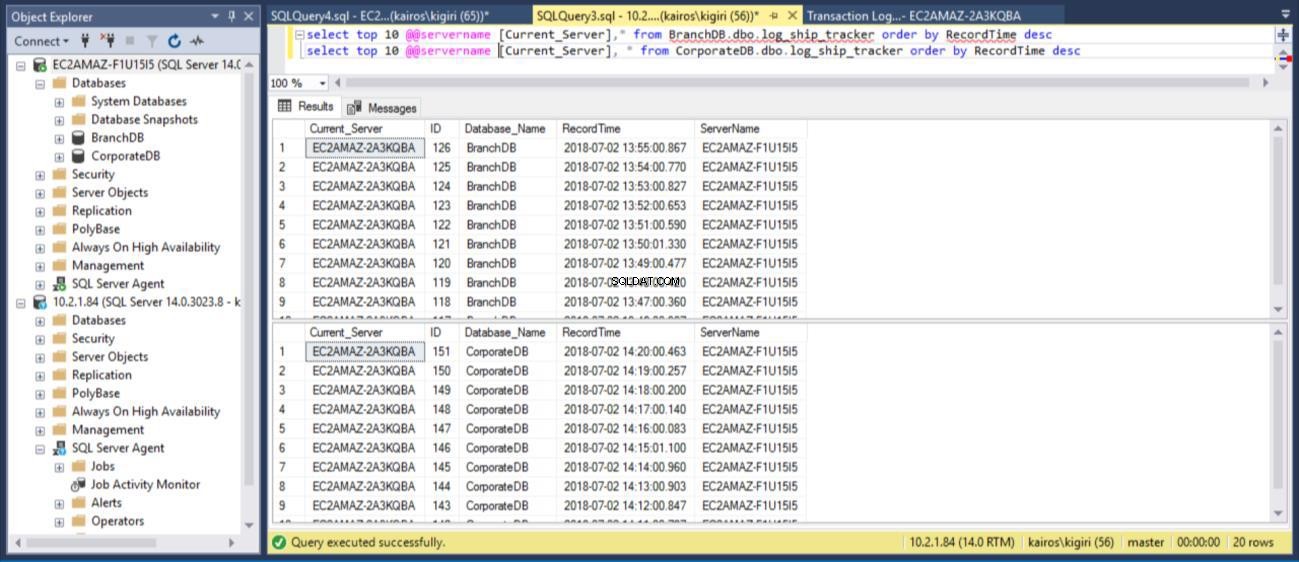
Fig. 10 tables de suivi des journaux ont un écart d'environ 30 minutes dans les bases de données secondaires
Récupération suite à une erreur utilisateur
Parlons maintenant du principal avantage de ce délai. Dans le scénario où un utilisateur supprime par inadvertance une table, nous pouvons récupérer rapidement les données de la base de données secondaire tant que la période de délai ne s'est pas écoulée. Dans cet exemple, nous supprimons la table Sales.Orderlines sur les DEUX bases de données et vérifions que la table n'existe plus dans les DEUX bases de données.
Liste 5 – Suppression du tableau des lignes de commande
drop table BranchDB.Sales.Orderlines drop table CorporateDB.Sales.Orderlines GO use BranchDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO use CorporateDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO
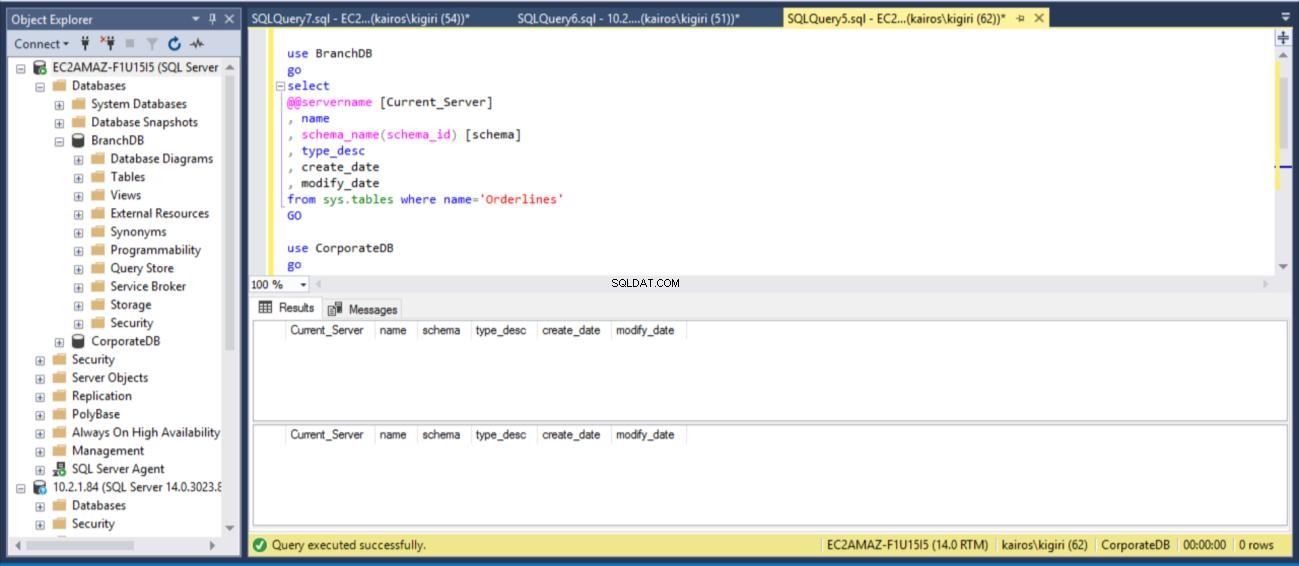
Fig. 11 Suppression des ventes de table.Lignes de commande
Lorsque nous recherchons la table sur le serveur secondaire, nous constatons que la table est toujours disponible dans les DEUX bases de données. Ainsi, pour CorporateDB nous avons moins de cinq minutes pour récupérer les données. (Fig. 12). Mais une fois le prochain cycle de restauration exécuté, nous perdons la table dans la base de données de l'entreprise. Pour récupérer cette table, nous devons effectuer une récupération ponctuelle à l'aide d'une sauvegarde complète dans un environnement séparé, puis extraire cette table spécifique. Vous conviendrez que cela prendra du temps. Pour la table BranchDB Orderlines, nous avons un peu plus de temps et nous pouvons récupérer la table avec une seule instruction SQL sur un serveur lié (voir Listing 6).
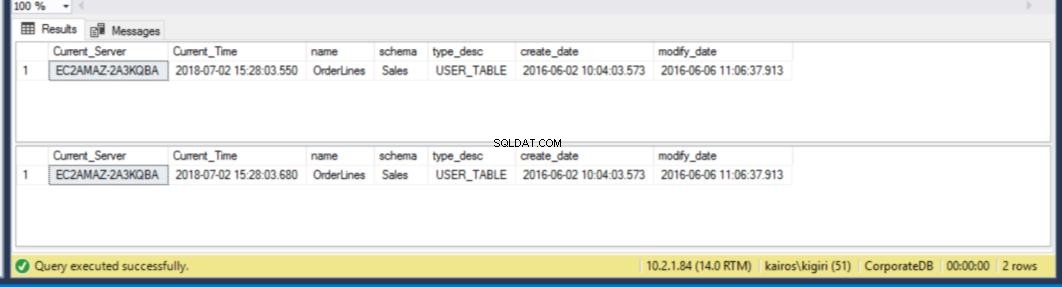
Fig. 12 Compte à rebours de cinq minutes :la table existe dans les deux bases de données secondaires
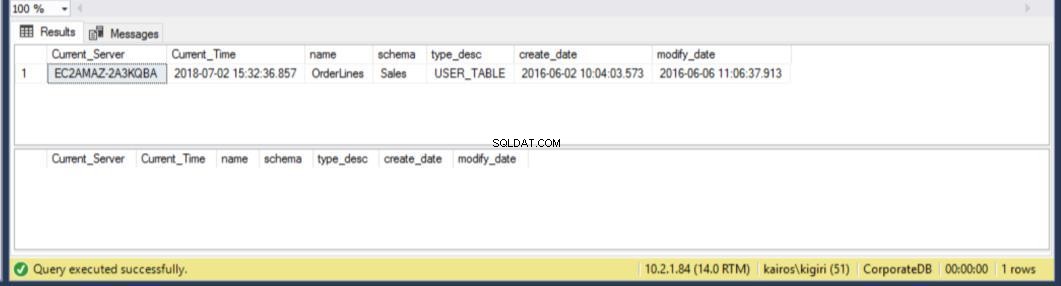
Fig. 13 25 minutes supplémentaires pour récupérer la table BranchDB
Liste 6 – Récupérer le tableau des lignes de commande
USE [master] GO /****** Object: LinkedServer [10.2.1.84] Script Date: 7/2/2018 4:14:59 PM ******/ EXEC master.dbo.sp_addlinkedserver @server = N'10.2.1.84', @srvproduct=N'SQL Server' /* For security reasons the linked server remote logins password is changed with ######## */ EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'10.2.1.84',@useself=N'True',@locallogin=NULL,@rmtuser=NULL,@rmtpasswo rd=NULL GO select * into BranchDB.Sales.Orderlines from [10.2.1.84].BranchDB.Sales.Orderlines
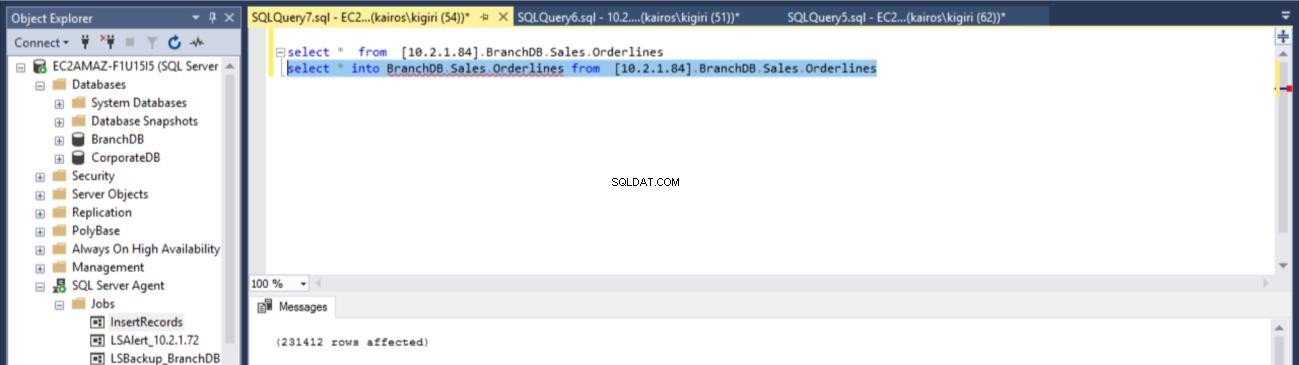
Fig. 14 Récupérer la table BranchDB Sales.Orderlines
Ensuite, nous vérifions sur le serveur primaire (base de données BranchDB) que la table est restaurée.
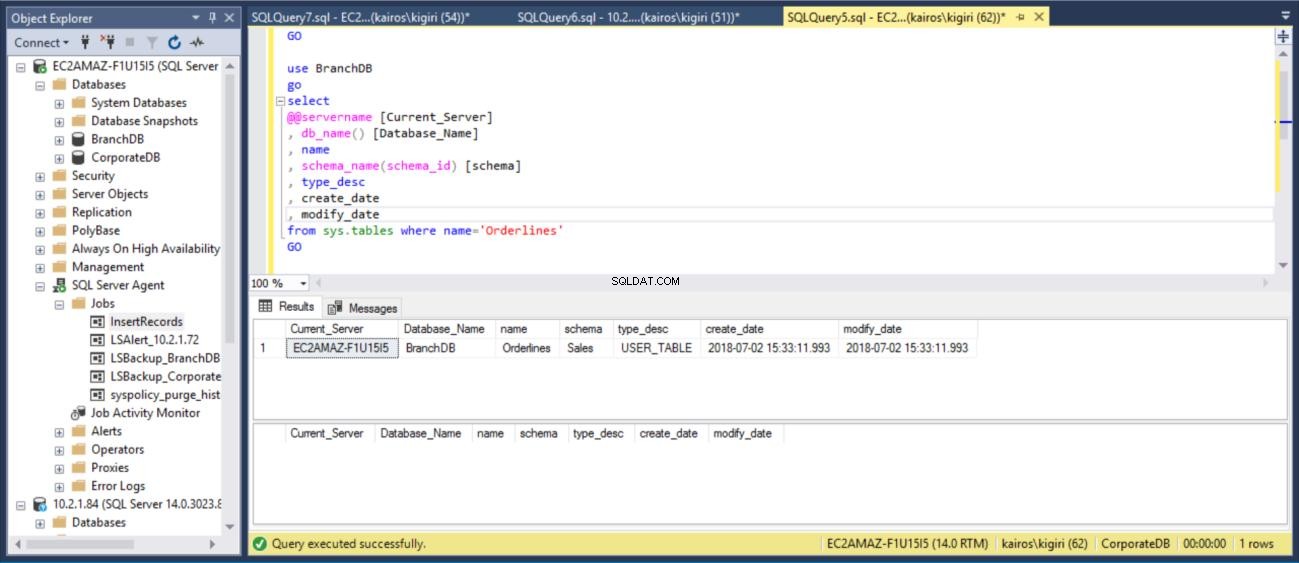
Fig. 15 Récupérer la table BranchDB Sales.Orderlines
Conclusion
SQL Server propose plusieurs méthodes de récupération après une perte de données due à diverses causes profondes :panne de disque, corruption, erreur de l'utilisateur, etc. La récupération ponctuelle à partir de sauvegardes est probablement la plus connue de ces méthodes. Pour certains cas simples d'erreur de l'utilisateur ou le cas similaire, où un ou deux objets sont perdus, l'utilisation de l'envoi du journal des transactions avec récupération différée est une bonne approche à envisager. Cependant, il convient de noter qu'une base de données secondaire, qui est configurée strictement pour les besoins DR, doit être sélectionnée pour des RPO inférieurs.