Le plus souvent, les répliques sont déployées pour une haute disponibilité et/ou une mise à l'échelle de la lecture. Si le primaire échoue, l'un des réplicas est promu au rang de primaire. S'il y a beaucoup de lectures, et c'est presque toujours le cas, des répliques sont ajoutées pour évoluer. Idéalement, les écritures sont acheminées vers le serveur principal et les lectures sont équilibrées sur les répliques. C'est le moyen le plus efficace d'utiliser les ressources disponibles.
RDS, Azure Database et Cloud SQL vous fournissent tous des points de terminaison individuels pour les instances de base de données, un pour le principal et un pour chaque réplica. Si vous souhaitez équilibrer la charge des lectures, vous devez créer plusieurs connexions (une pour chaque réplique) et le faire vous-même. Si vous souhaitez exécuter des écritures sur le primaire et des lectures sur les réplicas (c'est-à-dire un fractionnement en lecture/écriture), vous devez créer une connexion supplémentaire au primaire et le faire vous-même.
Pas drôle. Pas cool.
Avec MaxScale, un proxy de base de données avancé pour MariaDB Enterprise Server, vous n'avez pas à vous en soucier. MaxScale effectue pour vous l'équilibrage de charge en lecture et le fractionnement lecture/écriture - c'est ce que nous appelons le routage transparent des requêtes. Les développeurs ne devraient pas avoir à se soucier de l'infrastructure physique (c'est-à-dire la topologie de la base de données). Pourquoi devraient-ils? Peut-être qu'il y a une réplique, peut-être qu'il y en a cinq. Peut-être que les DBA ont ajouté une réplique hier soir, peut-être qu'ils en ont retiré deux. Cela ne devrait pas avoir d'importance, et les applications ne devraient pas avoir à en tenir compte.
C'est la grande chose à propos de MaxScale. Il fait abstraction de l'infrastructure de base de données sous-jacente et de la topologie de déploiement. C'est peut-être une base de données autonome. C'est peut-être une base de données répliquée. C'est peut-être une base de données en cluster. On s'en fout? Surtout dans le cloud.

Alors, pourquoi pouvez-vous tirer parti du routage transparent des requêtes sur site, mais pas dans le cloud ? Parce que RDS, Azure Database et Google Cloud SQL n'ont pas MaxScale. Si seulement il y avait un DBaaS avec MaxScale et un routage transparent des requêtes. Si seulement nous pouvions monter plus haut avec le cloud MariaDB ultime. Attendez, bonjour SkySQL !
Oui, nous avons apporté la puissance de MaxScale à SkySQL.
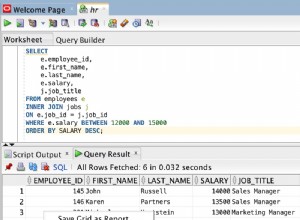
Après avoir créé une base de données répliquée, vous recevez un nom d'hôte et deux ports, un en lecture et un en lecture/écriture. Vous n'avez besoin que du port de lecture/écriture car il lit également l'équilibrage de charge. Mais, si vous avez des applications en lecture seule (par exemple, BI/reporting), le port de lecture peut être utile. Facile.

Vous vous demandez peut-être si Shane vient de partager le nom d'hôte et le port de sa base de données ?
Pourquoi oui, oui je l'ai fait. Par défaut, les bases de données SkySQL ne sont pas accessibles. Vous devez ajouter à la liste blanche les adresses IP (ou plages) de tous les clients et serveurs d'applications nécessitant un accès. Et la seule adresse IP que j'ai mise sur liste blanche est celle de mon ordinateur portable à la maison. Bonne chance. 😉
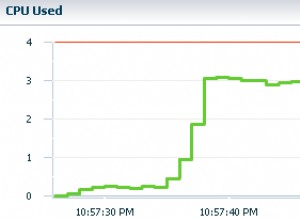
Revenons au sujet à l'étude, vous verrez les deux ports :5001 pour le fractionnement en lecture/écriture (écriture sur le primaire, lecture de la charge équilibrée sur les répliques) et 5002 pour l'équilibrage de charge en lecture seule. Ma base de données a deux répliques, mais les applications qui s'y connectent n'ont pas à s'en soucier. Je pourrais ajouter deux répliques supplémentaires demain, et aucune modification d'application ne serait nécessaire pour en tirer parti. MaxScale commencerait simplement et automatiquement à leur acheminer les lectures.
Et si le primaire échoue, ce n'est pas grave. MaxScale fera automatiquement la promotion d'un réplica et commencera à acheminer les écritures vers celui-ci (et l'équilibrage de charge des lectures sur les réplicas restants). Si vous avez déjà souffert du temps de basculement imprévisible de RDS, vous savez pourquoi. Le basculement RDS est basé sur la propagation DNS, vous n'avez donc pas à modifier le nom d'hôte du point de terminaison. C'est presque transparent, mais cela prend du temps. Avec MaxScale, en revanche, c'est immédiat :aucune propagation DNS n'est requise.
Mais je ne veux pas trop m'éloigner du sujet. J'ai autre chose en tête prévu pour HA. Restez à l'écoute.