La chose la plus importante à comprendre à propos du parallélisme Oracle est qu'il est compliqué. L'optimisation du parallélisme nécessite beaucoup de connaissances Oracle, la lecture des manuels, la vérification de nombreux paramètres, le test de requêtes de longue durée et beaucoup de scepticisme.
Posez les bonnes questions
Les problèmes parallèles impliquent en réalité trois questions différentes :
- Combien de serveurs parallèles ont été demandés ?
- Combien de serveurs parallèles ont été alloués ?
- Combien de serveurs parallèles ont été utilisés de manière significative ?
Utilisez les meilleurs outils
Allez directement au meilleur outil - Surveillance SQL avec des rapports actifs. Trouvez votre SQL_ID et générez le rapport HTML :select dbms_sqltune.report_sql_monitor(sql_id => 'your_sql_id', type => 'active') from dual; . C'est le seul moyen de savoir combien de temps a été consacré à chaque étape du plan d'exécution. Et il vous dira combien de parallélisme a été effectivement utilisé, et où. Par example: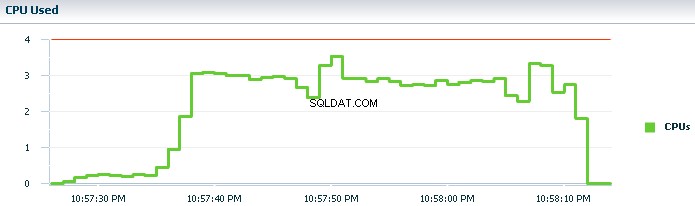
Une autre bonne option est type => 'text' . Il ne contient pas autant d'informations, mais il est plus rapide à consulter et plus facile à partager.
SQL Monitoring inclut également le DOP demandé et le DOP alloué :
Un select parallèle de 100 lignes peut fonctionner à merveille, mais tout s'arrête en une seule étape à cause d'une séquence non mise en cache. Vous pouvez regarder un plan d'exécution, une trace ou un rapport AWR pendant des heures sans voir le problème. Le rapport actif rend les étapes lentes presque insignifiantes à trouver. Ne perdez pas de temps à deviner où se situe le problème.
Cependant, d'autres outils sont encore nécessaires. Un plan d'explication généré avec explain plan for ... et select * from table(dbms_xplan.display); fournira quelques éléments d'information clés. Plus précisément les Notes La section peut inclure de nombreuses raisons pour lesquelles la requête n'a pas demandé le parallélisme.
Mais POURQUOI ai-je eu autant de serveurs parallèles ?
Les informations pertinentes sont réparties sur plusieurs manuels différents, très utiles mais parfois inexacts ou trompeurs. Il existe de nombreux mythes et de nombreux mauvais conseils sur le parallélisme. Et la technologie change considérablement à chaque version.
Lorsque vous rassemblez toutes les sources fiables, la liste des facteurs influençant le nombre de serveurs parallèles est étonnamment longue. La liste ci-dessous est triée approximativement par ce que je pense être les facteurs les plus importants :
- Parallélisme inter-opérations Toute requête utilisant le tri ou le regroupement allouera deux fois plus de serveurs parallèles que le DOP. Ceci est probablement responsable du mythe "Oracle alloue autant de serveurs parallèles que possible !".
- Indice de requête De préférence un indice au niveau de l'instruction comme
/*+ parallel */, ou éventuellement un indice au niveau de l'objet comme/*+ noparallel(table1) */. Si une étape spécifique d'un plan s'exécute en série, c'est généralement en raison d'indications au niveau de l'objet sur une partie seulement de la requête. - SQL récursif Certaines opérations peuvent s'exécuter en parallèle mais peuvent être efficacement sérialisées par SQL récursif. Par exemple, une séquence non mise en cache sur un gros insert. Le SQL récursif généré pour analyser l'instruction sera également en série ; par exemple des requêtes d'échantillonnage dynamique.
- Modifier la session
alter session [force|enable] parallel [query|dml|ddl];Notez que le DML parallèle est désactivé par défaut. - Diplôme de table
- Degré d'indice
- L'index était moins cher Les indications parallèles indiquent uniquement à l'optimiseur d'envisager une analyse complète de la table avec un certain DOP. Ils ne forcent pas réellement le parallélisme. L'optimiseur est toujours libre d'utiliser un accès à l'index série s'il pense que c'est moins cher. (Le
FULLun indice peut aider à résoudre ce problème.) - Gestion des forfaits Les lignes de base du plan SQL, les contours, les profils, la réécriture avancée et les traducteurs SQL peuvent tous modifier le degré de parallélisme derrière votre dos. Consultez la section Remarque du plan.
- Édition Seules les éditions Enterprise et Personal autorisent les opérations parallèles. Sauf pour le package DBMS_PARALLEL_EXECUTE.
- PARALLEL_ADAPTIVE_MULTI_USER
- PARALLEL_AUTOMATIC_TUNING
- PARALLEL_DEGREE_LIMIT
- PARALLEL_DEGREE_POLICY
- PARALLEL_FORCE_LOCAL
- PARALLEL_INSTANCE_GROUP
- PARALLEL_IO_CAP_ENABLED
- PARALLEL_MAX_SERVERS C'est la limite supérieure pour l'ensemble du système. Il y a un compromis ici. Exécuter trop de serveurs parallèles à la fois est mauvais pour le système. Mais rétrograder une requête en série peut être désastreux pour certaines requêtes.
- PARALLEL_MIN_PERCENT
- PARALLEL_MIN_SERVERS
- PARALLEL_MIN_TIME_THRESHOLD
- PARALLEL_SERVERS_TARGET
- PARALLEL_THREADS_PER_CPU
- Nombre de nœuds RAC Un autre multiplicateur pour le DOP par défaut.
- CPU_COUNT Si le DOP par défaut est utilisé.
- RECOVERY_PARALLELISM
- FAST_START_PARALLEL_ROLLBACK
- Profil
SESSIONS_PER_USERlimite également les serveurs parallèles. - Gestionnaire des ressources
- Charge du système Si parallel_adaptive_multi_user est vrai. Probablement impossible de deviner quand Oracle commencera à ralentir.
- PROCESSUS
- Restrictions DML parallèles Parallel DML ne fonctionnera pas si l'un de ces cas :
- COMPATIBLE <9.2 pour l'intra-partition
- INSÉRER DES VALEURS, tableaux avec déclencheurs
- réplication
- intégrité auto-référentielle ou suppression des contraintes d'intégrité en cascade ou différée
- accéder à une colonne d'objets
- table non partitionnée avec LOB
- parallélisme intra-partition avec un LOB
- transaction distribuée
- tables en cluster
- tableaux temporaires
- Les sous-requêtes scalaires ne s'exécutent pas en parallèle ? C'est dans le manuel, et j'aimerais que ce était vrai, mais mes tests indiquent que le parallélisme fonctionne ici en 11g.
- ENQUEUE_RESOURCES Paramètre caché dans 10g, est-ce plus pertinent ?
- Tableaux organisés en index Impossible d'insérer le chemin direct vers les IOT en parallèle ? (Est-ce toujours vrai ?)
- Exigences des fonctions en pipeline parallèle Doit utiliser un
CURSOR(?). À FAIRE. - Les fonctions doivent être PARALLEL_ENABLE
- Type de déclaration Les anciennes versions limitaient le parallélisme sur DML en fonction du partitionnement. Certains des manuels actuels incluent encore cela, mais ce n'est certainement plus vrai.
- Nombre de partitions Uniquement pour les jointures par partition sur les anciennes versions.(?)
- Bogues Plus précisément, j'ai vu beaucoup de bugs avec l'analyse. Oracle allouera le bon nombre de serveurs parallèles mais rien ne se passera car ils attendent tous des événements comme
cursor: pin s wait on x.
Cette liste n'est certainement pas complète et n'inclut pas les fonctionnalités 12c. Et il ne résout pas les problèmes de système d'exploitation et de matériel. Et cela ne répond pas à la question horriblement difficile, "quel est le meilleur degré de parallélisme?" (Réponse courte :plus c'est généralement mieux, mais au détriment d'autres processus.) J'espère que cela vous donne au moins une idée de la difficulté de ces problèmes et un bon endroit pour commencer à chercher.