Un point de défaillance unique (SPOF) est une raison courante pour laquelle les organisations s'efforcent de répartir la présence de leurs environnements de base de données vers un autre emplacement géographique. Cela fait partie des plans stratégiques de reprise après sinistre et de continuité des activités.
La planification de reprise après sinistre (DR) comprend des procédures techniques qui couvrent la préparation à des problèmes imprévus tels que des catastrophes naturelles, des accidents (tels qu'une erreur humaine) ou des incidents (tels que des actes criminels).
Au cours de la dernière décennie, la distribution de votre environnement de base de données sur plusieurs emplacements géographiques a été une configuration assez courante, car les clouds publics offrent de nombreuses façons de gérer cela. Le défi réside dans la configuration des environnements de base de données. Cela crée des défis lorsque vous essayez de gérer la ou les bases de données, de déplacer vos données vers une autre géolocalisation ou d'appliquer une sécurité avec un niveau élevé d'observabilité.
Dans ce blog, nous vous montrerons comment vous pouvez faire cela en utilisant la réplication MySQL. Nous verrons comment vous pouvez copier vos données vers un autre nœud de base de données situé dans un pays différent éloigné de la géographie actuelle du cluster MySQL. Pour cet exemple, notre région cible est basée sur nous-est, tandis que mon site sur site se trouve en Asie, aux Philippines.
Pourquoi ai-je besoin d'un cluster de bases de données de géolocalisation ?
Même Amazon AWS, le principal fournisseur de cloud public, affirme souffrir de temps d'arrêt ou de pannes involontaires (comme celle qui s'est produite en 2017). Supposons que vous utilisez AWS comme centre de données secondaire en dehors de votre site sur site. Vous ne pouvez pas avoir d'accès interne à son matériel sous-jacent ou aux réseaux internes qui gèrent vos nœuds de calcul. Ce sont des services entièrement gérés pour lesquels vous avez payé, mais vous ne pouvez pas éviter le fait qu'ils peuvent souffrir d'une panne à tout moment. Si un tel emplacement géographique subit une panne, vous pouvez avoir un long temps d'arrêt.
Ce type de problème doit être prévu lors de votre plan de continuité d'activité. Il doit avoir été analysé et mis en œuvre en fonction de ce qui a été défini. La continuité des activités de vos bases de données MySQL doit inclure une disponibilité élevée. Certains environnements font des benchmarks et placent la barre haute de tests rigoureux, y compris le côté faible afin d'exposer toute vulnérabilité, sa résilience et l'évolutivité de votre architecture technologique, y compris votre infrastructure de base de données. Pour les entreprises, en particulier celles qui gèrent des transactions élevées, il est impératif de s'assurer que les bases de données de production sont disponibles pour les applications à tout moment, même en cas de catastrophe. Sinon, des temps d'arrêt peuvent survenir et cela peut vous coûter beaucoup d'argent.
Grâce à ces scénarios identifiés, les organisations commencent à étendre leur infrastructure à différents fournisseurs de cloud et à placer des nœuds dans différentes géolocalisations pour avoir une disponibilité plus élevée (si possible à 99,99999999999), un RPO inférieur et sans SPOF.
Pour garantir que les bases de données de production survivent à un sinistre, un site de reprise après sinistre (DR) doit être configuré. Les sites de production et de DR doivent faire partie de deux centres de données géographiquement distants. Cela signifie qu'une base de données de secours doit être configurée sur le site DR pour chaque base de données de production afin que les modifications de données se produisant sur la base de données de production soient immédiatement synchronisées avec la base de données de secours via les journaux de transactions. Certaines configurations utilisent également leurs nœuds DR pour gérer les lectures afin de fournir un équilibrage de charge entre l'application et la couche de données.
La configuration architecturale souhaitée
Dans ce blog, la configuration souhaitée est une mise en œuvre simple et pourtant très courante de nos jours. Voir ci-dessous la configuration architecturale souhaitée pour ce blog :
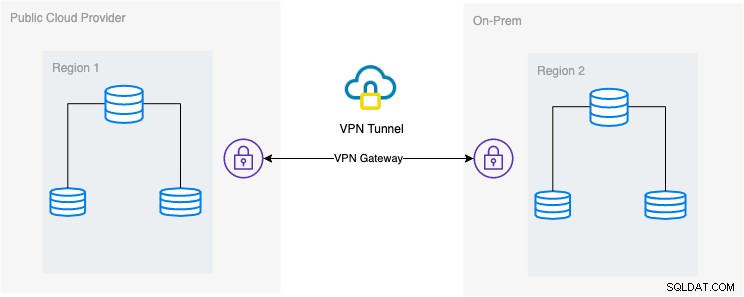
Dans ce blog, je choisis Google Cloud Platform (GCP) comme public fournisseur de cloud et utiliser mon réseau local comme environnement de base de données sur site.
Il est indispensable que lors de l'utilisation de ce type de conception, vous ayez toujours besoin à la fois d'un environnement ou d'une plate-forme pour communiquer de manière très sécurisée. Utilisation d'un VPN ou d'alternatives telles qu'AWS Direct Connect. Bien que ces clouds publics offrent aujourd'hui des services VPN gérés que vous pouvez utiliser. Mais pour cette configuration, nous utiliserons OpenVPN car je n'ai pas besoin de matériel ou de service sophistiqué pour ce blog.
Méthode la meilleure et la plus efficace
Pour les environnements de base de données MySQL/Percona/MariaDB, le moyen le plus efficace et le plus efficace consiste à effectuer une copie de sauvegarde de votre base de données, à envoyer au nœud cible à déployer ou à instancier. Il existe différentes façons d'utiliser cette approche, soit vous pouvez utiliser mysqldump, mydumper, rsync, ou utiliser Percona XtraBackup/Mariabackup et diffuser les données vers votre nœud cible.
Utiliser mysqldump
mysqldump crée une sauvegarde logique de toute votre base de données ou vous pouvez choisir de manière sélective une liste de bases de données, de tables ou même d'enregistrements spécifiques que vous vouliez vider.
Une commande simple que vous pouvez utiliser pour effectuer une sauvegarde complète peut être,
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsAvec cette simple commande, il exécutera directement les instructions MySQL sur le nœud de base de données cible, par exemple votre nœud de base de données cible sur un Google Compute Engine. Cela peut être efficace lorsque les données sont plus petites ou que vous disposez d'une bande passante rapide. Sinon, emballer votre base de données dans un fichier puis l'envoyer au nœud cible peut être votre option.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathEnsuite, exécutez mysqldump sur le nœud de la base de données cible en tant que tel,
zcat mydata.db | mysqlL'inconvénient de l'utilisation de la sauvegarde logique avec mysqldump est qu'elle est plus lente et consomme de l'espace disque. Il utilise également un seul thread, vous ne pouvez donc pas l'exécuter en parallèle. En option, vous pouvez utiliser mydumper en particulier lorsque vos données sont trop volumineuses. mydumper peut être exécuté en parallèle mais il n'est pas aussi flexible que mysqldump.
Utiliser xtrabackup
xtrabackup est une sauvegarde physique où vous pouvez envoyer les flux ou le binaire au nœud cible. Ceci est très efficace et est principalement utilisé lors de la diffusion en continu d'une sauvegarde sur le réseau, en particulier lorsque le nœud cible est d'une géographie ou d'une région différente. ClusterControl utilise xtrabackup lors du provisionnement ou de l'instanciation d'un nouvel esclave, quel que soit son emplacement, tant que l'accès et l'autorisation ont été configurés avant l'action.
Si vous utilisez xtrabackup pour l'exécuter manuellement, vous pouvez exécuter la commande en tant que telle,
## nœud cible
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## nœud source
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999Pour élaborer ces deux commandes, la première commande doit être exécutée ou exécutée en premier sur le nœud cible. La commande du nœud cible écoute sur le port 9999 et écrira tout flux reçu du port 9999 dans le nœud cible. Il dépend des commandes socat et xbstream, ce qui signifie que vous devez vous assurer que ces packages sont installés.
Sur le nœud source, il exécute le script perl innobackupex qui invoque xtrabackup en arrière-plan et utilise xbstream pour diffuser les données qui seront envoyées sur le réseau. La commande socat ouvre le port 9999 et envoie ses données à l'hôte souhaité, qui est 192.168.10.70 dans cet exemple. Assurez-vous tout de même que socat et xbstream sont installés lorsque vous utilisez cette commande. Une autre façon d'utiliser socat est nc mais socat offre des fonctionnalités plus avancées par rapport à nc telles que la sérialisation comme plusieurs clients peuvent écouter sur un port.
ClusterControl utilise cette commande lors de la reconstruction d'un esclave ou de la construction d'un nouvel esclave. Il est rapide et garantit que la copie exacte de vos données source sera copiée sur votre nœud cible. Lors du provisionnement d'une nouvelle base de données dans une géolocalisation distincte, l'utilisation de cette approche offre plus d'efficacité et vous offre plus de rapidité pour terminer le travail. Bien qu'il puisse y avoir des avantages et des inconvénients lors de l'utilisation d'une sauvegarde logique ou binaire lorsqu'elle est diffusée via le câble. L'utilisation de cette méthode est une approche très courante lors de la configuration d'un nouveau cluster de base de données de géolocalisation dans une région différente et de la création d'une copie exacte de votre environnement de base de données.
Efficacité, observabilité et rapidité
Les questions laissées par la plupart des gens qui ne sont pas familiers avec cette approche couvrent toujours les problèmes "COMMENT, QUOI, OÙ". Dans cette section, nous expliquerons comment vous pouvez configurer efficacement votre base de données de géolocalisation avec moins de travail à gérer et avec l'observabilité pourquoi elle échoue. L'utilisation de ClusterControl est très efficace. Dans cette configuration actuelle, j'ai l'environnement suivant tel qu'initialement implémenté :
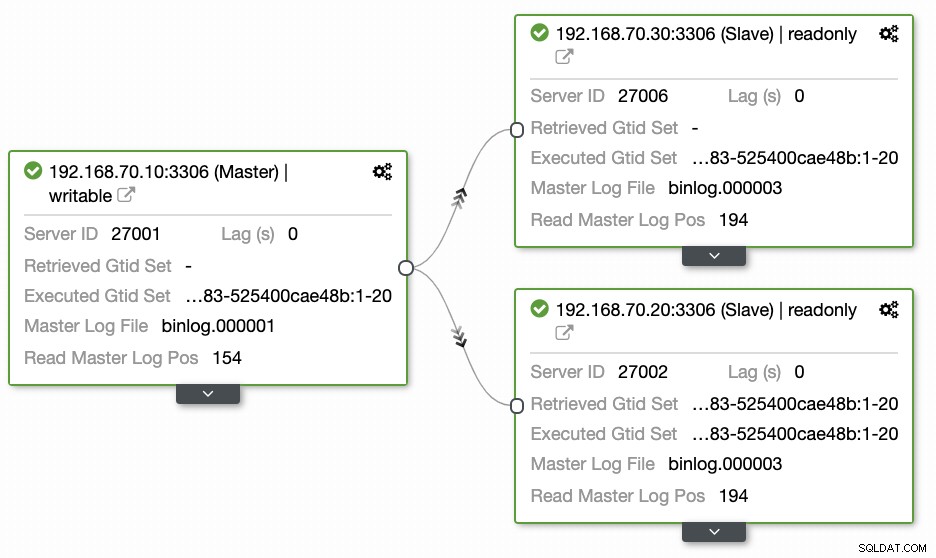
Étendre le nœud à GCP
En commençant à configurer votre cluster de base de données de géolocalisation, pour étendre votre cluster et créer une copie instantanée de votre cluster, vous pouvez ajouter un nouvel esclave. Comme mentionné précédemment, ClusterControl utilisera xtrabackup (mariabackup pour MariaDB 10.2 et versions ultérieures) et déploiera un nouveau nœud dans votre cluster. Avant de pouvoir enregistrer vos nœuds de calcul GCP en tant que nœuds cibles, vous devez d'abord configurer l'utilisateur système approprié, identique à l'utilisateur système que vous avez enregistré dans ClusterControl. Vous pouvez le vérifier dans votre /etc/cmon.d/cmon_X.cnf, où X est le cluster_id. Par exemple, voir ci-dessous :
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (dans cet exemple) doit être présent dans vos nœuds de calcul GCP. L'utilisateur de vos nœuds GCP doit disposer des privilèges sudo ou super administrateur. Il doit également être configuré avec un accès SSH sans mot de passe. Veuillez lire notre documentation pour en savoir plus sur l'utilisateur du système et ses privilèges requis.
Prenons un exemple de liste de serveurs ci-dessous (à partir de la console GCP :tableau de bord Compute Engine) :
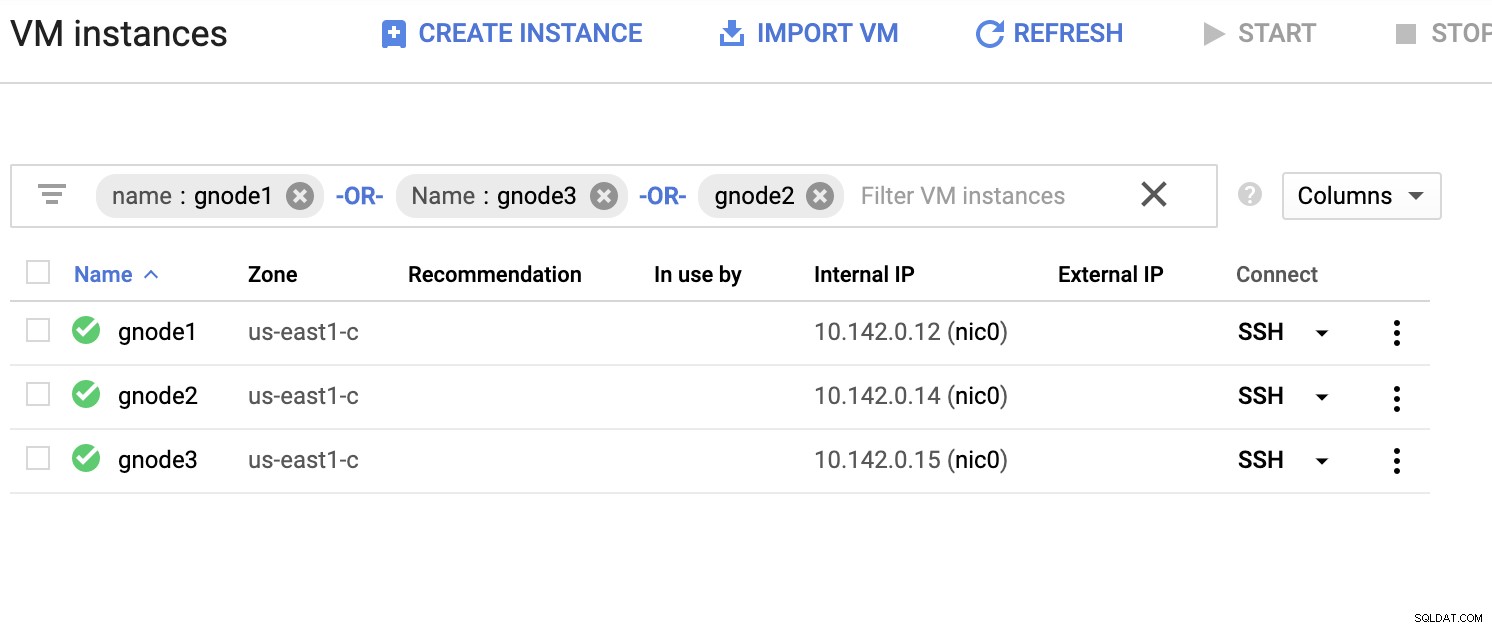
Dans la capture d'écran ci-dessus, notre région cible est basée sur la région us-east Région. Comme indiqué précédemment, mon réseau local est configuré sur une couche sécurisée passant par GCP (vice-versa) en utilisant OpenVPN. Ainsi, la communication de GCP vers mon réseau local est également encapsulée via le tunnel VPN.
Ajouter un nœud esclave à GCP
La capture d'écran ci-dessous montre comment procéder. Voir les images ci-dessous :
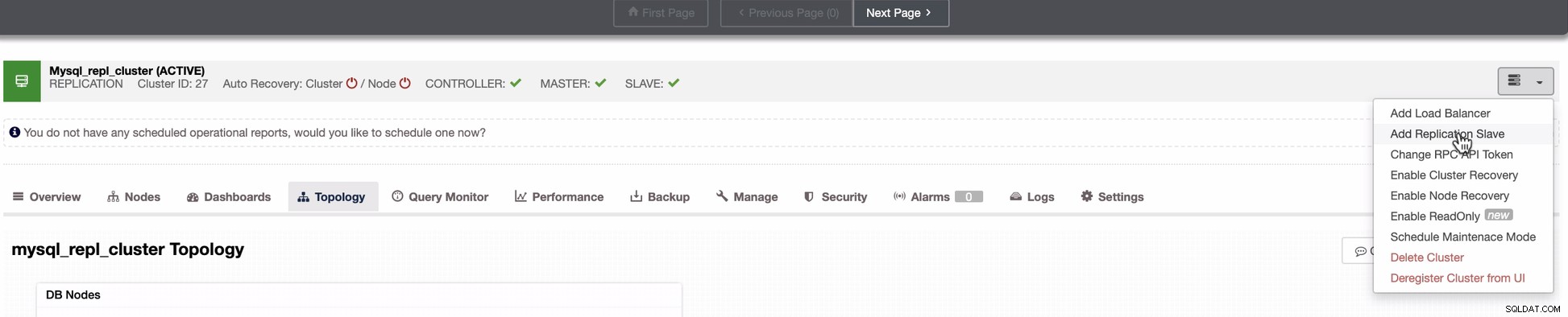
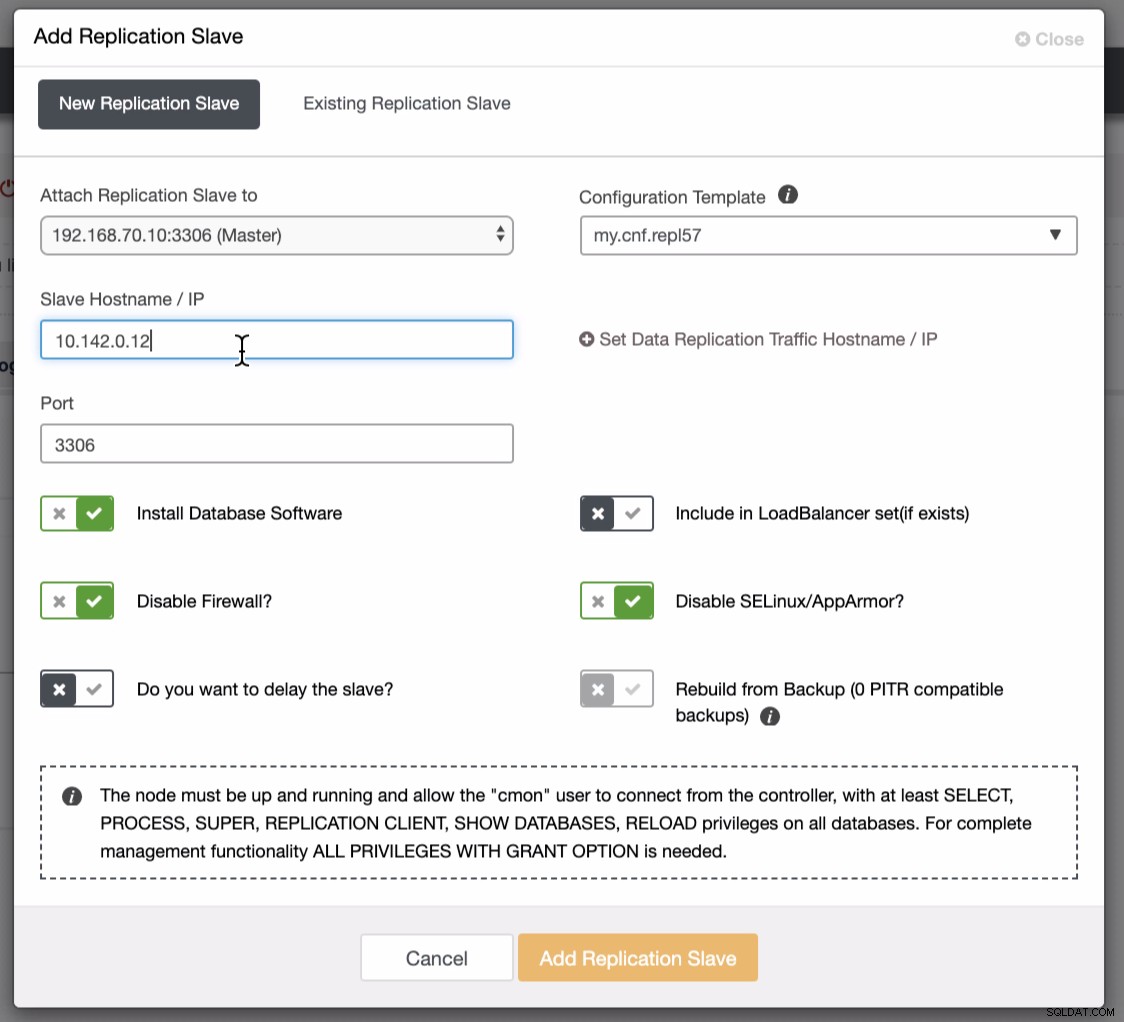
Comme le montre la deuxième capture d'écran, nous ciblons le nœud 10.142.0.12 et son maître source est 192.168.70.10. ClusterControl est suffisamment intelligent pour déterminer les pare-feu, les modules de sécurité, les packages, la configuration et l'installation à effectuer. Voir ci-dessous un exemple de journal d'activité :
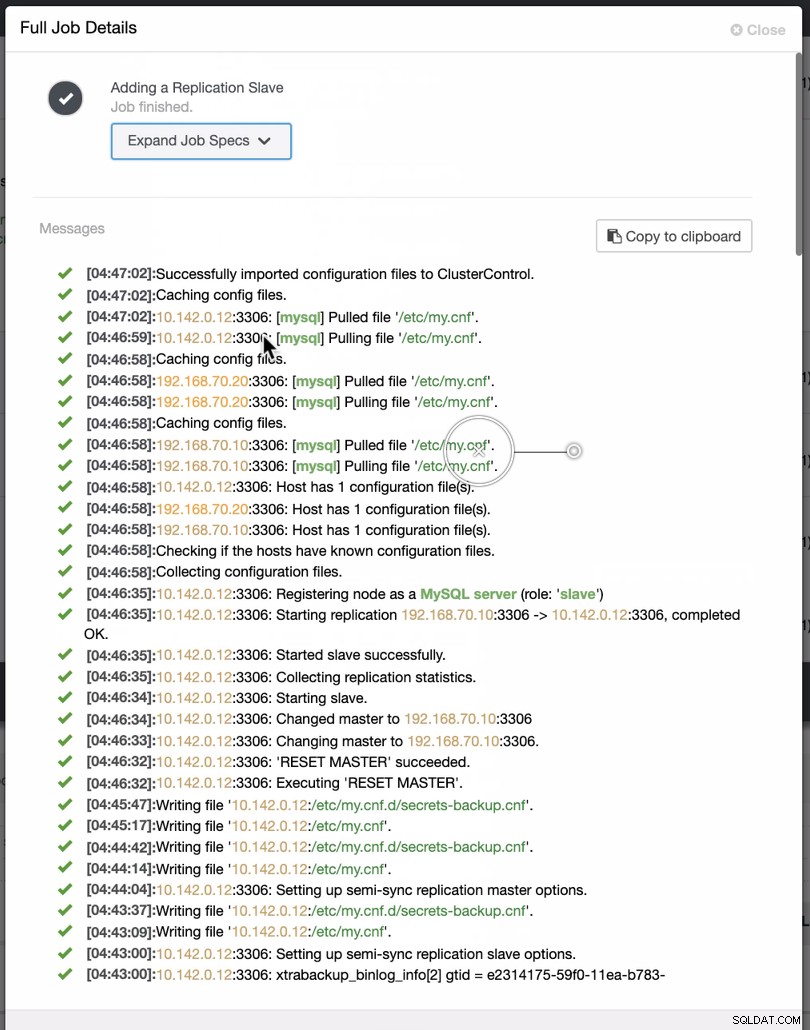
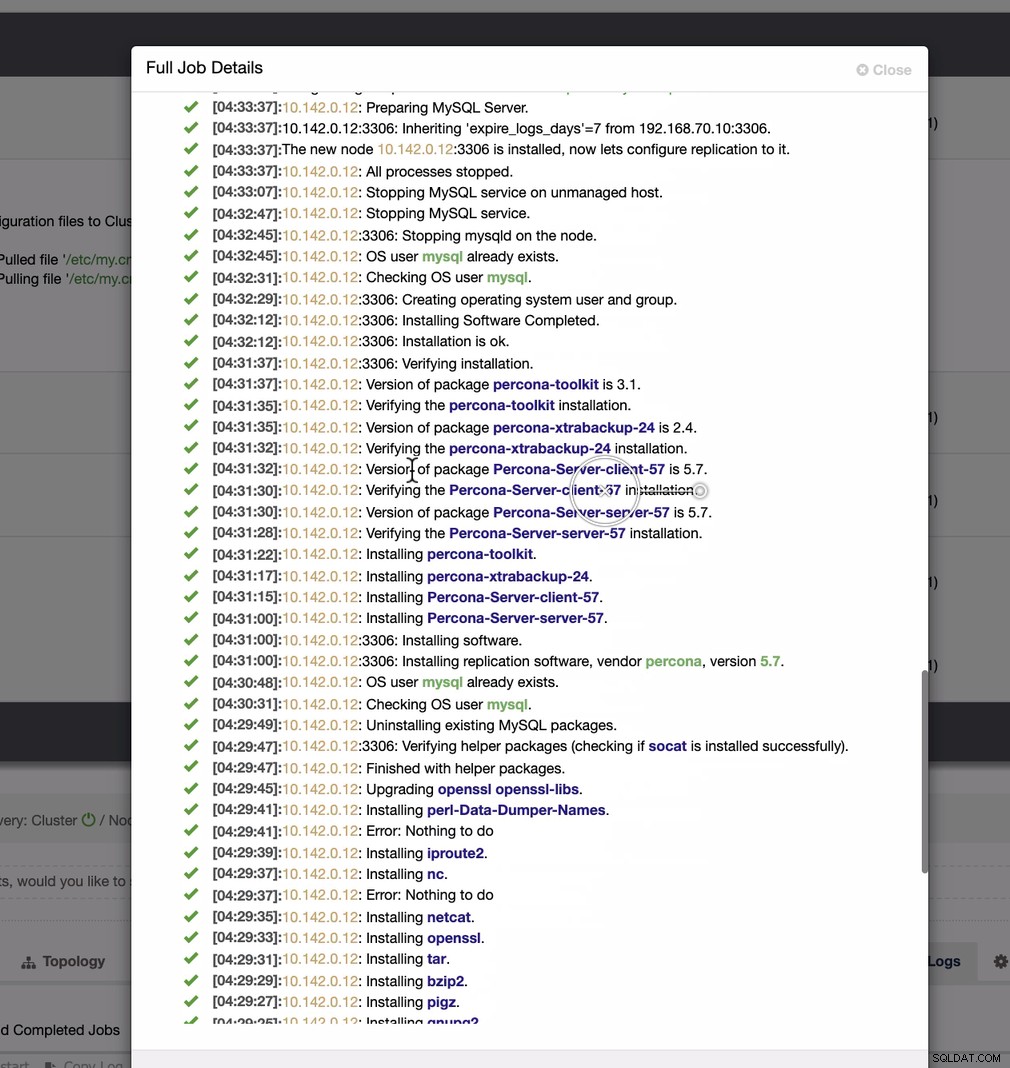
Une tâche assez simple, n'est-ce pas ?
Compléter le cluster GCP MySQL
Nous devons ajouter deux nœuds supplémentaires au cluster GCP pour avoir une topologie équilibrée comme nous l'avons fait dans le réseau local. Pour les deuxième et troisième nœuds, assurez-vous que le maître doit pointer vers votre nœud GCP. Dans cet exemple, le maître est 10.142.0.12. Voir ci-dessous comment procéder,
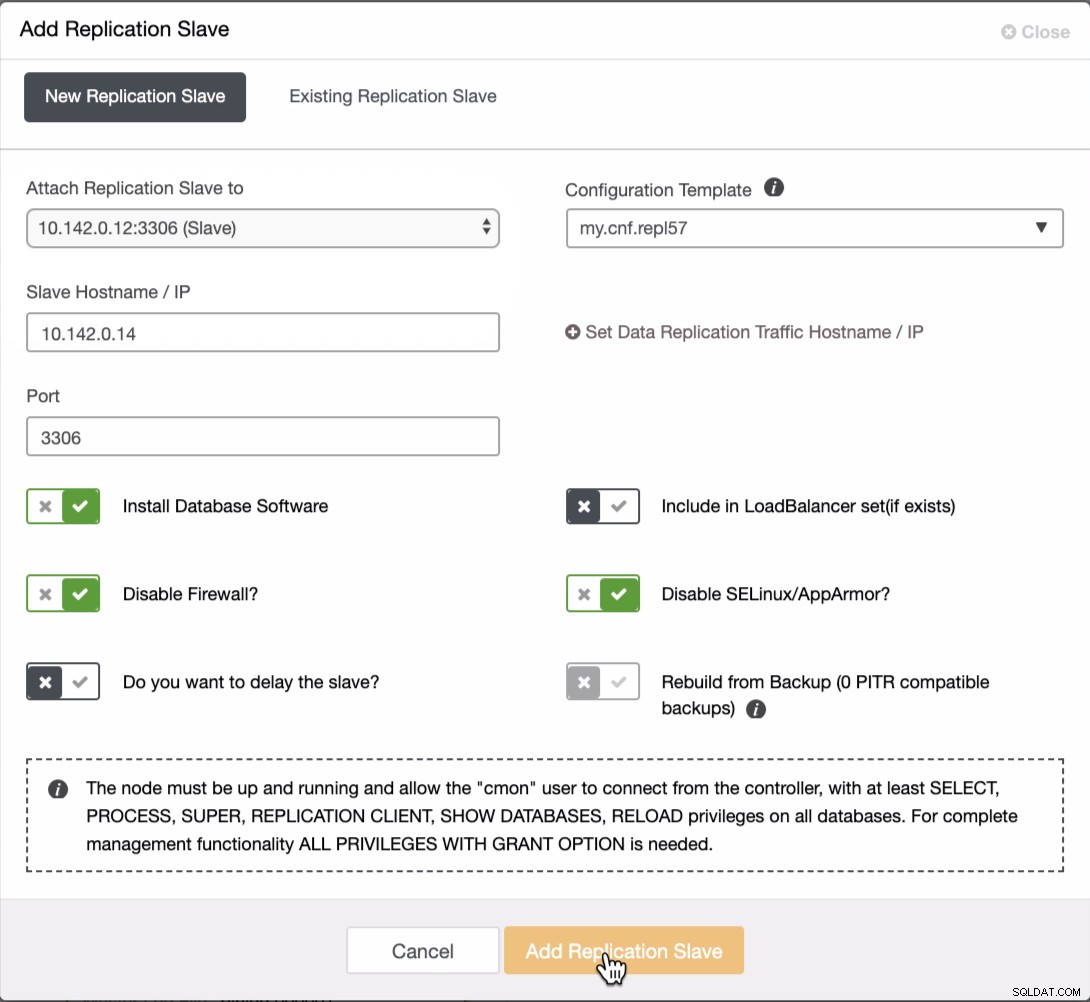
Comme on le voit dans la capture d'écran ci-dessus, j'ai sélectionné le 10.142.0.12 (esclave ) qui est le premier nœud que nous avons ajouté au cluster. Le résultat complet s'affiche comme suit,
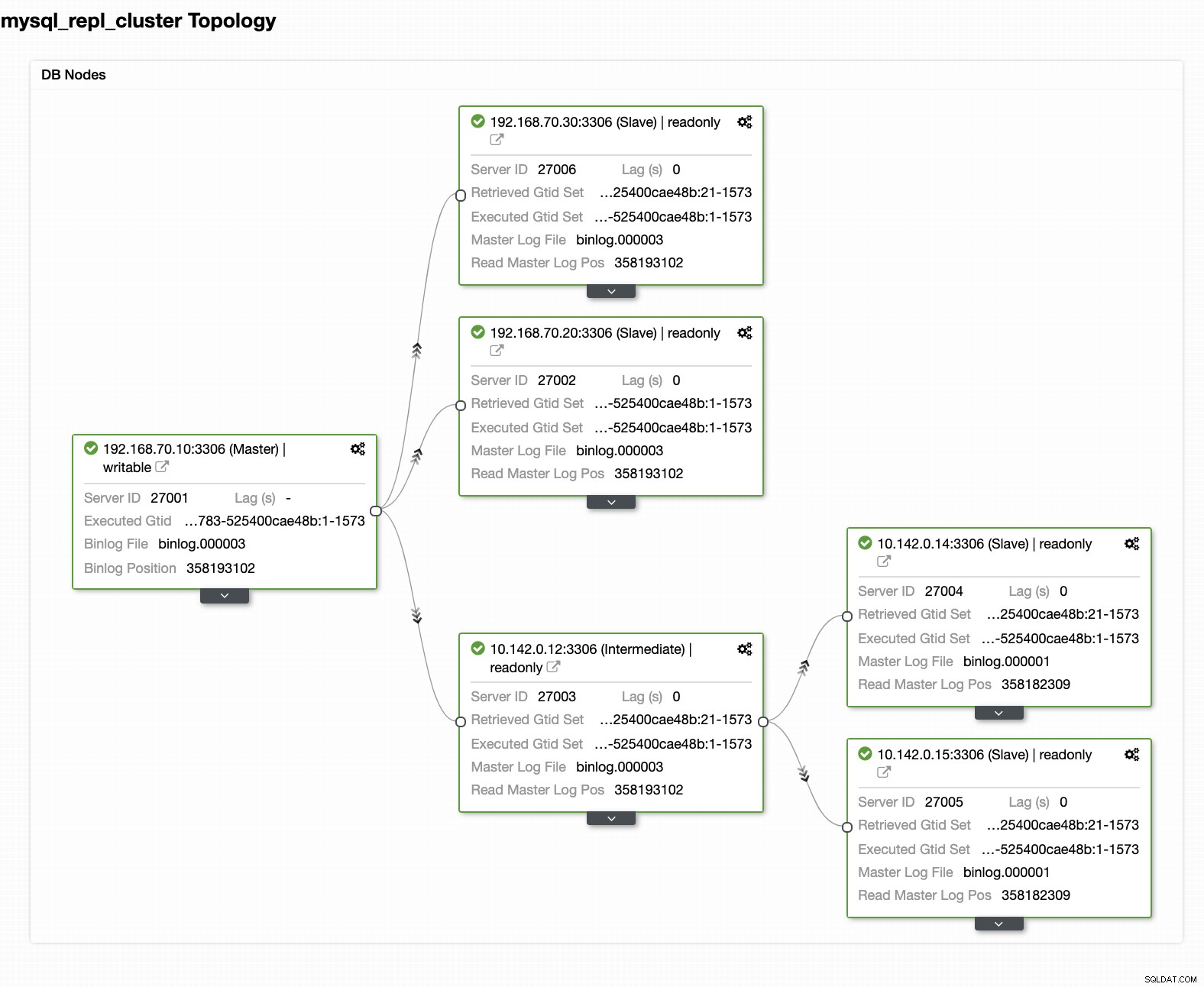
Votre configuration finale du cluster de bases de données de géolocalisation
D'après la dernière capture d'écran, ce type de topologie n'est peut-être pas votre configuration idéale. La plupart du temps, il doit s'agir d'une configuration multimaître, où votre cluster DR sert de cluster de secours, tandis que votre local sert de cluster actif principal. Pour ce faire, c'est assez simple dans ClusterControl. Voir les captures d'écran suivantes pour atteindre cet objectif.
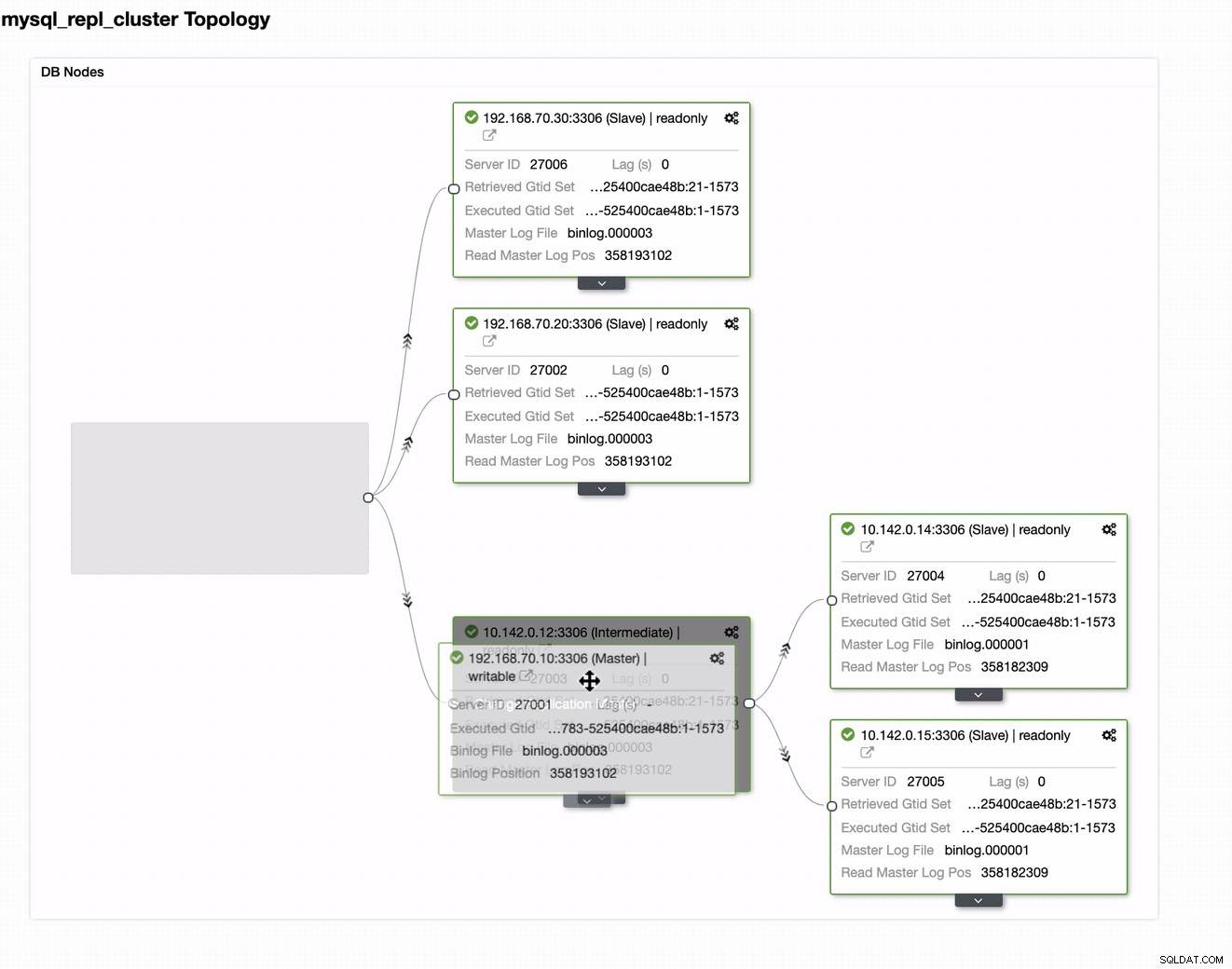
Vous pouvez simplement faire glisser votre maître actuel vers le maître cible qui doit être configurer en tant qu'écrivain de secours principal au cas où votre site serait en danger. Dans cet exemple, nous faisons glisser l'hôte de ciblage 10.142.0.12 (nœud de calcul GCP). Le résultat final est illustré ci-dessous :
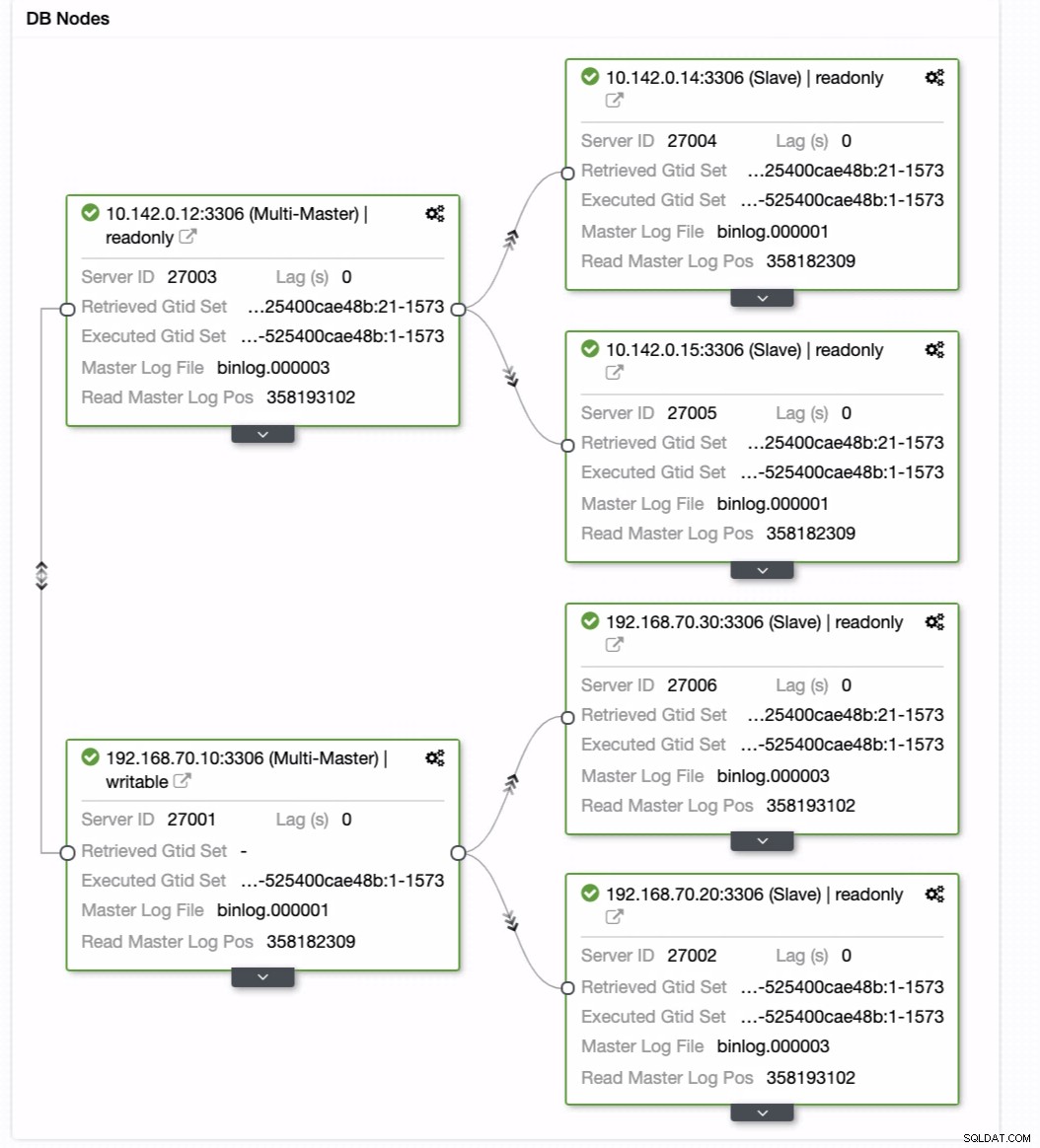
Ensuite, il atteint le résultat souhaité. Création simple et très rapide de votre cluster de base de données de géolocalisation à l'aide de la réplication MySQL.
Conclusion
Avoir un cluster de bases de données de géolocalisation n'est pas nouveau. Il s'agit d'une configuration souhaitée pour les entreprises et les organisations qui évitent le SPOF et qui souhaitent de la résilience et un RPO inférieur.
Les principaux points à retenir de cette configuration sont la sécurité, la redondance et la résilience. Il couvre également la faisabilité et l'efficacité du déploiement de votre nouveau cluster dans une autre région géographique. Bien que ClusterControl puisse offrir cela, attendez-vous à ce que nous puissions avoir plus d'améliorations sur ce point plus tôt où vous pouvez créer efficacement à partir d'une sauvegarde et générer votre nouveau cluster différent dans ClusterControl, alors restez à l'écoute.