Ajout : SQL Server 2012 affiche des performances améliorées dans ce domaine, mais ne semble pas résoudre les problèmes spécifiques indiqués ci-dessous. Cela devrait apparemment être corrigé dans la prochaine version majeure après SQL Server 2012 !
Votre plan montre que les insertions uniques utilisent des procédures paramétrées (éventuellement paramétrées automatiquement), donc le temps d'analyse/compilation pour celles-ci devrait être minimal.
J'ai pensé que j'examinerais cela un peu plus, alors configurez une boucle (script) et essayez d'ajuster le nombre de VALUES clauses et enregistrement du temps de compilation.
J'ai ensuite divisé le temps de compilation par le nombre de lignes pour obtenir le temps de compilation moyen par clause. Les résultats sont ci-dessous
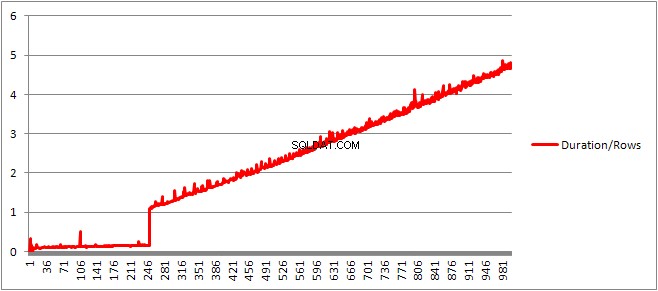
Jusqu'à 250 VALUES clauses présentes le temps de compilation/nombre de clauses a une légère tendance à la hausse mais rien de trop dramatique.
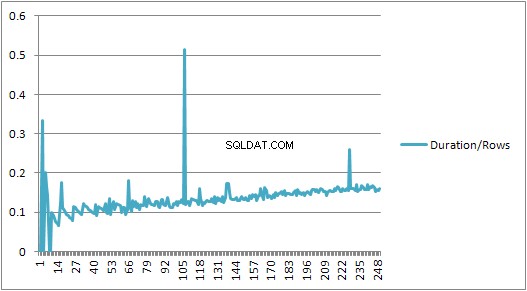
Mais ensuite, il y a un changement soudain.
Cette section des données est illustrée ci-dessous.
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
La taille du plan mis en cache qui avait augmenté de manière linéaire chute soudainement, mais CompileTime augmente de 7 fois et CompileMemory monte en flèche. C'est le point de coupure entre le plan étant un plan paramétré automatiquement (avec 1 000 paramètres) et un plan non paramétré. Par la suite, il semble devenir linéairement moins efficace (en termes de nombre de clauses de valeur traitées dans un temps donné).
Je ne sais pas pourquoi cela devrait être. Vraisemblablement, lorsqu'il compile un plan pour des valeurs littérales spécifiques, il doit effectuer une activité qui n'évolue pas de manière linéaire (comme le tri).
Cela ne semble pas affecter la taille du plan de requête mis en cache lorsque j'ai essayé une requête composée entièrement de lignes en double et n'affecte pas non plus l'ordre de sortie de la table des constantes (et comme vous insérez dans un tas le temps passé à trier serait inutile de toute façon, même si c'était le cas).
De plus, si un index clusterisé est ajouté à la table, le plan affiche toujours une étape de tri explicite, de sorte qu'il ne semble pas trier au moment de la compilation pour éviter un tri au moment de l'exécution.

J'ai essayé de regarder cela dans un débogueur mais les symboles publics de ma version de SQL Server 2008 ne semblent pas être disponibles, j'ai donc dû regarder l'équivalent UNION ALL construction dans SQL Server 2005.
Une trace de pile typique est ci-dessous
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
Donc, en partant des noms dans la trace de la pile, il semble passer beaucoup de temps à comparer les chaînes.
Cet article de la base de connaissances indique que DeriveNormalizedGroupProperties est associé à ce qu'on appelait autrefois l'étape de normalisation du traitement des requêtes
Cette étape est maintenant appelée liaison ou algébrisation et elle prend la sortie de l'arbre d'analyse d'expression de l'étape d'analyse précédente et génère un arbre d'expression algébrisé (arbre du processeur de requêtes) pour passer à l'optimisation (optimisation du plan trivial dans ce cas) [ref].
J'ai essayé une autre expérience (Script) qui consistait à relancer le test d'origine mais en examinant trois cas différents.
- Chaînes de prénom et de nom de 10 caractères sans doublons.
- Chaînes de prénom et de nom de 50 caractères sans doublons.
- Chaînes de prénom et de nom de 10 caractères avec tous les doublons.
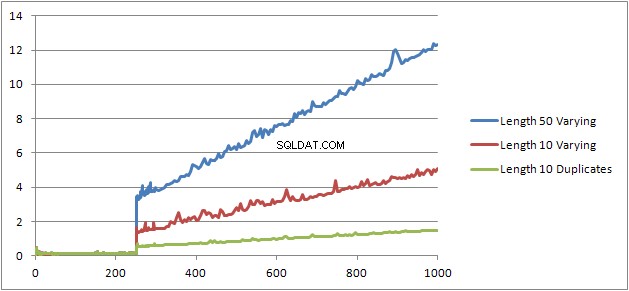
On voit clairement que plus les chaînes sont longues, plus les choses se détériorent et qu'à l'inverse, plus il y a de doublons, mieux les choses s'améliorent. Comme mentionné précédemment, les doublons n'affectent pas la taille du plan mis en cache, donc je suppose qu'il doit y avoir un processus d'identification des doublons lors de la construction de l'arbre d'expression algébrisé lui-même.
Modifier
Un endroit où ces informations sont exploitées est indiqué par @Lieven ici
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
Parce qu'au moment de la compilation, il peut déterminer que le Name la colonne n'a pas de doublons, elle ignore le classement par le 1/ (ID - ID) secondaire expression à l'exécution (le tri dans le plan n'a qu'un seul ORDER BY colonne) et aucune erreur de division par zéro n'est générée. Si des doublons sont ajoutés à la table, l'opérateur de tri affiche deux ordres par colonnes et l'erreur attendue est générée.