Si votre infrastructure informatique s'exécute sur AWS, vous avez probablement entendu parler d'Amazon Relational Database Service (RDS), un moyen simple de configurer, d'exploiter et de faire évoluer une base de données relationnelle dans le cloud. Il offre une capacité économique et redimensionnable tout en automatisant les tâches d'administration fastidieuses telles que le provisionnement du matériel, la configuration de la base de données, les correctifs et les sauvegardes. Il existe un certain nombre d'offres de moteurs de base de données pour RDS, telles que MySQL, MariaDB, PostgreSQL, Microsoft SQL Server et Oracle Server.
ClusterControl 1.7.3 agit de la même manière que RDS car il prend en charge le déploiement, la gestion, la surveillance et la mise à l'échelle des clusters de bases de données sur la plate-forme AWS. Il prend également en charge un certain nombre d'autres plates-formes cloud telles que Google Cloud Platform et Microsoft Azure. ClusterControl comprend la topologie de la base de données et est capable d'effectuer une récupération automatique, une gestion de la topologie et de nombreuses autres fonctionnalités avancées pour prendre le contrôle de votre base de données.
Dans cet article de blog, nous allons comparer les temps de basculement automatique pour Amazon Aurora, Amazon RDS pour MySQL et une configuration de réplication MySQL déployée et gérée par ClusterControl. Le type de basculement que nous allons faire est la promotion de l'esclave au cas où le maître tomberait en panne. C'est là que l'esclave le plus à jour prend le rôle de maître dans le cluster pour reprendre le service de base de données.
Notre test de basculement
Pour mesurer le temps de basculement, nous allons exécuter un simple test de connexion-mise à jour MySQL, avec une boucle pour compter l'état de l'instruction SQL qui se connecte à un point de terminaison de base de données unique. Le script ressemble à ceci :
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Le script Bash ci-dessus se connecte simplement à un hôte MySQL et effectue une mise à jour sur une seule ligne avec un délai d'attente de 1 seconde sur les commandes client Bash et mysql. Les paramètres liés aux délais d'attente sont requis afin que nous puissions mesurer correctement le temps d'arrêt en secondes, car le client mysql par défaut se reconnecte toujours jusqu'à ce qu'il atteigne le délai d'attente MySQL. Nous avons au préalable rempli un jeu de données de test avec la commande suivante :
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareLe script indique si la requête ci-dessus a réussi (OK) ou échoué (Fail). Des exemples de sorties sont présentés plus bas.
Basculement avec Amazon RDS pour MySQL
Dans notre test, nous utilisons l'offre RDS la plus basse avec les spécifications suivantes :
- Version MySQL : 5.7.22
- processeur virtuel :4
- RAM :16 Go
- Type de stockage :IOPS provisionnés (SSD)
- IOPS :1 000
- Espace de stockage :100 Gib
- Réplication multi-AZ :oui
Une fois qu'Amazon RDS a provisionné votre instance de base de données, vous pouvez utiliser n'importe quelle application ou utilitaire client MySQL standard pour vous connecter à l'instance. Dans la chaîne de connexion, vous spécifiez l'adresse DNS du point de terminaison de l'instance de base de données en tant que paramètre d'hôte et spécifiez le numéro de port du point de terminaison de l'instance de base de données en tant que paramètre de port.
Selon la page de documentation d'Amazon RDS, en cas d'indisponibilité planifiée ou non de votre instance de base de données, Amazon RDS bascule automatiquement vers un réplica de secours dans une autre zone de disponibilité si vous avez activé Multi-AZ. Le temps nécessaire au basculement dépend de l'activité de la base de données et d'autres conditions au moment où l'instance de base de données principale est devenue indisponible. Les temps de basculement sont généralement de 60 à 120 secondes.
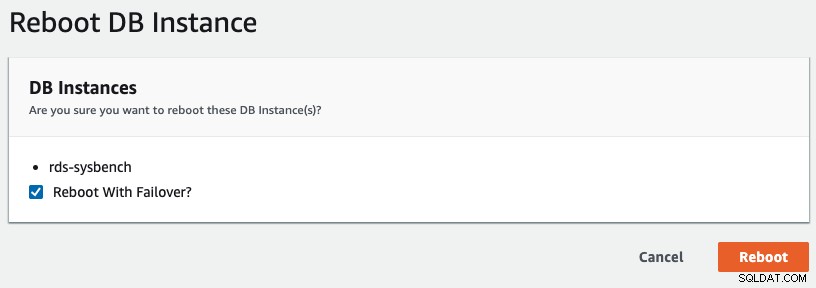
Pour lancer un basculement multi-AZ dans RDS, nous avons effectué une opération de redémarrage avec "Redémarrer avec basculement" coché, comme illustré dans la capture d'écran suivante :
Voici ce qui est observé par notre application :
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...Le temps d'arrêt de MySQL, vu du côté de l'application, a commencé de 03:41:09 à 03:41:36, soit environ 27 secondes au total. D'après les événements RDS, nous pouvons voir que le basculement multi-AZ ne s'est produit que 15 secondes après l'arrêt réel :
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Une fois la nouvelle instance de base de données redémarrée vers 03:41:33, le service MySQL était alors accessible environ 3 secondes plus tard.
Basculement avec Amazon Aurora pour MySQL
Amazon Aurora peut être considéré comme une version supérieure de RDS, avec de nombreuses fonctionnalités notables telles qu'une réplication plus rapide avec un stockage partagé, aucune perte de données lors du basculement et jusqu'à 64 To de limite de stockage. Amazon Aurora pour MySQL est basé sur l'édition MySQL open source, mais n'est pas open source en soi; il s'agit d'une base de données propriétaire à source fermée. Cela fonctionne de la même manière avec la réplication MySQL (un et un seul maître, avec plusieurs esclaves) et le basculement est automatiquement géré par Amazon Aurora.
Selon la FAQ d'Amazon Aurora, si vous avez un réplica Amazon Aurora, dans la même zone de disponibilité ou dans une zone de disponibilité différente, lors du basculement, Aurora retourne l'enregistrement de nom canonique (CNAME) pour que votre instance de base de données pointe vers le réplica sain, qui est en tour est promu pour devenir le nouveau primaire. Du début à la fin, le basculement s'effectue généralement en 30 secondes.
Si vous n'avez pas de réplica Amazon Aurora (c'est-à-dire une instance unique), Aurora tentera d'abord de créer une nouvelle instance de base de données dans la même zone de disponibilité que l'instance d'origine. Si cela n'est pas possible, Aurora tentera de créer une nouvelle instance de base de données dans une autre zone de disponibilité. Du début à la fin, le basculement s'effectue généralement en moins de 15 minutes.
Votre application doit réessayer les connexions à la base de données en cas de perte de connexion.
Une fois qu'Amazon Aurora a provisionné votre instance de base de données, vous obtiendrez deux points de terminaison, l'un pour l'écrivain et l'autre pour le lecteur. Le point de terminaison du lecteur fournit une prise en charge de l'équilibrage de charge pour les connexions en lecture seule au cluster de base de données. Les points de terminaison suivants sont extraits de notre configuration de test :
- rédacteur - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- lecteur - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
Lors de notre test, nous avons utilisé les spécifications Aurora suivantes :
- Type d'instance :db.r5.large
- Version MySQL :5.7.12
- processeur virtuel :2
- RAM :16 Go
- Réplication multi-AZ :oui
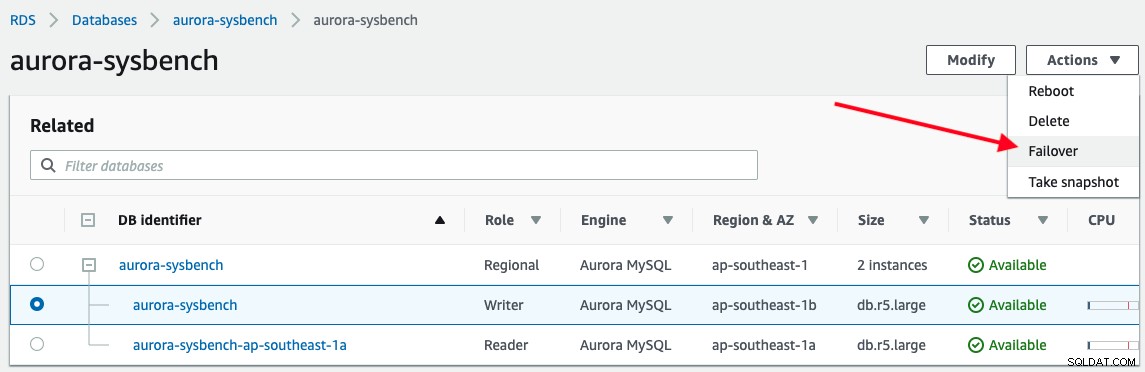
Pour déclencher un basculement, sélectionnez simplement l'instance du rédacteur -> Actions -> Basculement, comme illustré dans la capture d'écran suivante :
La sortie suivante est signalée par notre application lors de la connexion au point de terminaison du rédacteur Aurora :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...Le temps d'arrêt de la base de données a commencé à 12:35:49 jusqu'à 12:35:56 avec un total de 7 secondes. C'est assez impressionnant.
En regardant l'événement de base de données de la console de gestion Aurora, seuls ces deux événements se sont produits :
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedIl ne faut pas beaucoup de temps à Aurora pour promouvoir un esclave pour devenir un maître et rétrograder le maître pour devenir un esclave. Notez que toutes les répliques Aurora partagent le même volume sous-jacent avec l'instance principale, ce qui signifie que la réplication peut être effectuée en quelques millisecondes car les mises à jour effectuées par l'instance principale sont instantanément disponibles pour toutes les répliques Aurora. Par conséquent, il a un décalage de réplication minimal (Amazon prétend être de 100 millisecondes et moins). Cela réduira considérablement le temps de vérification de l'état et améliorera considérablement le temps de récupération.
Basculement avec ClusterControl
Dans cet exemple, nous imitons une configuration similaire avec Amazon RDS à l'aide d'instances m5.xlarge, avec un ProxySQL entre les deux pour automatiser le basculement depuis l'application à l'aide d'un seul accès au point de terminaison, tout comme RDS. Le schéma suivant illustre notre architecture :
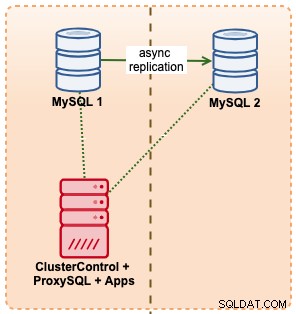
Puisque nous avons un accès direct aux instances de base de données, nous déclencherions un basculement automatique en tuant simplement le processus MySQL sur le maître actif :
$ kill -9 $(pidof mysqld)La commande ci-dessus a déclenché une récupération automatique dans ClusterControl :
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Alors que de notre point de vue de l'application de test, le temps d'arrêt s'est produit au moment suivant lors de la connexion au port hôte ProxySQL 6033 :
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...En examinant à la fois les événements de la tâche de récupération et la sortie de notre application, le nœud de la base de données MySQL était en panne 4 secondes avant le démarrage de la tâche de récupération du cluster, de 11 h 08 min 28 s à 11 h 08 min 39 s, avec un temps d'arrêt total de MySQL de 11 secondes. . L'une des choses les plus impressionnantes à propos de ClusterControl est que vous pouvez suivre la progression de la récupération sur les actions entreprises et exécutées par ClusterControl pendant le basculement. Il offre un niveau de transparence que vous ne pourrez obtenir avec aucune des offres de base de données des fournisseurs de cloud.
Pour la réplication MySQL/MariaDB/PostgreSQL, ClusterControl vous permet d'avoir une analyse plus fine de vos bases de données avec le support de la configuration et des paramètres avancés suivants :
- Gestion de la topologie de réplication maître-maître
- Gestion de la topologie de réplication en chaîne
- Visionneuse de topologie
- Liste blanche/noire des esclaves à promouvoir en tant que maître
- Vérificateur de transactions errantes
- Hook d'événements pré/post, succès/échec, basculement/basculement avec script externe
- Reconstruction automatique de l'esclave en cas d'erreur
- Étendre l'esclave à partir d'une sauvegarde existante
Résumé du temps de basculement
En termes de temps de basculement, Amazon RDS Aurora pour MySQL est le grand gagnant avec 7 secondes , suivi de ClusterControl 11 secondes et Amazon RDS pour MySQL avec 27 secondes .
Notez qu'il ne s'agit que d'un test simple, avec un client et une transaction par seconde pour mesurer le temps de récupération le plus rapide. Les transactions volumineuses ou un long processus de récupération peuvent augmenter le temps de basculement, par exemple, les transactions de longue durée peuvent prendre beaucoup de temps à revenir en arrière lors de l'arrêt de MySQL.