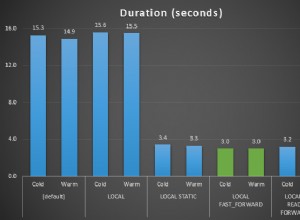
Vous pouvez voir ceci fonctionner sur SQL Fiddle :https://sqlfiddle.com/#!3/ 8c3ee/32
En voici l'essentiel :
with parsed as (
select
commasepa,
root.value('(/root/s/col[@name="X"])[1]', 'varchar(20)') as X,
root.value('(/root/s/col[@name="Y"])[1]', 'varchar(20)') as Y,
root.value('(/root/s/col[@name="Z"])[1]', 'varchar(20)') as Z,
root.value('(/root/s/col[@name="A"])[1]', 'varchar(20)') as A,
root.value('(/root/s/col[@name="B"])[1]', 'varchar(20)') as B,
root.value('(/root/s/col[@name="C"])[1]', 'varchar(20)') as C,
root.value('(/root/s/col[@name="D"])[1]', 'varchar(20)') as D
FROM
(
select
commasepa,
CONVERT(xml,'<root><s><col name="' + REPLACE(REPLACE(COMMASEPA, '=', '">'),',','</col></s><s><col name="') + '</col></s></root>') as root
FROM
samp
) xml
)
update
samp
set
samp.x = parsed.x,
samp.y = parsed.y,
samp.z = parsed.z,
samp.a = parsed.a,
samp.b = parsed.b,
samp.c = parsed.c,
samp.d = parsed.d
from
parsed
where
parsed.commasepa = samp.commasepa;
Divulgation complète - je suis l'auteur de sqlfiddle.com
Cela fonctionne en convertissant d'abord chaque chaîne commasepa en un objet XML qui ressemble à ceci :
<root>
<s>
<col name="X">1</col>
</s>
<s>
<col name="Y">2</col>
</s>
....
</root>
Une fois que j'ai la chaîne dans ce format, j'utilise ensuite les options xquery prises en charge par SQL Server 2005 (et versions ultérieures), à savoir .value('(/root/s/col[@name="X"])[1]', 'varchar(20)') partie. Je sélectionne chacune des colonnes potentielles individuellement, afin qu'elles soient normalisées et remplies lorsqu'elles sont disponibles. Avec ce format normalisé, je définis le jeu de résultats avec une expression de table commune (CTE) que j'ai appelée 'parsed'. Ce CTE est ensuite réintégré dans l'instruction de mise à jour, afin que les valeurs puissent être renseignées dans la table d'origine.