L'optimiseur SQL Server contient une logique pour supprimer les jointures redondantes, mais il existe des restrictions et les jointures doivent être prouvablement redondant . Pour résumer, une jointure peut avoir quatre effets :
- Il peut ajouter des colonnes supplémentaires (à partir du tableau joint)
- Il peut ajouter des lignes supplémentaires (le tableau joint peut correspondre plus d'une fois à une ligne source)
- Il peut supprimer des lignes (le tableau joint peut ne pas avoir de correspondance)
- Il peut introduire
NULLs (pour unRIGHTouFULL JOIN)
Pour supprimer avec succès une jointure redondante, la requête (ou la vue) doit prendre en compte les quatre possibilités. Lorsque cela est fait, correctement, l'effet peut être étonnant. Par exemple :
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
L'optimiseur peut réussir à simplifier la requête suivante :
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
À :

Rob Farley a écrit sur ces idées en profondeur dans le livre original MVP Deep Dives , et il y a un enregistrement de sa présentation sur le sujet chez SQLBits.
Les principales restrictions sont que les relations de clé étrangère doit être basé sur une seule clé pour contribuer au processus de simplification, et le temps de compilation des requêtes par rapport à une telle vue peut devenir assez long, en particulier lorsque le nombre de jointures augmente. Il pourrait être assez difficile d'écrire une vue de 100 tables qui obtienne toute la sémantique exactement correcte. Je serais enclin à trouver une solution alternative, peut-être en utilisant SQL dynamique .
Cela dit, les qualités particulières de votre table dénormalisée peuvent signifier que la vue est assez simple à assembler, ne nécessitant que des FOREIGN KEYs appliquées. non NULL colonnes référencées capables, et UNIQUE approprié contraintes pour que cette solution fonctionne comme vous l'espérez, sans la surcharge de 100 opérateurs de jointure physique dans le plan.
Exemple
Utiliser dix tables plutôt que cent :
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
La définition de la table parent (avec compression de page) :
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
La vue :
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Piratez les statistiques pour faire croire à l'optimiseur que le tableau est très volumineux :
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Exemple de requête utilisateur :
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Donne-nous ce plan d'exécution :
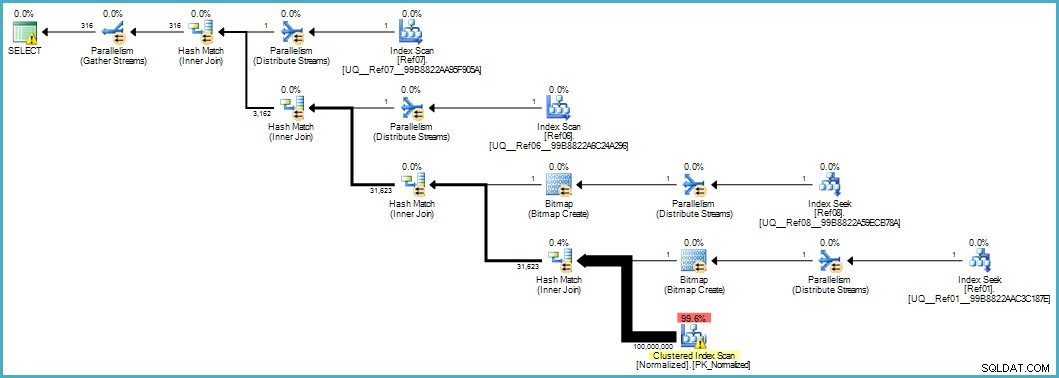
L'analyse de la table Normalized semble mauvaise, mais les deux bitmaps de filtre Bloom sont appliqués lors de l'analyse par le moteur de stockage (ainsi, les lignes qui ne peuvent pas correspondre n'apparaissent même pas jusqu'au processeur de requêtes). Cela peut être suffisant pour donner des performances acceptables dans votre cas, et certainement mieux que d'analyser la table d'origine avec ses colonnes débordantes.
Si vous êtes en mesure de mettre à niveau vers SQL Server 2012 Enterprise à un moment donné, vous avez une autre option :créer un index de magasin de colonnes sur la table normalisée :
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Le plan d'exécution est :
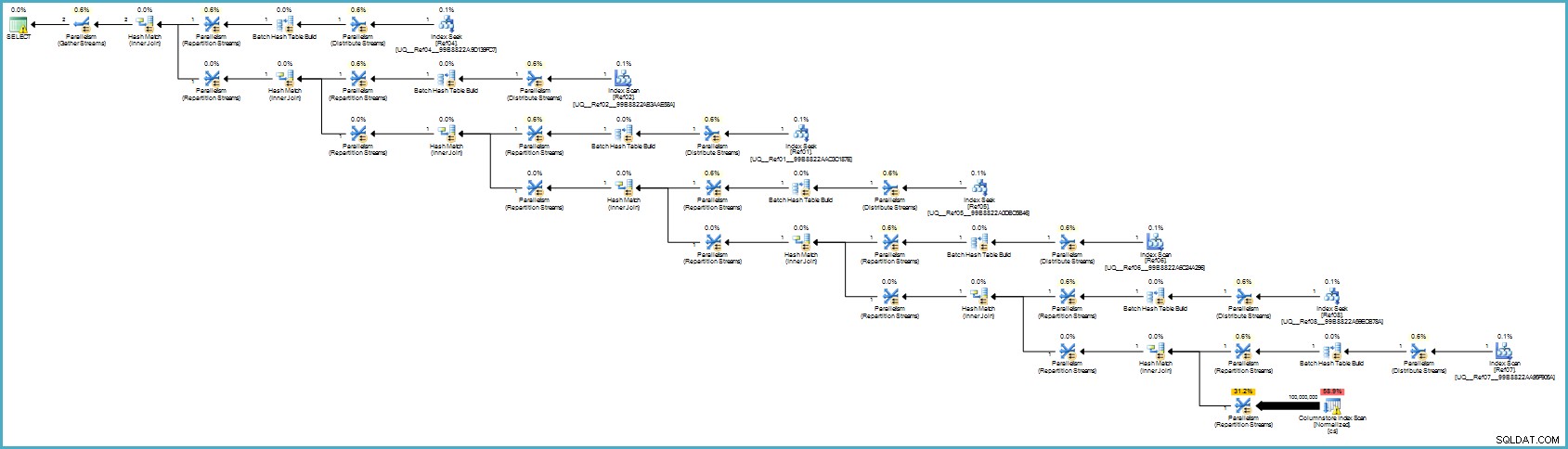
Cela vous semble probablement pire, mais le stockage des colonnes offre une compression exceptionnelle et l'ensemble du plan d'exécution s'exécute en mode batch avec des filtres pour toutes les colonnes contributives. Si le serveur dispose de suffisamment de threads et de mémoire disponible, cette alternative pourrait vraiment fonctionner.
En fin de compte, je ne suis pas sûr que cette normalisation soit la bonne approche compte tenu du nombre de tables et des risques d'obtenir un mauvais plan d'exécution ou de nécessiter un temps de compilation excessif. Je corrigerais probablement d'abord le schéma de la table dénormalisée (types de données appropriés, etc.), appliquerais éventuellement la compression des données... les choses habituelles.
Si les données appartiennent vraiment à un schéma en étoile, cela nécessite probablement plus de travail de conception que de simplement séparer les éléments de données répétitifs dans des tables séparées.