Démonstration d'une explication possible.
Créer un script de tableau
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
Requête 1 (Renvoie 35 résultats)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Requête 2 (comme avant, mais l'ajout de c2.[type] à la liste de sélection renvoie 0 résultat);
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Pourquoi ?
row_number() pour les noms en double n'est pas spécifié, il choisit donc celui qui correspond au meilleur plan d'exécution pour les colonnes de sortie requises. Dans la deuxième requête, c'est la même chose pour les deux invocations cte, dans la première, il choisit un chemin d'accès différent avec une numérotation de ligne différente résultante.
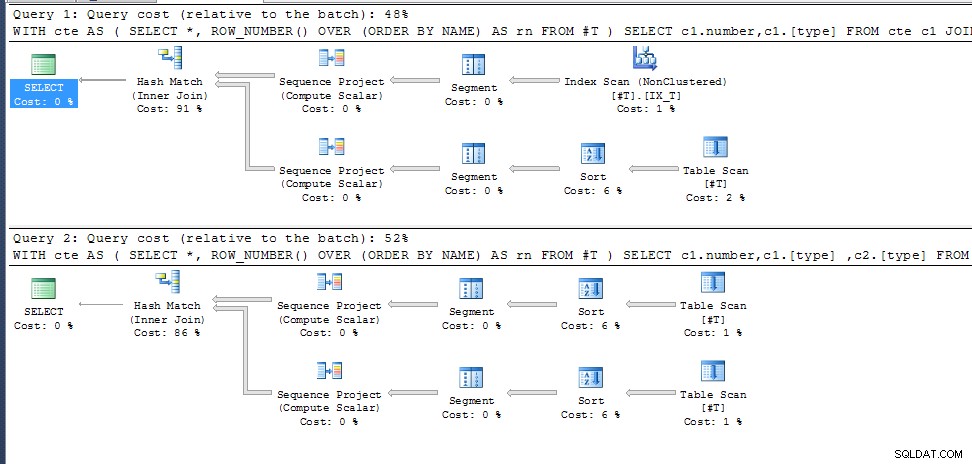
Solution suggérée
Vous rejoignez vous-même le CTE le ROW_NUMBER() over (order by t.[Date])
Contrairement à ce à quoi on aurait pu s'attendre, le CTE sera probablement ne pas être matérialisé
ce qui aurait assuré la cohérence de l'auto-jointure et donc vous supposez une corrélation entre ROW_NUMBER() des deux côtés qui peuvent très bien ne pas exister pour les enregistrements où un doublon [Date] existe dans les données.
Et si vous essayez ROW_NUMBER() over (order by t.[Date], t.[id]) pour s'assurer qu'en cas de dates liées, la numérotation des lignes est dans un ordre cohérent garanti. (Ou une autre colonne/combinaison de colonnes qui peut différencier les enregistrements si l'identifiant ne le fait pas)