Entièrement d'accord avec @PaulStock qu'il vaut mieux laisser les agrégats aux systèmes sources. Un agrégat dans SSIS est un composant entièrement bloquant un peu comme un tri et j'ai a déjà fait mon argumentation sur ce point .
Mais il y a des moments où ces opérations dans le système source ne fonctionneront tout simplement pas. Le mieux que j'ai pu trouver est de doubler le traitement des données. Oui, ick mais je n'ai jamais été capable de trouver un moyen de faire passer une colonne sans être affectée. Pour les scénarios Min/Max, je voudrais que cela soit une option, mais évidemment quelque chose comme une somme rendrait difficile pour le composant de savoir à quelle ligne "source" il serait lié.
2005
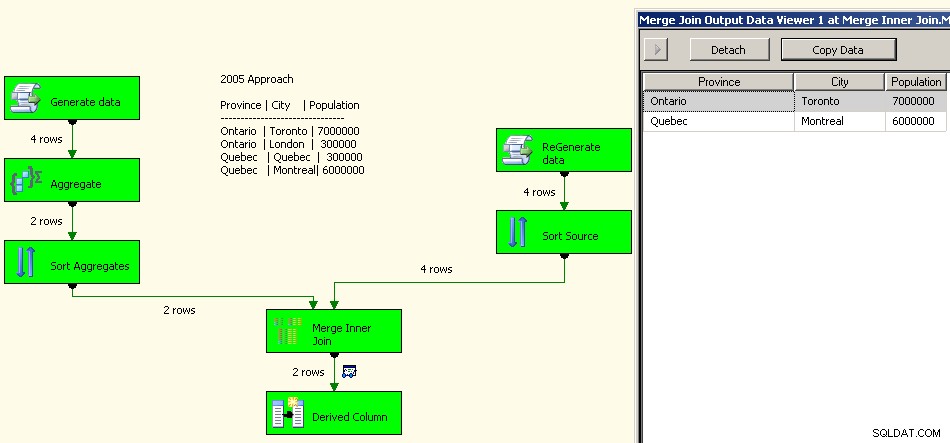
Une implémentation de 2005 ressemblerait à ceci. Vos performances ne seront pas bonnes, en fait à quelques ordres de grandeur de bonnes car vous aurez toutes ces transformations bloquantes en plus de devoir retraiter vos données source.
Fusionner rejoindre 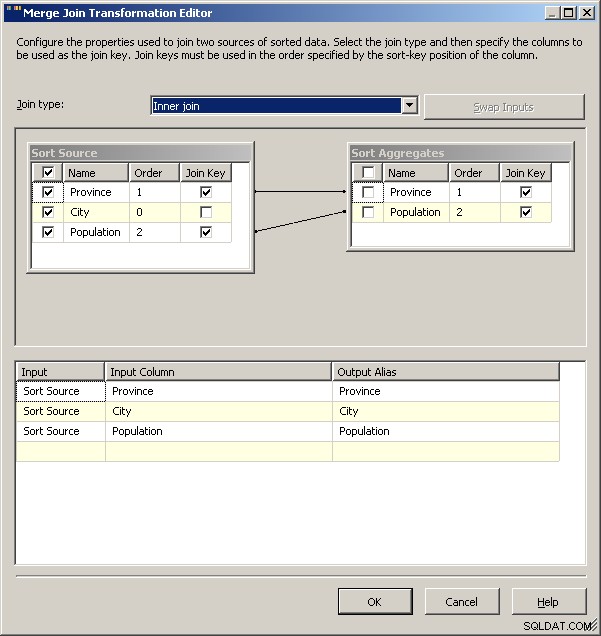
2008
En 2008, vous avez la possibilité d'utiliser le Cache Connection Manager ce qui aiderait à éliminer les transformations bloquantes, du moins là où cela compte, mais vous devrez toujours payer le coût du double traitement de vos données source.
Faites glisser deux flux de données sur le canevas. Le premier remplira le gestionnaire de connexions de cache et devrait être l'endroit où l'agrégat a lieu.
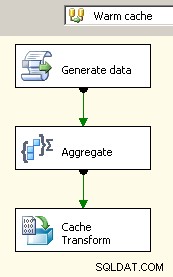
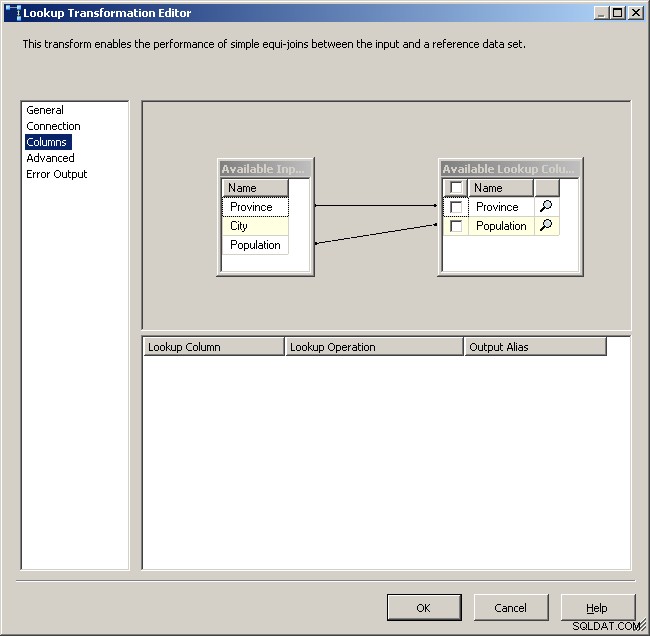
Maintenant que le cache contient les données agrégées, déposez une tâche de recherche dans votre flux de données principal et effectuez une recherche dans le cache.
Onglet de recherche générale
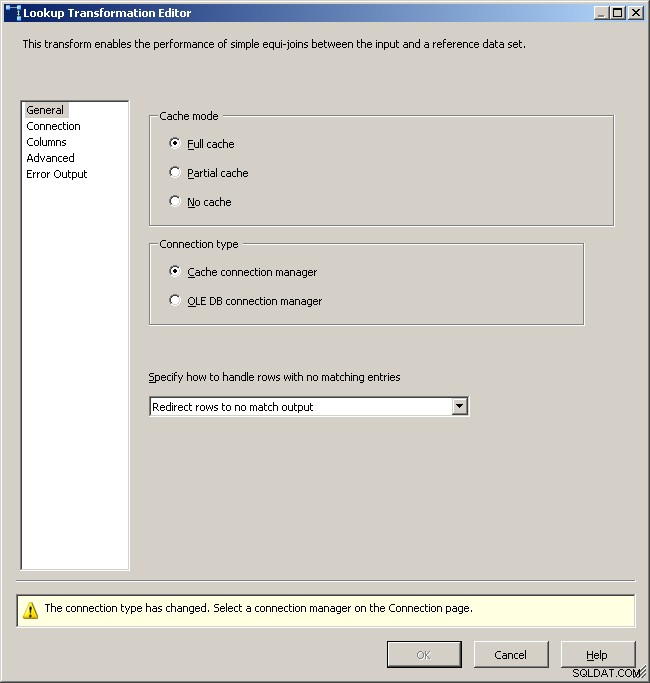
Sélectionnez le gestionnaire de connexion au cache
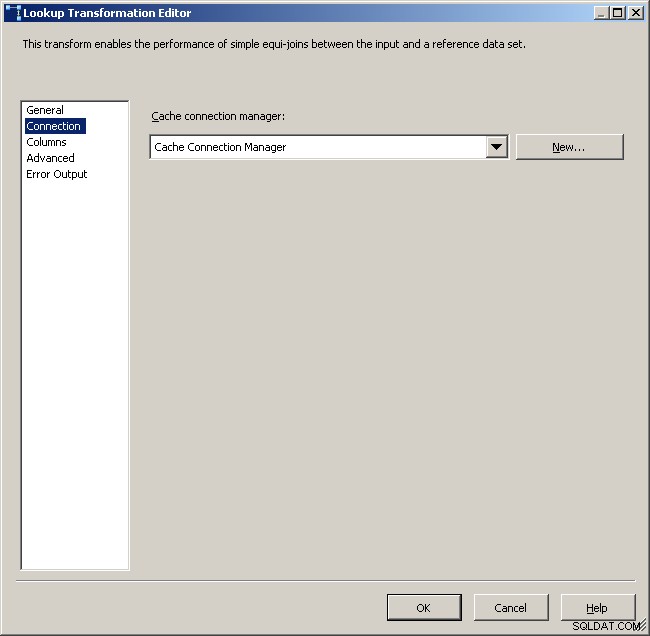
Mappez les colonnes appropriées
Grand succès 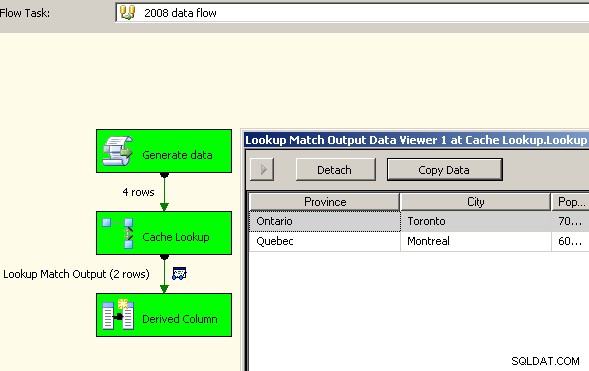
Tâche de script
La troisième approche à laquelle je peux penser, 2005 ou 2008, est de l'écrire soi-même. En règle générale, j'essaie d'éviter les tâches de script mais c'est un cas où cela a probablement du sens. Vous devrez en faire un transformation de script asynchrone mais gérez simplement vos agrégations là-dedans. Plus de code à maintenir, mais vous pouvez vous épargner la peine de retraiter vos données sources.
Enfin, en tant que mise en garde générale, j'étudierais l'impact des liens sur votre solution. Pour cet ensemble de données, je m'attendrais à ce que quelque chose comme Guelph grossisse soudainement et lie Toronto, mais si c'était le cas, que devrait faire le package ? À l'heure actuelle, les deux entraîneront 2 rangées pour l'Ontario, mais est-ce le comportement prévu ? Le script, bien sûr, vous permet de définir ce qui se passe en cas d'égalité. Vous pourriez probablement mettre la solution 2008 à l'envers en mettant en cache les données "normales" et en les utilisant comme condition de recherche et en utilisant les agrégats pour retirer un seul des liens. 2005 peut probablement faire la même chose simplement en mettant l'agrégat comme source gauche pour la jointure de fusion
Modifications
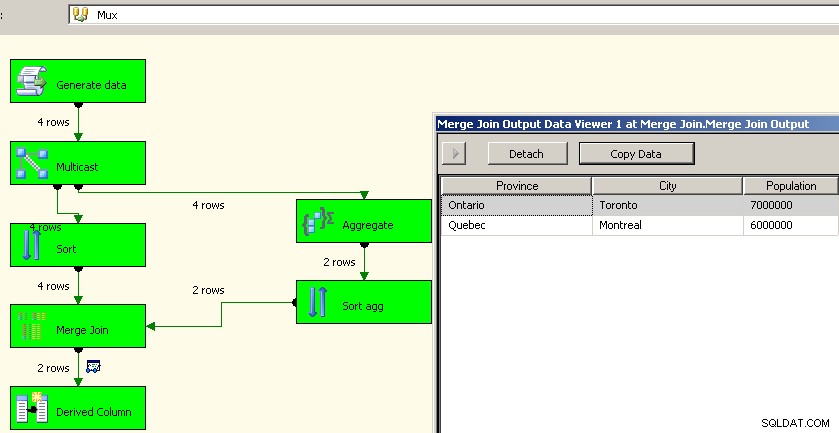
Jason Horner a eu une bonne idée dans son commentaire. Une approche différente consisterait à utiliser une transformation multidiffusion et à effectuer l'agrégation dans un flux et à le rassembler. Je n'arrivais pas à comprendre comment le faire fonctionner avec une union, mais nous pourrions utiliser des tris et des fusions comme ci-dessus. C'est probablement une meilleure approche car cela nous évite d'avoir à retraiter les données sources.