Dans la partie précédente de cet article, nous avons expliqué comment importer des fichiers CSV dans SQL Server à l'aide de l'instruction BULK INSERT. Nous avons discuté de la méthodologie principale du processus d'insertion en masse ainsi que des détails des options BATCHSIZE et MAXERRORS dans les scénarios. Dans cette partie, nous allons passer en revue d'autres options (FIRE_TRIGGERS, CHECK_CONSTRAINTS et TABLOCK) du processus d'insertion en masse dans divers scénarios.
Scénario 1 :Pouvons-nous activer les déclencheurs dans la table de destination pendant l'opération d'insertion en bloc ?
Par défaut, lors du processus d'insertion en bloc, les déclencheurs d'insertion spécifiés dans la table cible ne sont pas déclenchés, cependant, dans certaines situations, nous pouvons souhaiter activer ces déclencheurs. Une solution à ce problème consiste à utiliser l'option FIRE_TRIGGERS dans les instructions d'insertion en bloc. Je souhaite ajouter un avis indiquant que cette option peut affecter et diminuer les performances de l'opération d'insertion en bloc car le déclencheur/les déclencheurs peuvent effectuer des opérations distinctes dans la base de données. Dans l'exemple suivant, nous allons le démontrer. Au début, nous ne définirons pas le paramètre FIRE_TRIGGERS et le processus d'insertion en masse ne déclenchera pas le déclencheur d'insertion. Dans le script T-SQL suivant, nous allons définir un déclencheur d'insertion pour la table Sales.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [ SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float) DROP TABLE IF EXISTS SalesLogCREATE TABLE SalesLog (OrderIDLog bigint)GOCREATE TRIGGER OrderLogIns ON SalesFOR INSERTASBEGIN SET NOCOUNT ON INSERT INTO SalesLogSELECT OrderId from insertendGOBULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n' ); SELECT Count(*) FROM SalesLog
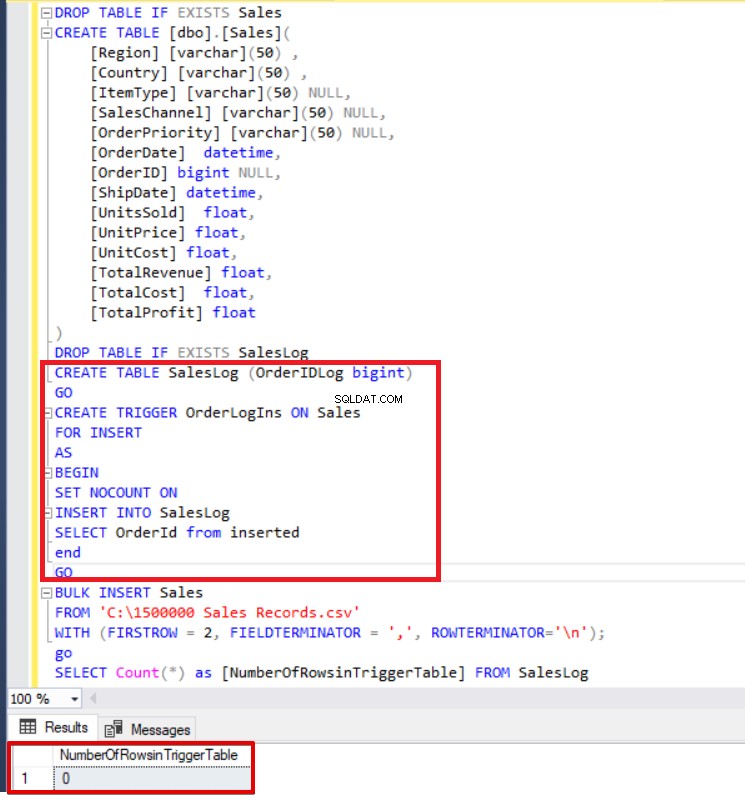
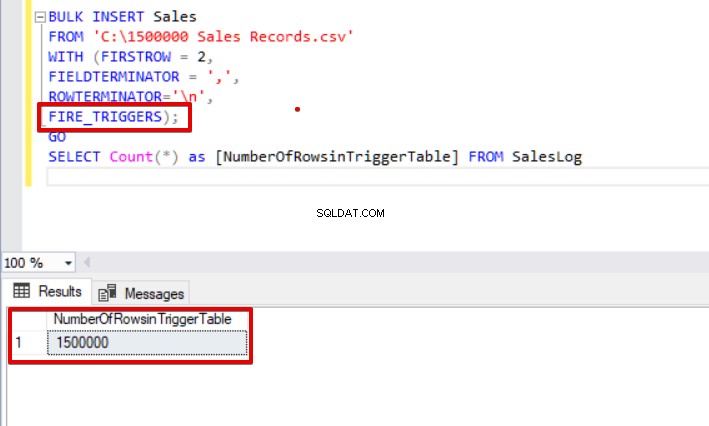
Comme vous pouvez le voir ci-dessus, le déclencheur d'insertion ne s'est pas déclenché car nous n'avons pas défini l'option FIRE_TRIGGERS. Maintenant, nous allons ajouter l'option FIRE_TRIGGERS à l'instruction d'insertion en bloc afin que cette option permette d'insérer un déclencheur d'incendie.
BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n',FIRE_TRIGGERS);GOSELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog
Scénario 2 :Comment activer une contrainte de vérification lors de l'opération d'insertion en masse ?
Les contraintes de vérification nous permettent d'appliquer l'intégrité des données dans les tables SQL Server. Le but de la contrainte est de vérifier les valeurs insérées, mises à jour ou supprimées en fonction de leur régulation syntaxique. Par exemple, la contrainte NOT NULL prévoit qu'une colonne spécifiée ne peut pas être modifiée par la valeur NULL. Maintenant, nous allons nous concentrer sur les contraintes et l'interaction d'insertion en bloc. Par défaut, lors du processus d'insertion en masse, toutes les contraintes de vérification et de clé étrangère sont ignorées, mais cette option comporte quelques exceptions. Selon la documentation Microsoft " les contraintes UNIQUE et PRIMARY KEY sont toujours appliquées. Lors de l'importation dans une colonne de caractères pour laquelle la contrainte NOT NULL est définie, BULK INSERT insère une chaîne vide lorsqu'il n'y a pas de valeur dans le fichier texte." Dans le script T-SQL suivant, nous allons ajouter une contrainte de vérification à la colonne OrderDate qui contrôle la date de commande supérieure au 01.01.2016.
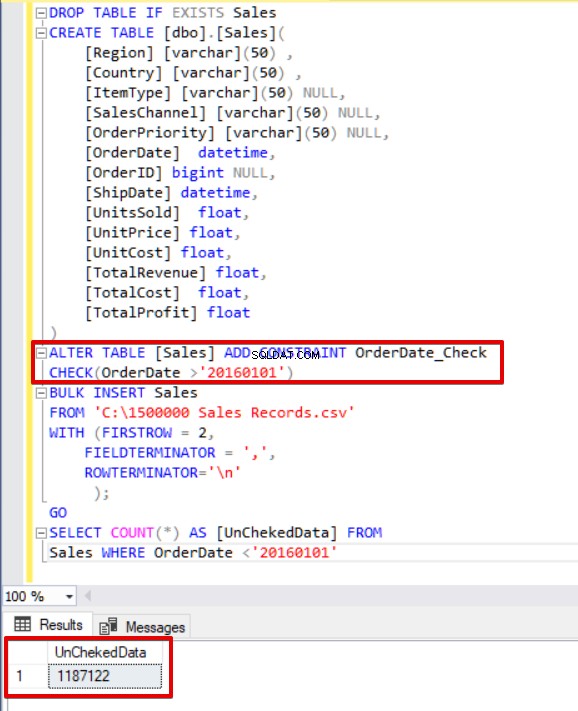
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [ SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float) ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_CheckCHECK(OrderDate>'20160101')BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2 , FIELDTERMINATOR =',', ROWTERMINATOR='\n' );GOSELECT COUNT(*) AS [UnChekedData] FROM Sales WHERE OrderDate <'20160101'
Comme vous pouvez le voir dans l'exemple ci-dessus, le processus d'insertion en masse ignore le contrôle de contrainte de vérification. Cependant, SQL Server indique que la contrainte de vérification n'est pas approuvée.
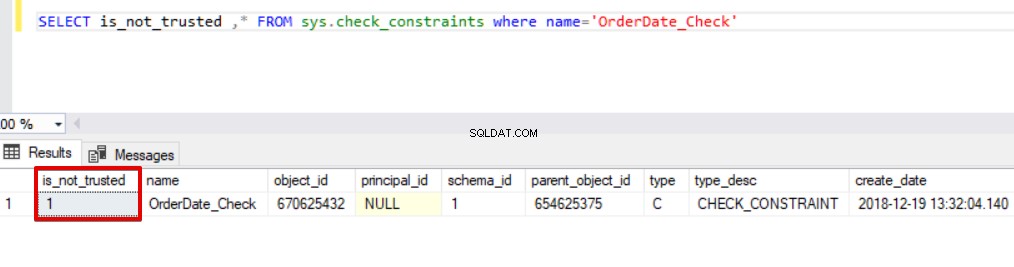
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'
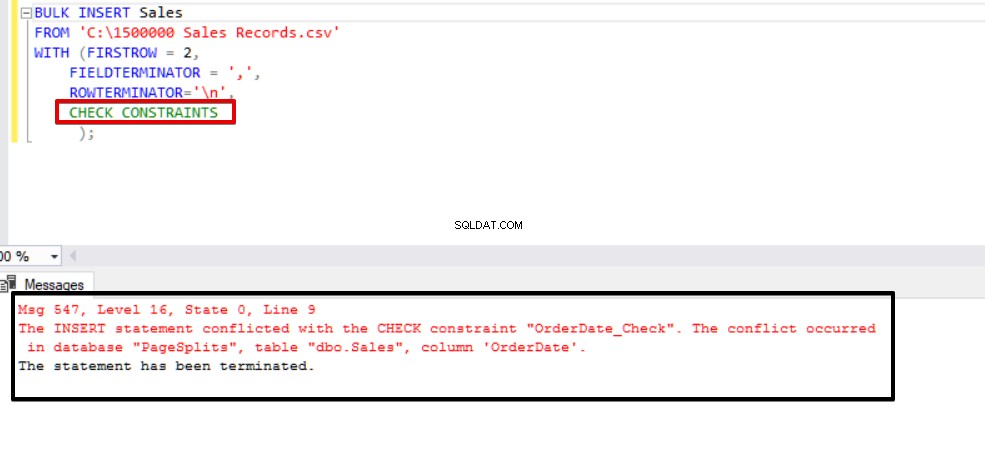
Cette valeur indique que quelqu'un a inséré ou mis à jour des données dans cette colonne en sautant la contrainte de vérification, en même temps cette colonne peut contenir des données incohérentes en référence à cette contrainte. Maintenant, nous allons essayer d'exécuter l'instruction d'insertion en bloc avec l'option CHECK_CONSTRAINTS. Le résultat est très simple, la contrainte de vérification renvoie une erreur en raison de données incorrectes.
BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n' );
Scénario 3 :Comment augmenter les performances de plusieurs insertions groupées dans une table de destination ?
L'objectif principal du mécanisme de verrouillage dans SQL Server est de protéger et d'assurer l'intégrité des données. Dans l'article Concept principal du verrouillage SQL Server, vous pouvez trouver des détails sur le mécanisme de verrouillage. Maintenant, nous allons nous concentrer sur les détails de verrouillage du processus d'insertion en masse. Si vous exécutez l'instruction d'insertion en bloc sans l'option TABLELOCK, elle acquiert le verrou des lignes ou de la table en fonction de la hiérarchie des verrous. Cependant, dans certains cas, nous pouvons souhaiter exécuter plusieurs processus d'insertion en bloc sur une table de destination, afin de réduire le temps de fonctionnement de l'insertion en bloc. Dans un premier temps, nous exécuterons simultanément deux instructions d'insertion en masse et analyserons le comportement du mécanisme de verrouillage. Nous allons ouvrir deux fenêtres de requête dans SQL Server Management Studio et exécuter simultanément les instructions d'insertion en bloc suivantes.
BULK INSERT SalesFROM 'C:\1500000 Sales Records.csv'WITH (FIRSTROW =2, FIELDTERMINATOR =',', ROWTERMINATOR='\n' );
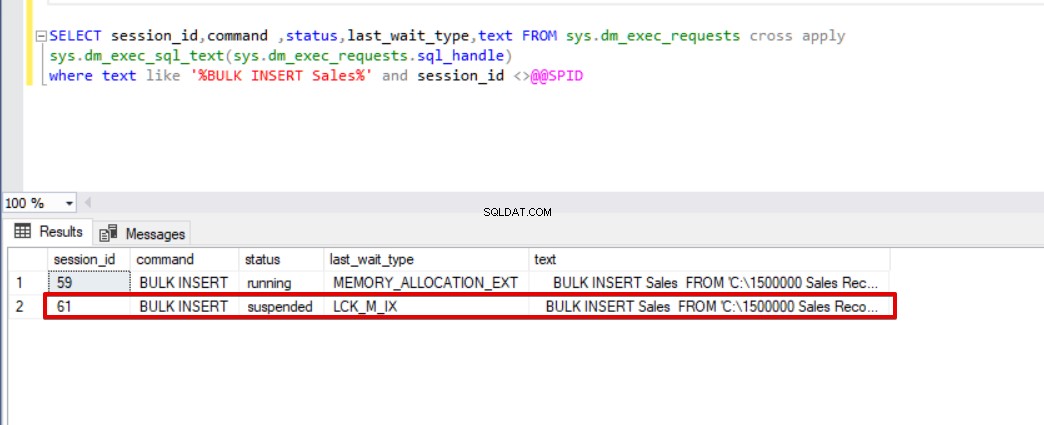
Lorsque nous exécutons la requête dmv (Dynamic Management View) suivante, qui permet de surveiller l'état du processus d'insertion en masse.
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)where text like '%BULK INSERT Sales%' and session_id <>@@SPID
Comme vous pouvez le voir dans l'image ci-dessus, session 61, l'état du processus d'insertion en bloc est suspendu en raison d'un verrouillage. Si nous vérifions le problème, la session 59 verrouille la table de destination de l'insertion en masse et la session 61 attend la libération de ce verrou pour continuer le processus d'insertion en masse. Maintenant, nous allons ajouter l'option TABLOCK aux instructions d'insertion en bloc et exécuter les requêtes.
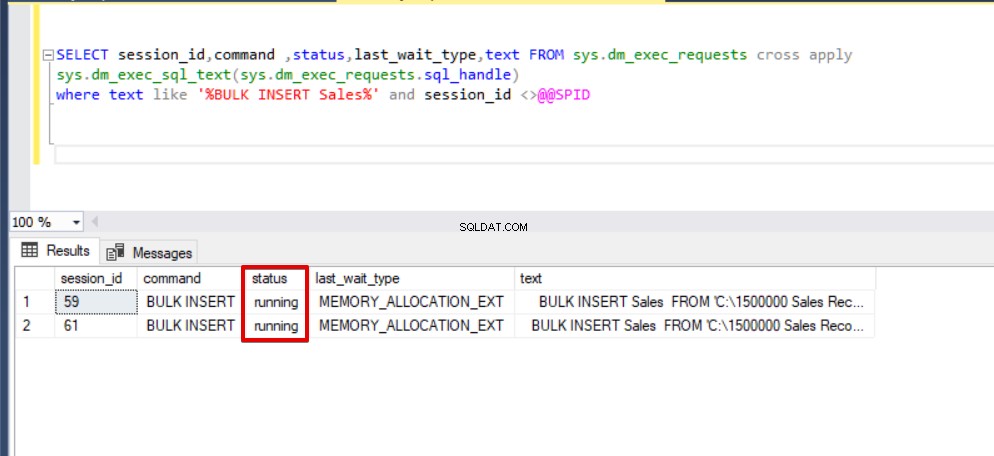
Lorsque nous exécutons à nouveau la requête de surveillance dmv, nous ne voyons aucun processus d'insertion en bloc suspendu, car SQL Server utilise un type de verrou spécial appelé verrou de mise à jour en bloc (BU). Ce type de verrou permet de traiter simultanément plusieurs opérations d'insertion en bloc sur la même table et cette option réduit également la durée totale du processus d'insertion en bloc.
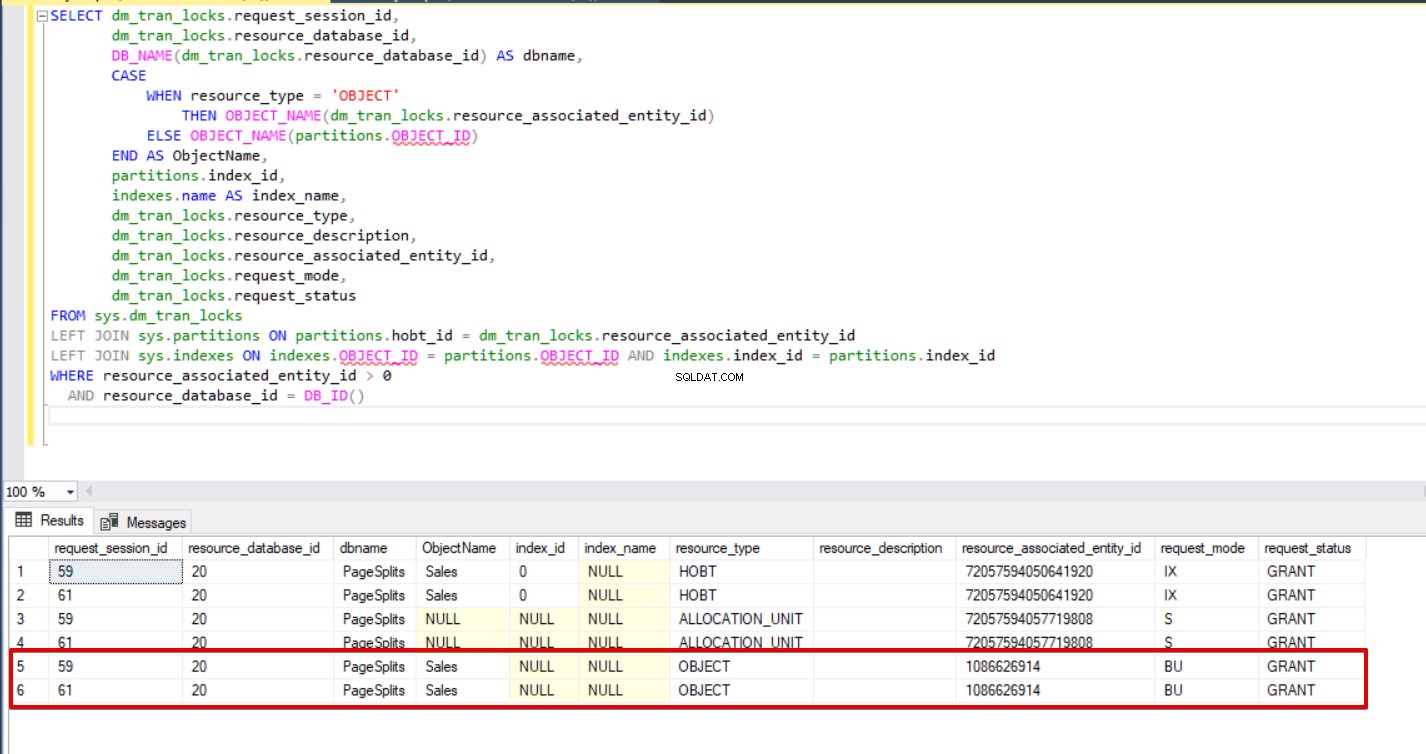
Lorsque nous exécutons la requête suivante pendant le processus d'insertion en masse, nous pouvons surveiller les détails de verrouillage et les types de verrouillage.
SELECT dm_tran_locks.request_session_id, dm_tran_locks.resource_database_id, DB_NAME(dm_tran_locks.resource_database_id) AS dbname, CASE WHEN resource_type ='OBJECT' THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id) ELSE OBJECT_NAME(partitions.OBJECT_id) END AS ObjectName, partitions. indexes.name AS index_name, dm_tran_locks.resource_type, dm_tran_locks.resource_description, dm_tran_locks.resource_associated_entity_id, dm_tran_locks.request_mode, dm_tran_locks.request_statusFROM sys.dm_tran_locksLEFT JOIN sys.partitions ON partitions.hobt_id =dm_tran_locks.resource_associated_entity_idLEFT JOIN sys.indexes ON indexes.OBJECT_ID =partitions .OBJECT_ID AND indexes.index_id =partitions.index_idWHERE resource_associated_entity_id> 0 AND resource_database_id =DB_ID()
Conclusion
Dans cet article, nous avons exploré tous les détails de l'opération d'insertion en bloc dans SQL Server. En particulier, nous avons mentionné la commande BULK INSERT et ses paramètres et options, et nous avons également analysé divers scénarios proches des problèmes de la vie réelle.
Références
INSERTION EN BULK (Transact-SQL)
Prérequis pour une journalisation minimale dans l'importation en masse
Contrôle du comportement de verrouillage pour l'importation en masse
Autres lectures
Exportation de données vers un fichier plat avec l'utilitaire BCP et importation de données avec insertion en bloc
Outil utile :
dbForge Data Pump - un complément SSMS pour remplir les bases de données SQL avec des données sources externes et migrer les données entre les systèmes.