Introduction
Rembobine sont spécifiques aux opérateurs du côté interne d'une jointure ou d'une application de boucles imbriquées. L'idée est de réutiliser les résultats précédemment calculés d'une partie d'un plan d'exécution lorsqu'il est sûr de le faire.
L'exemple canonique d'un opérateur de plan qui peut rembobiner est le paresseux Table Spool . Sa raison d'être consiste à mettre en cache les lignes de résultats d'un sous-arbre de plan, puis à rejouer ces lignes lors des itérations suivantes si des paramètres de boucle corrélés sont inchangés. La relecture des lignes peut être moins coûteuse que la réexécution du sous-arbre qui les a générées. Pour plus d'informations sur ces spools de performances voir mon article précédent.
La documentation indique que seuls les opérateurs suivants peuvent rembobiner :
- Bobine de table
- Bobine de comptage de lignes
- Spool d'index non clusterisé
- Fonction table
- Trier
- Requête à distance
- Affirmer et Filtrer opérateurs avec une expression de démarrage
Les trois premiers éléments sont le plus souvent des spools de performance, bien qu'ils puissent être introduits pour d'autres raisons (quand ils peuvent être aussi impatients que paresseux).
Fonctions table utilisez une variable de table, qui peut être utilisée pour mettre en cache et rejouer les résultats dans des circonstances appropriées. Si vous êtes intéressé par les rembobinages de fonctions de table, veuillez consulter mes questions et réponses sur Database Administrators Stack Exchange.
Avec ceux à l'écart, cet article est exclusivement sur les Sorts et quand ils peuvent rembobiner.
Trier les rembobinages
Les tris utilisent le stockage (mémoire et peut-être disque s'ils débordent) donc ils ont une installation capable de stocker des lignes entre les itérations de la boucle. En particulier, la sortie triée peut, en principe, être rejouée (rembobinée).
Pourtant, la réponse courte à la question du titre, "Do Sorts Rewind?" est :
Oui, mais vous ne le verrez pas très souvent.
Types de tri
Les tris existent en plusieurs types différents en interne, mais pour nos besoins actuels, il n'y en a que deux :
- Tri en mémoire (
CQScanInMemSortNew).- Toujours en mémoire ; ne peut pas renverser sur disque.
- Utilise le tri rapide de la bibliothèque standard.
- Maximum de 500 lignes et deux pages de 8 Ko au total.
- Toutes les entrées doivent être des constantes d'exécution. En règle générale, cela signifie que l'ensemble de la sous-arborescence de tri doit être composé de uniquement Analyse constante et/ou Compute Scalaire opérateurs.
- Se distingue explicitement dans les plans d'exécution uniquement lorsque showplan détaillé est activé (indicateur de trace 8666). Cela ajoute des propriétés supplémentaires au Trier opérateur, dont l'un est "InMemory=[0|1]".
- Tous les autres tris.
(Les deux types de Trier l'opérateur inclut son Top N Sort et Tri distinct variantes).
Comportements de rembobinage
-
Tris en mémoire peut toujours revenir en arrière quand c'est sûr. S'il n'y a pas de paramètres de boucle corrélés, ou si les valeurs des paramètres sont inchangées par rapport à l'itération immédiatement précédente, ce type de tri peut relire ses données stockées au lieu de réexécuter les opérateurs en dessous dans le plan d'exécution.
-
Tris non en mémoire peut rembobiner lorsqu'il est sûr, mais seulement si le Trier l'opérateur contient au plus une ligne . Veuillez noter un Trier input peut fournir une ligne sur certaines itérations, mais pas sur d'autres. Le comportement d'exécution peut donc être un mélange complexe de rembobinages et de reliures. Cela dépend entièrement du nombre de lignes fournies au Sort à chaque itération à l'exécution. Vous ne pouvez généralement pas prédire ce qu'est un tri fera à chaque itération en inspectant le plan d'exécution.
Le mot "sûr" dans les descriptions ci-dessus signifie :Soit un changement de paramètre n'a pas eu lieu, soit aucun opérateur sous le Sort avoir une dépendance de la valeur modifiée.
Remarque importante sur les plans d'exécution
Les plans d'exécution ne signalent pas toujours correctement les rembobinages (et les reliures) pour Trier les opérateurs. L'opérateur signalera un rembobinage si des paramètres corrélés sont inchangés, et un rebind dans le cas contraire.
Pour les tris non en mémoire (de loin les plus courants), un rembobinage signalé ne rejouera réellement les résultats du tri stockés que s'il y a au plus une ligne dans le tampon de sortie du tri. Sinon, le tri fera un rapport un rembobinage, mais le sous-arbre sera toujours entièrement ré-exécuté (une reliure).
Pour vérifier combien de rembobinages signalés étaient des rembobinages réels, vérifiez le Nombre d'exécutions propriété sur les opérateurs sous le Sort .
Histoire et mon explication
Le Trier Le comportement de rembobinage de l'opérateur peut sembler étrange, mais il en a été ainsi de (au moins) SQL Server 2000 à SQL Server 2019 inclus (ainsi qu'Azure SQL Database). Je n'ai trouvé aucune explication ou documentation officielle à ce sujet.
Mon point de vue personnel est que Trier les rembobinages sont assez coûteux en raison de la machinerie de tri sous-jacente, y compris les installations de déversement, et de l'utilisation des transactions système dans tempdb .
Dans la plupart des cas, l'optimiseur fera mieux d'introduire un spool de performance explicite lorsqu'il détecte la possibilité de doublons de paramètres de boucle corrélés. Les spools sont le moyen le moins coûteux de mettre en cache des résultats partiels.
C'est possible que la relecture d'un Tri le résultat serait seulement plus rentable qu'un Spool lorsque le Trier contient au plus une ligne. Après tout, le tri d'une ligne (ou d'aucune ligne !) n'implique en fait aucun tri, ce qui permet d'éviter une grande partie de la surcharge.
Pure spéculation, mais quelqu'un était obligé de demander, alors voilà.
Démo 1 :Rembobinages inexacts
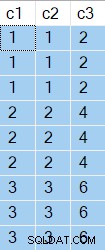
Ce premier exemple comporte deux variables de table. Le premier contient trois valeurs dupliquées trois fois dans la colonne c1 . Le deuxième tableau contient deux lignes pour chaque correspondance sur c2 = c1 . Les deux lignes correspondantes se distinguent par une valeur dans la colonne c3 .
La tâche consiste à renvoyer la ligne de la deuxième table avec le c3 le plus élevé valeur pour chaque correspondance sur c1 = c2 . Le code est probablement plus clair que mon explication :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
INSERT @T2
(c2, c3)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Le NO_PERFORMANCE_SPOOL indice est là pour empêcher l'optimiseur d'introduire un spool de performance. Cela peut se produire avec des variables de table lorsque, par ex. l'indicateur de trace 2453 est activé, ou la compilation différée de la variable de table est disponible, afin que l'optimiseur puisse voir la véritable cardinalité de la variable de table (mais pas la distribution des valeurs).
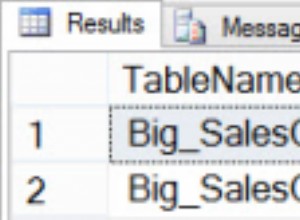
Les résultats de la requête affichent le c2 et c3 les valeurs renvoyées sont les mêmes pour chaque c1 distinct valeur :
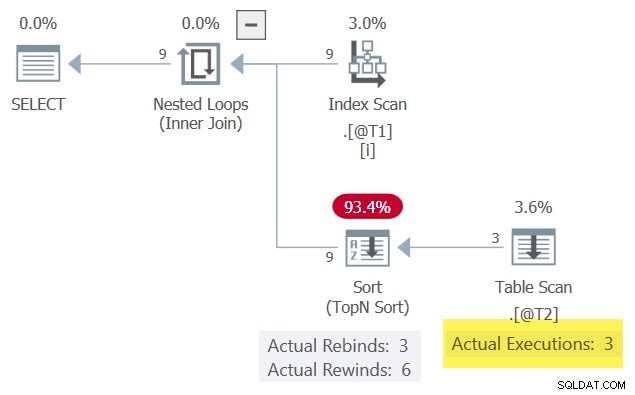
Le plan d'exécution réel de la requête est :
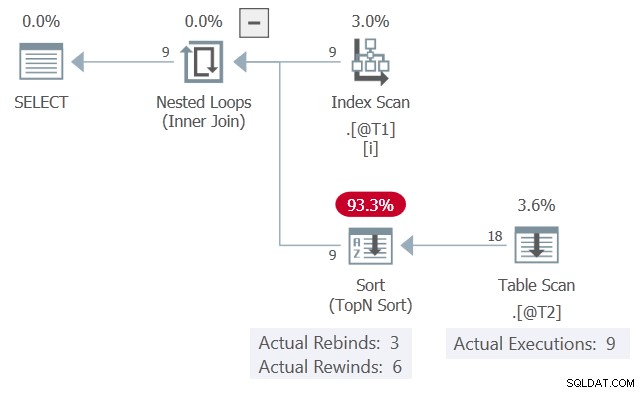
Le c1 les valeurs, présentées dans l'ordre, correspondent 6 fois à l'itération précédente et changent 3 fois. Le Trier rapporte cela comme 6 rembobinages et 3 reliures.
Si c'était vrai, le Table Scan ne s'exécuterait que 3 fois. Le Trier rejouait (rembobinait) ses résultats les 6 autres fois.
En l'état, nous pouvons voir le Table Scan a été exécuté 9 fois, une fois pour chaque ligne de la table @T1 . Aucun rembobinage ne s'est produit ici .
Démo 2 :Trier les rembobinages
L'exemple précédent n'autorisait pas le Trier pour rembobiner parce que (a) ce n'est pas un tri en mémoire; et (b) à chaque itération de la boucle, le Sort contenait deux rangées. Plan Explorer affiche un total de 18 lignes à partir de l'balayage de table , deux lignes sur chacune des 9 itérations.
Modifions l'exemple maintenant pour qu'il n'y en ait qu'un un ligne dans la table @T2 pour chaque ligne correspondante de @T1 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Only one matching row per iteration now
INSERT @T2
(c2, c3)
VALUES
--(1, 1),
(1, 2),
--(2, 3),
(2, 4),
--(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Les résultats sont les mêmes que ceux affichés précédemment car nous avons conservé la ligne correspondante triée en premier sur la colonne c3 . Le plan d'exécution est également superficiellement similaire, mais avec une différence importante :
Avec une ligne dans le Trier à tout moment, il est capable de rembobiner lorsque le paramètre corrélé c1 ne change pas. Le balayage de table n'est exécuté que 3 fois en conséquence.
Remarquez le Trier produit plus de lignes (9) qu'il reçoit (3). C'est une bonne indication qu'un Tri a réussi à mettre en cache un ensemble de résultats une ou plusieurs fois - un rembobinage réussi.
Démo 3 : Rien ne rembobiner
J'ai déjà mentionné qu'un Sort non en mémoire peut rembobiner lorsqu'il contient au plus une ligne.
Pour voir cela en action avec zéro ligne , nous changeons en un OUTER APPLY et ne mettez aucune ligne dans la table @T2 . Pour des raisons qui apparaîtront sous peu, nous arrêterons également de projeter la colonne c2 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- No rows added to table @T2
-- No longer projecting c2
SELECT
T1.c1,
--CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
--T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
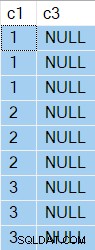
Les résultats ont maintenant NULL dans la colonne c3 comme prévu :
Le plan d'exécution est :
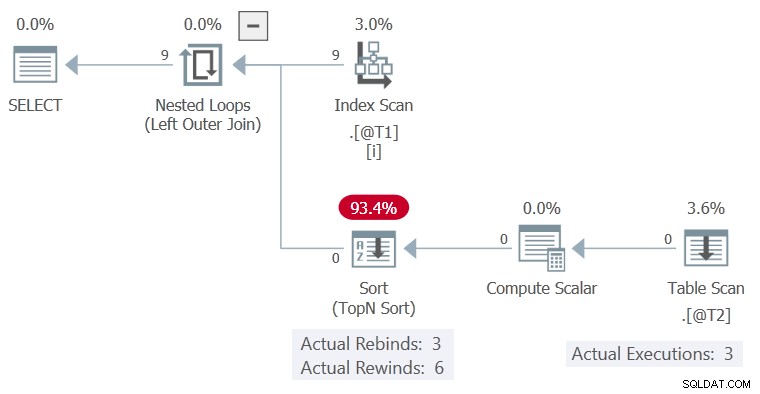
Le Trier a pu rembobiner sans lignes dans son tampon, donc le Table Scan n'a été exécuté que 3 fois, à chaque fois la colonne c1 valeur modifiée.
Démo 4 : Rembobinage maximal !
Comme les autres opérateurs qui prennent en charge les rembobinages, un Sort ne fera que relier son sous-arbre si un paramètre corrélé a changé et le sous-arbre dépend de cette valeur d'une manière ou d'une autre.
Restauration de la colonne c2 la projection de la démo 3 le montrera en action :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Still no rows in @T2
-- Column c2 is back!
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
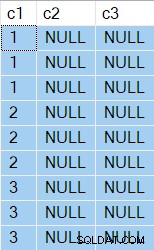
Les résultats montrent maintenant deux NULL colonnes bien sûr :
Le plan d'exécution est assez différent :
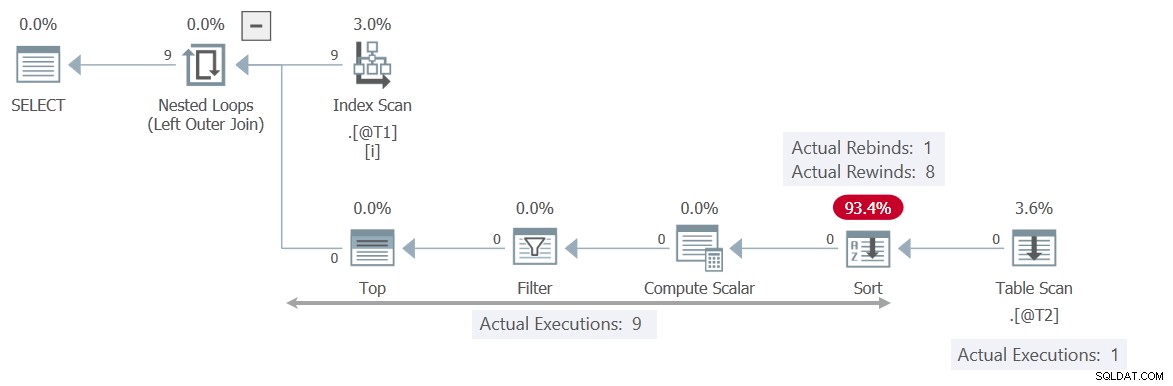
Cette fois, le Filtre contient le chèque T2.c2 = T1.c1 , en effectuant le balayage de table indépendant de la valeur actuelle du paramètre corrélé c1 . Le Trier peut rembobiner en toute sécurité 8 fois, ce qui signifie que l'analyse n'est exécutée qu'une fois .
Démo 5 :Tri en mémoire
L'exemple suivant montre un tri en mémoire opérateur :
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
(REPLICATE('Z', 1390)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); Les résultats que vous obtiendrez varieront d'une exécution à l'autre, mais voici un exemple :
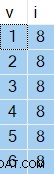
La chose intéressante est les valeurs dans la colonne i sera toujours le même — malgré le ORDER BY NEWID() clause.
Vous aurez probablement déjà deviné que la raison en est le Sort mise en cache des résultats (rembobinage). Le plan d'exécution montre le Balayage Constant s'exécutant une seule fois, produisant 11 lignes au total :
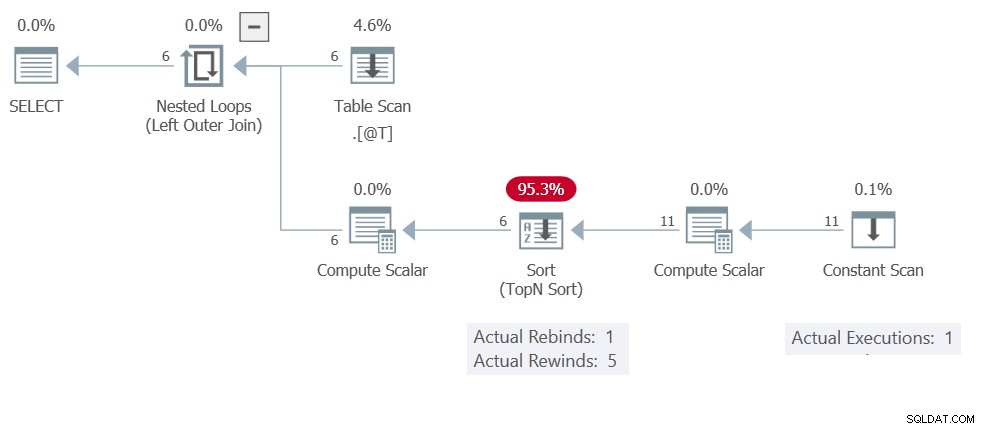
Ce trier a seulement Compute Scalar et Analyse constante opérateurs sur son entrée, il s'agit donc d'un tri en mémoire . N'oubliez pas que ceux-ci ne sont pas limités à une seule ligne au maximum :ils peuvent contenir 500 lignes et 16 Ko.
Comme mentionné précédemment, il n'est pas possible de voir explicitement si un Sort est en mémoire ou non en inspectant un plan d'exécution régulier. Nous avons besoin d'une sortie détaillée du plan de présentation , activé avec l'indicateur de trace non documenté 8666. Lorsque cette option est activée, des propriétés d'opérateur supplémentaires apparaissent :
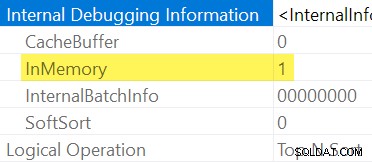
Lorsqu'il n'est pas pratique d'utiliser des indicateurs de trace non documentés, vous pouvez en déduire qu'un Sort est "InMemory" par sa fraction de mémoire d'entrée étant zéro, et Utilisation de la mémoire les éléments ne sont pas disponibles dans le showplan post-exécution (sur les versions de SQL Server prenant en charge ces informations).
Retour au plan d'exécution :Il n'y a pas de paramètres corrélés donc le Trier est libre de rembobiner 5 fois, ce qui signifie le balayage constant n'est exécuté qu'une seule fois. N'hésitez pas à modifier le TOP (1) au TOP (3) ou tout ce que vous aimez. Le rembobinage signifie que les résultats seront les mêmes (en cache/rembobinés) pour chaque ligne d'entrée.
Vous pouvez être gêné par le ORDER BY NEWID() clause n'empêchant pas le rembobinage. C'est en effet un point controversé, mais pas du tout limité aux espèces. Pour une discussion plus complète (avertissement :trou de lapin possible), veuillez consulter ce Q &A. La version courte est qu'il s'agit d'une décision délibérée de conception de produit, optimisant les performances, mais il est prévu de rendre le comportement plus intuitif au fil du temps.
Démo 6 :Pas de tri en mémoire
C'est la même chose que la démo 5, sauf que la chaîne répliquée est plus longue d'un caractère :
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
-- 1391 instead of 1390
(REPLICATE('Z', 1391)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL);
Encore une fois, les résultats varient selon l'exécution, mais voici un exemple. Remarquez le i les valeurs ne sont plus toutes les mêmes :

Le caractère supplémentaire est juste suffisant pour pousser la taille estimée des données triées à plus de 16 Ko. Cela signifie un tri en mémoire ne peut pas être utilisé et les rembobinages disparaissent.
Le plan d'exécution est :
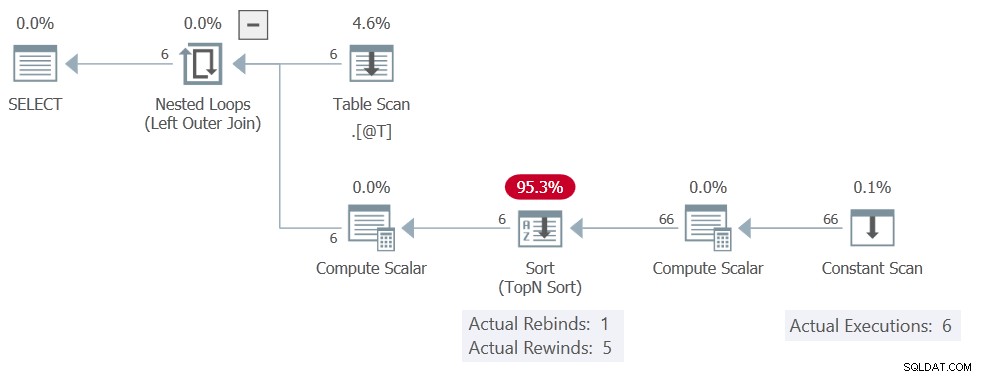
Le Trier toujours des rapports 5 rembobinages, mais le Balayage constant est exécuté 6 fois, ce qui signifie qu'aucun rembobinage n'a vraiment eu lieu. Il produit les 11 lignes sur chacune des 6 exécutions, ce qui donne un total de 66 lignes.
Résumé et réflexions finales
Vous ne verrez pas de Trier opérateur vraiment rembobinant très souvent, même si vous le verrez dire qu'il l'a fait beaucoup.
N'oubliez pas, un tri normal ne peut rembobiner que s'il est sûr et il y a au maximum une ligne dans le tri à la fois. Être "sûr" signifie soit aucun changement dans les paramètres de corrélation de boucle, soit rien en dessous du Sort est affecté par les changements de paramètres.
Un tri en mémoire peut fonctionner sur jusqu'à 500 lignes et 16 Ko de données provenant de Constant Scan et Calculer le scalaire opérateurs uniquement. Il ne rembobinera également que lorsqu'il est sûr (bogues du produit mis à part !) mais n'est pas limité à un maximum d'une ligne.
Cela peut sembler être des détails ésotériques, et je suppose qu'ils le sont. Cela dit, ils m'ont aidé à comprendre un plan d'exécution et à trouver de bonnes améliorations de performances plus d'une fois. Peut-être trouverez-vous également ces informations utiles un jour.
Faites attention aux tris qui produisent plus de lignes qu'ils n'en ont sur leur entrée !
Si vous souhaitez voir un exemple plus réaliste de Trier rembobine sur la base d'une démo fournie par Itzik Ben-Gan dans la première partie de son Closest Match série, veuillez consulter la correspondance la plus proche avec les rembobinages de tri.