Il y a longtemps, j'ai répondu à une question sur NULL sur Stack Exchange intitulée "Pourquoi ne devrions-nous pas autoriser les NULL?" J'ai ma part de bêtes noires et de passions, et la peur des NULL est assez haut sur ma liste. Un collègue m'a récemment dit, après avoir exprimé sa préférence pour forcer une chaîne vide au lieu d'autoriser NULL :
"Je n'aime pas gérer les valeurs nulles dans le code."
Je suis désolé, mais ce n'est pas une bonne raison. La façon dont la couche de présentation traite les chaînes vides ou les valeurs NULL ne devrait pas être le moteur de la conception de votre table et de votre modèle de données. Et si vous autorisez un "manque de valeur" dans une colonne, cela vous importe-t-il d'un point de vue logique que le "manque de valeur" soit représenté par une chaîne de longueur nulle ou un NULL ? Ou pire, une valeur symbolique comme 0 ou -1 pour les entiers, ou 1900-01-01 pour les dates ?
Itzik Ben-Gan a récemment écrit toute une série sur les NULL, et je vous recommande vivement de tout parcourir :
- Complexités NULL – Partie 1
- Complexités NULL – Partie 2
- Complexités NULL – Partie 3, Fonctionnalités standard manquantes et alternatives T-SQL
- Complexités NULL – Partie 4, Contrainte d'unicité standard manquante
Mais mon objectif ici est un peu moins compliqué que cela, après que le sujet ait été abordé dans une autre question Stack Exchange :"Ajouter un champ automatique maintenant à une table existante". Là, l'utilisateur ajoutait une nouvelle colonne à une table existante, avec l'intention de la remplir automatiquement avec la date/heure actuelle. Ils se sont demandé s'ils devaient laisser des valeurs NULL dans cette colonne pour toutes les lignes existantes ou définir une valeur par défaut (comme 1900-01-01, vraisemblablement, même si elles n'étaient pas explicites).
Il peut être facile pour quelqu'un au courant de filtrer les anciennes lignes en fonction d'une valeur de jeton - après tout, comment quelqu'un pourrait-il croire qu'une sorte de gadget Bluetooth a été fabriqué ou acheté le 1900-01-01 ? Eh bien, j'ai vu cela dans les systèmes actuels où ils utilisent une date à consonance arbitraire dans les vues pour agir comme un filtre magique, ne présentant que les lignes où la valeur peut être approuvée. En fait, dans tous les cas que j'ai vus jusqu'à présent, la date dans la clause WHERE est la date/heure à laquelle la colonne (ou sa contrainte par défaut) a été ajoutée. Ce qui est bien; ce n'est peut-être pas la meilleure façon de résoudre le problème, mais c'est une chemin.
Si vous n'accédez pas à la table via la vue, cependant, cette implication d'un connu value peut toujours causer des problèmes à la fois logiques et liés aux résultats. Le problème logique est simplement que quelqu'un qui interagit avec la table doit savoir que 1900-01-01 est une fausse valeur symbolique représentant "inconnu" ou "non pertinent". Pour un exemple concret, quelle était la vitesse de sortie moyenne, en secondes, pour un quart-arrière qui a joué dans les années 1970, avant que nous mesurions ou suivions une telle chose ? 0 est-il une bonne valeur de jeton pour "inconnu" ? Que diriez-vous de -1 ? Ou 100 ? Pour en revenir aux dates, si un patient sans carte d'identité est admis à l'hôpital et est inconscient, que doit-il saisir comme date de naissance ? Je ne pense pas que 1900-01-01 soit une bonne idée, et ce n'était certainement pas une bonne idée à l'époque où il était plus probable que ce soit une vraie date de naissance.
Implications sur les performances des valeurs de jeton
Du point de vue des performances, des valeurs fausses ou « symboliques » telles que 1900-01-01 ou 9999-21-31 peuvent poser des problèmes. Examinons-en quelques-uns avec un exemple basé vaguement sur la question récente mentionnée ci-dessus. Nous avons une table Widgets et, après quelques retours de garantie, nous avons décidé d'ajouter une colonne EnteredService où nous entrerons la date/heure actuelle pour les nouvelles lignes. Dans un cas, nous laisserons toutes les lignes existantes comme NULL, et dans l'autre, nous mettrons à jour la valeur à notre date magique 1900-01-01. (Nous laisserons toute forme de compression hors de la conversation pour l'instant.)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Nous allons maintenant insérer les mêmes 100 000 lignes dans chaque tableau :
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Ensuite, nous pouvons ajouter la nouvelle colonne et mettre à jour 10 % des valeurs existantes avec une distribution des dates actuelles, et les 90 % restants à notre date symbolique uniquement dans l'une des tables :
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Enfin, nous pouvons ajouter des index :
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Espace utilisé
J'entends toujours «l'espace disque est bon marché» lorsque nous parlons de choix de types de données, de fragmentation et de valeurs de jeton par rapport à NULL. Mon souci n'est pas tant avec l'espace disque que ces valeurs supplémentaires sans signification occupent. C'est plus que, lorsque la table est interrogée, elle gaspille de la mémoire. Ici, nous pouvons avoir une idée rapide de l'espace consommé par nos valeurs de jeton avant et après l'ajout de la colonne et de l'index :
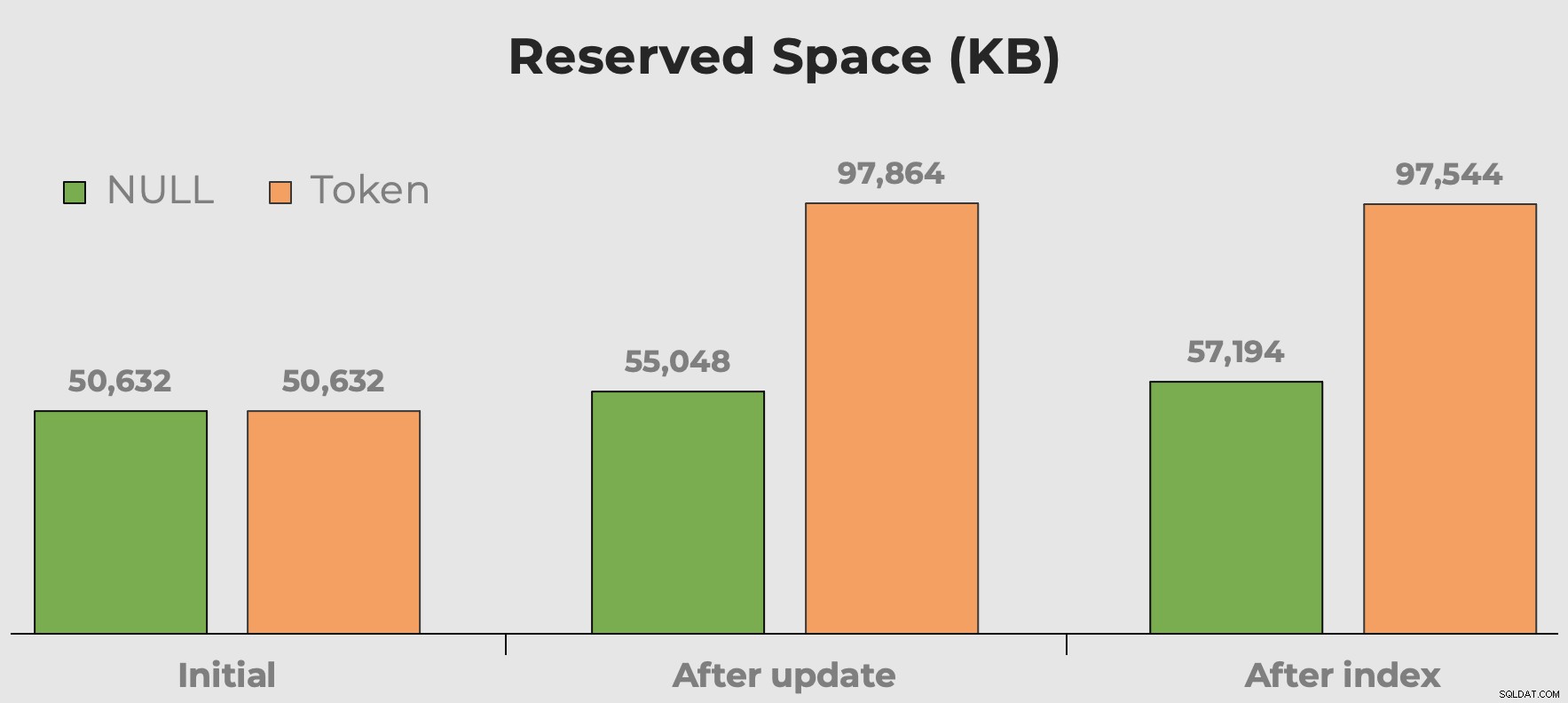 Espace réservé de la table après l'ajout d'une colonne et l'ajout d'un index. L'espace double presque avec les valeurs symboliques.
Espace réservé de la table après l'ajout d'une colonne et l'ajout d'un index. L'espace double presque avec les valeurs symboliques.
Exécution de la requête
Inévitablement, quelqu'un va faire des hypothèses sur les données de la table et interroger la colonne EnteredService comme si toutes les valeurs y étaient légitimes. Par exemple :
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; Les valeurs symboliques peuvent perturber les estimations dans certains cas, mais, plus important encore, elles produiront des résultats incorrects (ou du moins inattendus). Voici le plan d'exécution de la requête sur la table avec des valeurs de jeton :
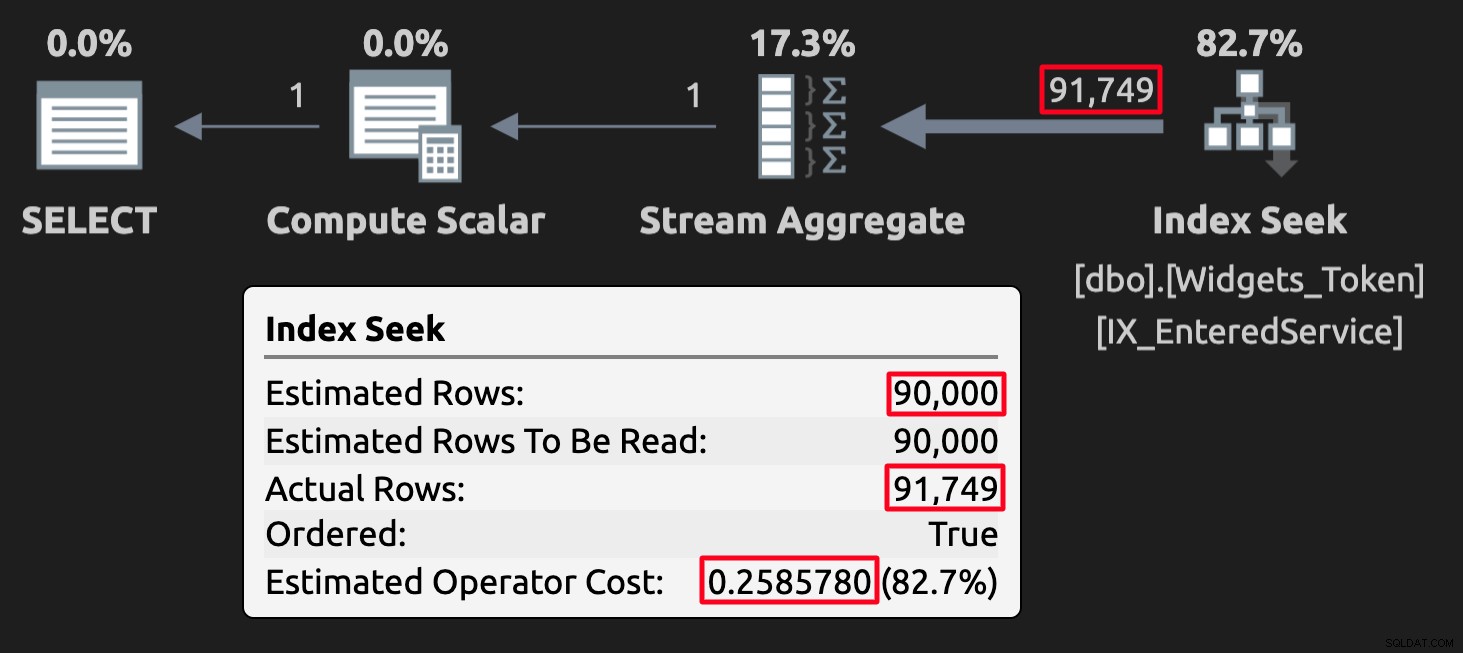 Plan d'exécution pour la table des jetons ; notez le coût élevé.
Plan d'exécution pour la table des jetons ; notez le coût élevé.
Et voici le plan d'exécution de la requête sur la table avec des valeurs NULL :
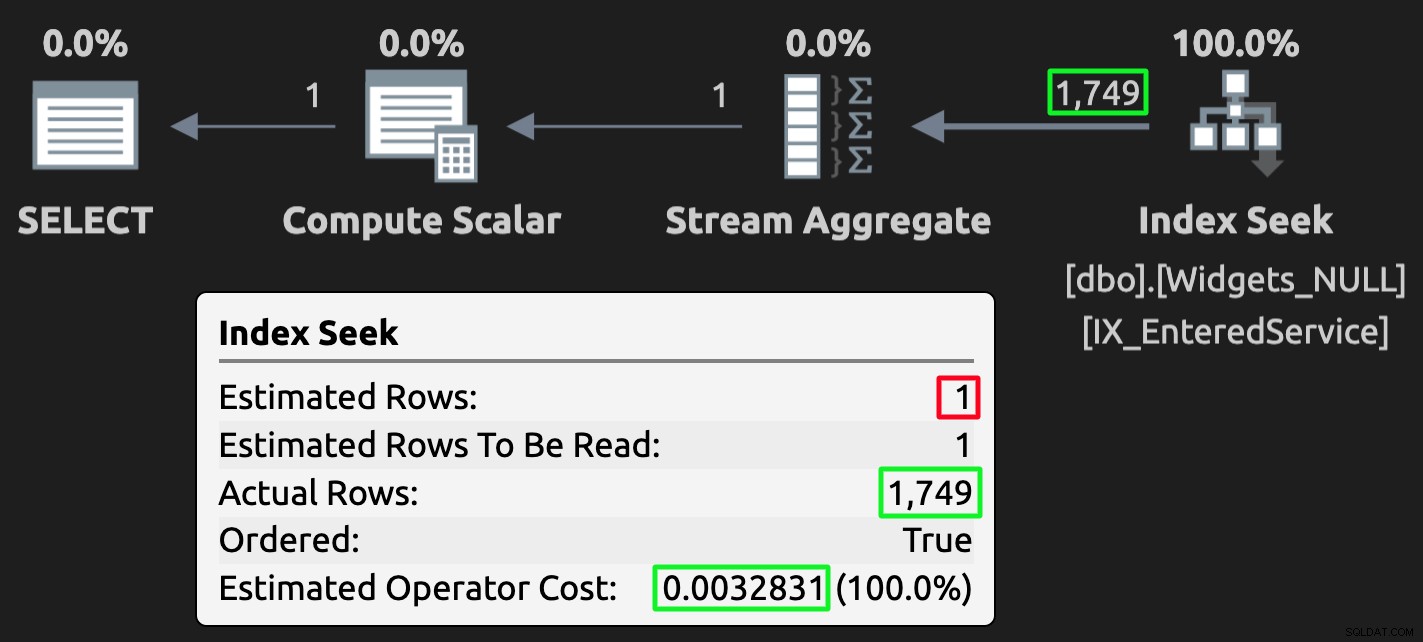 Plan d'exécution pour la table NULL ; mauvaise estimation, mais coût bien inférieur.
Plan d'exécution pour la table NULL ; mauvaise estimation, mais coût bien inférieur.
La même chose se produirait dans l'autre sens si la requête demandait>={une date} et que 9999-12-31 était utilisé comme valeur magique représentant l'inconnu.
Encore une fois, pour les personnes qui savent que les résultats sont faux spécifiquement parce que vous avez utilisé des valeurs symboliques, ce n'est pas un problème. Mais tous ceux qui ne le savent pas, y compris les futurs collègues, les autres héritiers et mainteneurs du code, et même vous qui avez des problèmes de mémoire, vont probablement trébucher.
Conclusion
Le choix d'autoriser les NULL dans une colonne (ou d'éviter complètement les NULL) ne doit pas être réduit à une décision idéologique ou basée sur la peur. Il existe des inconvénients réels et tangibles à l'architecture de votre modèle de données pour vous assurer qu'aucune valeur ne peut être NULL, ou à l'utilisation de valeurs sans signification pour représenter quelque chose qui aurait facilement pu ne pas être stocké du tout. Je ne suggère pas que chaque colonne de votre modèle devrait autoriser les valeurs NULL ; juste que vous ne soyez pas opposé à l'idée de NULL.