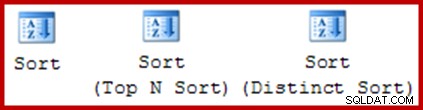
En ce qui concerne les plans d'exécution graphiques, il n'y a qu'une seule icône pour un tri physique dans SQL Server :

Cette même icône est utilisée pour les trois opérateurs de tri logique :Trier, Trier les N premiers et Trier distinct :
En allant plus loin, il existe quatre implémentations différentes de Sort dans le moteur d'exécution (sans compter le tri par lots pour les jointures de boucle optimisées, qui n'est pas un tri complet et n'est de toute façon pas visible dans les plans). Si vous utilisez SQL Server 2014, le nombre d'implémentations du moteur d'exécution Sort passe à sept :
- CQScanSortNouveau
- CQScanTopSortNouveau
- CQScanIndexSortNouveau
- CQScanPartitionSortNew (SQL Server 2014 uniquement)
- CQScanInMemSortNouveau
- Procédure OLTP en mémoire (Hekaton) compilée nativement Top N Sort (SQL Server 2014 uniquement)
- Procédure OLTP en mémoire (Hekaton) compilée nativement Tri général (SQL Server 2014 uniquement)
Cet article examine ces implémentations de tri et leur utilisation dans SQL Server. La première partie couvre les quatre premiers éléments de la liste.
1. CQScanSortNouveau
Il s'agit de la classe de tri la plus générale, utilisée lorsqu'aucune des autres options disponibles n'est applicable. Le tri général utilise une allocation de mémoire d'espace de travail réservée juste avant le début de l'exécution de la requête. Cette subvention est proportionnelle aux estimations de cardinalité et aux attentes de taille de ligne moyenne, et ne peut pas être augmentée après le début de l'exécution de la requête.
L'implémentation actuelle semble utiliser une variété de tri par fusion interne (peut-être un tri par fusion binaire), passant au tri par fusion externe (avec plusieurs passes si nécessaire) si la mémoire réservée s'avère insuffisante. Le tri par fusion externe utilise tempdb physique de l'espace pour les exécutions de tri qui ne tiennent pas dans la mémoire (communément appelée débordement de tri). Le tri général peut également être configuré pour appliquer la distinction lors de l'opération de tri.
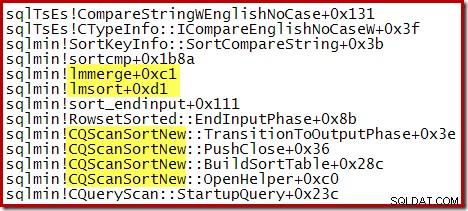
La trace de pile partielle suivante montre un exemple de CQScanSortNew classe triant les chaînes à l'aide d'un tri par fusion interne :
Dans les plans d'exécution, le tri fournit des informations sur la fraction de l'allocation globale de mémoire de l'espace de travail de requête qui est disponible pour le tri lors de la lecture des enregistrements (la phase d'entrée) et la fraction disponible lorsque la sortie triée est consommée par les opérateurs du plan parent (la phase de sortie ).
La fraction d'allocation de mémoire est un nombre compris entre 0 et 1 (où 1 =100 % de la mémoire allouée) et est visible dans SSMS en mettant en surbrillance Trier et en regardant dans la fenêtre Propriétés. L'exemple ci-dessous a été tiré d'une requête avec un seul opérateur de tri, de sorte qu'il dispose de la totalité de l'allocation de mémoire de l'espace de travail de requête disponible pendant les phases d'entrée et de sortie :
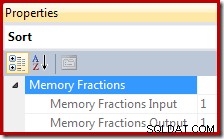
Les fractions de mémoire reflètent le fait qu'au cours de sa phase d'entrée, Sort doit partager l'attribution globale de mémoire de requête avec les opérateurs consommant de la mémoire qui s'exécutent simultanément en dessous dans le plan d'exécution. De même, pendant la phase de sortie, Sort doit partager la mémoire accordée avec les opérateurs consommant de la mémoire qui s'exécutent simultanément au-dessus de lui dans le plan d'exécution.
Le processeur de requêtes est suffisamment intelligent pour savoir que certains opérateurs bloquent (stop-and-go), marquant efficacement les limites où l'allocation de mémoire peut être recyclée et réutilisée. Dans les plans parallèles, la fraction d'allocation de mémoire disponible pour un tri général est répartie uniformément entre les threads et ne peut pas être rééquilibrée au moment de l'exécution en cas de décalage (une cause fréquente de débordement dans les plans de tri parallèles).
SQL Server 2012 et versions ultérieures incluent des informations supplémentaires sur l'allocation de mémoire d'espace de travail minimale requise pour initialiser les opérateurs de plan consommant de la mémoire, et le souhaité allocation de mémoire (la quantité "idéale" de mémoire estimée nécessaire pour terminer l'ensemble de l'opération en mémoire). Dans un plan d'exécution post-exécution ("réel"), il existe également de nouvelles informations sur les retards dans l'acquisition de l'allocation de mémoire, la quantité maximale de mémoire réellement utilisée et la manière dont la réservation de mémoire a été répartie sur les nœuds NUMA.
Les exemples AdventureWorks suivants utilisent tous un CQScanSortNew tri général :
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
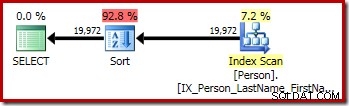
P.LastName; La première requête (un tri non distinct) produit le plan d'exécution suivant :
Les deuxième et troisième requêtes (équivalentes) produisent ce plan :
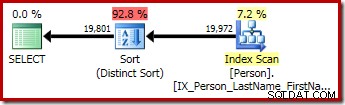
CQScanSortNouveau peut être utilisé à la fois pour le tri général logique et le tri distinct logique.
2. CQScanTopSortNouveau
CQScanTopSortNouveau est une sous-classe de CQScanSortNew utilisé pour implémenter un Top N Sort (comme son nom l'indique). CQScanTopSortNouveau délègue une grande partie du travail de base à CQScanSortNew , mais modifie le comportement détaillé de différentes manières, selon la valeur de N.
Pour N> 100, CQScanTopSortNew est essentiellement juste un CQScanSortNew normal sort qui arrête automatiquement de produire des lignes triées après N lignes. Pour N <=100, CQScanTopSortNew conserve uniquement les résultats Top N actuels pendant l'opération de tri et conserve la trace de la valeur de clé la plus basse actuellement éligible.
Par exemple, lors d'un Top N Sort optimisé (où N <=100) la pile d'appels comporte RowsetTopN alors qu'avec le tri général dans la section 1, nous avons vu RowsetSorted :
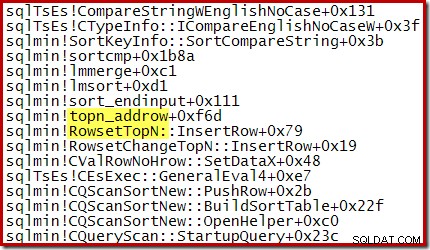
Pour un Top N Sort où N> 100, la pile des appels au même stade d'exécution est la même que le tri général vu précédemment :
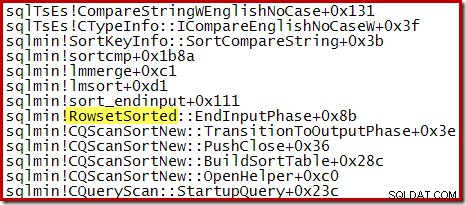
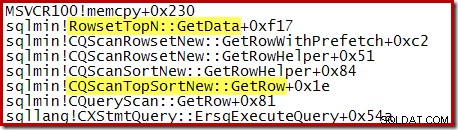
Notez que le CQScanTopSortNew le nom de la classe n'apparaît dans aucune de ces traces de pile. Cela est simplement dû à la façon dont fonctionne la sous-classification. À d'autres moments de l'exécution de ces requêtes, CQScanTopSortNew méthodes (par exemple, Open, GetRow et CreateTopNTable) apparaissent explicitement sur la pile des appels. À titre d'exemple, ce qui suit a été pris à un stade ultérieur de l'exécution de la requête et affiche le CQScanTopSortNew nom de la classe :
Top N Tri et l'optimiseur de requêtes
L'optimiseur de requête ne sait rien de Top N Sort, qui est uniquement un opérateur de moteur d'exécution. Lorsque l'optimiseur produit une arborescence de sortie avec un opérateur physique Top immédiatement au-dessus d'un tri physique (non distinct), une réécriture post-optimisation peut réduire les deux opérations physiques en un seul opérateur Top N Sort. Même dans le cas N> 100, cela représente une économie sur le passage itératif des lignes entre une sortie Sort et une entrée Top.
La requête suivante utilise quelques indicateurs de trace non documentés pour afficher la sortie de l'optimiseur et la réécriture post-optimisation en action :
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
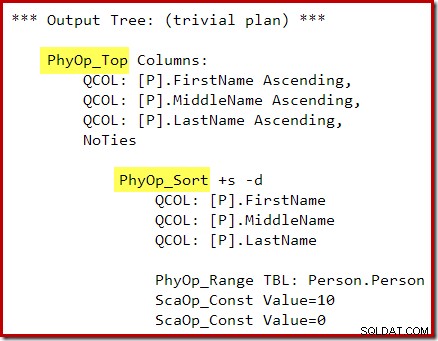
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352); L'arborescence de sortie de l'optimiseur affiche des opérateurs physiques Top et Sort distincts :
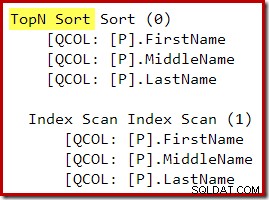
Après la réécriture post-optimisation, le Top et le Sort ont été regroupés en un seul Top N Sort :
Le plan d'exécution graphique de la requête T-SQL ci-dessus montre l'unique opérateur Top N Sort :
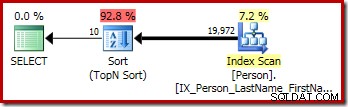
Briser la réécriture du Top N Sort
La réécriture post-optimisation Top N Sort peut uniquement réduire un Top N Sort adjacent et non distinct en un Top N Sort. L'ajout de DISTINCT (ou la clause GROUP BY équivalente) à la requête ci-dessus empêchera la réécriture du Top N Sort :
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Le plan d'exécution final pour cette requête comporte des opérateurs Top et Sort (tri distinct) distincts :
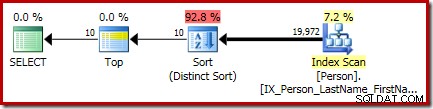
Le tri est le général CQScanSortNew classe s'exécutant en mode distinct comme vu dans la section 1 plus tôt.
Une deuxième façon d'empêcher la réécriture d'un Top N Sort est d'introduire un ou plusieurs opérateurs supplémentaires entre le Top et le Sort. Par exemple :
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; La sortie de l'optimiseur de requêtes se trouve maintenant avoir une opération entre le Top et le Sort, donc un Top N Sort n'est pas généré pendant la phase de réécriture post-optimisation :
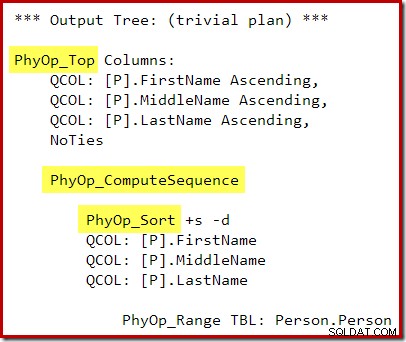
Le plan d'exécution est :

La séquence de calcul (implémentée sous la forme de deux segments et d'un projet de séquence) entre Top et Sort empêche la réduction de Top et Sort en un seul opérateur Top N Sort. Des résultats corrects seront toujours obtenus à partir de ce plan bien sûr, mais l'exécution peut être un peu moins efficace qu'elle aurait pu l'être avec l'opérateur combiné Top N Sort.
3. CQScanIndexSortNouveau
CQScanIndexSortNouveau est utilisé uniquement pour le tri dans les plans de construction d'index DDL. Il réutilise certaines des fonctionnalités de tri générales que nous avons déjà vues, mais ajoute des optimisations spécifiques pour les insertions d'index. C'est aussi la seule classe de tri qui peut demander dynamiquement plus de mémoire après le début de l'exécution.
L'estimation de la cardinalité est souvent précise pour un plan de création d'index, car le nombre total de lignes dans la table est généralement une quantité connue. Cela ne veut pas dire que les allocations de mémoire pour les tris de plan de construction d'index seront toujours exactes; cela le rend juste un peu moins facile à faire la démonstration. Ainsi, l'exemple suivant utilise une extension non documentée, mais raisonnablement connue, de la commande UPDATE STATISTICS pour tromper l'optimiseur en lui faisant croire que la table sur laquelle nous construisons un index n'a qu'une seule ligne :
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; Le plan d'exécution post-exécution ("réel") pour la construction de l'index n'affiche pas d'avertissement pour un tri renversé (lorsqu'il est exécuté sur SQL Server 2012 ou version ultérieure) malgré l'estimation d'une ligne et les 19 972 lignes réellement triées :
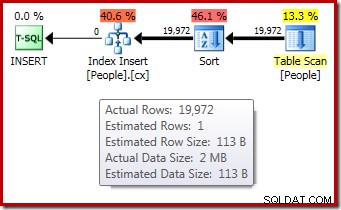
La confirmation que l'allocation de mémoire initiale a été étendue dynamiquement provient de l'examen des propriétés de l'itérateur racine. La requête disposait initialement de 1 024 Ko de mémoire, mais a finalement consommé 1 576 Ko :
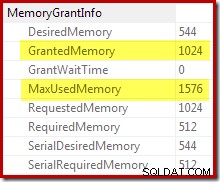
L'augmentation dynamique de la mémoire accordée peut également être suivie à l'aide de l'événement étendu du canal de débogage sort_memory_grant_adjustment. Cet événement est généré chaque fois que l'allocation de mémoire est augmentée dynamiquement. Si cet événement est surveillé, nous pouvons capturer une trace de pile lorsqu'il est publié, soit via des événements étendus (avec une configuration maladroite et un indicateur de trace) ou à partir d'un débogueur attaché, comme ci-dessous :
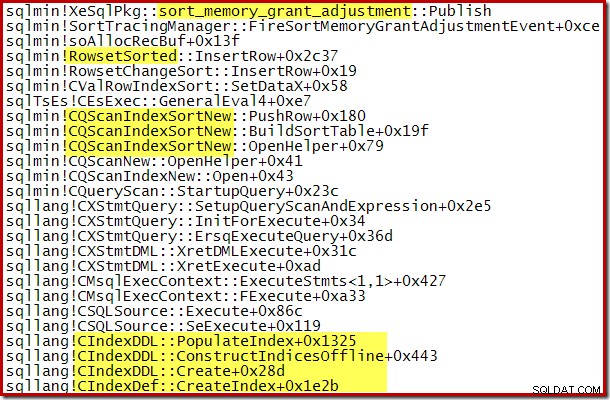
L'extension d'allocation de mémoire dynamique peut également aider avec les plans de construction d'index parallèles où la distribution des lignes entre les threads est inégale. La quantité de mémoire qui peut être consommée de cette façon n'est cependant pas illimitée. SQL Server vérifie chaque fois qu'une extension est nécessaire pour voir si la demande est raisonnable compte tenu des ressources disponibles à ce moment-là.
Un aperçu de ce processus peut être obtenu en activant l'indicateur de trace non documenté 1504, ainsi que 3604 (pour la sortie de message vers la console) ou 3605 (sortie vers le journal des erreurs SQL Server). Si le plan de construction d'index est parallèle, seul 3605 est efficace car les travailleurs parallèles ne peuvent pas envoyer de messages de trace à travers le thread à la console.
La section suivante de la sortie de trace a été capturée lors de la création d'un index modérément volumineux sur une instance SQL Server 2014 avec une mémoire limitée :
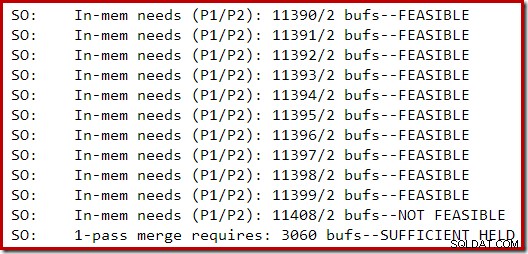
L'expansion de la mémoire pour le tri s'est poursuivie jusqu'à ce que la demande soit considérée comme irréalisable, moment auquel il a été déterminé qu'il y avait déjà suffisamment de mémoire pour qu'un débordement de tri en une seule passe se termine.
4. CQScanPartitionSortNouveau
Ce nom de classe peut suggérer que ce type de tri est utilisé pour les données de table partitionnée ou lors de la création d'index sur des tables partitionnées, mais aucun de ces cas n'est en réalité le cas. Le tri des données partitionnées utilise CQScanSortNew ou CQScanTopSortNew comme d'habitude; le tri des lignes à insérer dans un index partitionné utilise généralement CQScanIndexSortNew comme vu dans la section 3.
Le CQScanPartitionSortNew La classe de tri n'est présente que dans SQL Server 2014. Elle n'est utilisée que lors du tri des lignes par ID de partition, avant l'insertion dans un index clustered columnstore partitionné . Notez qu'il n'est utilisé que pour partitionné magasin de colonnes en cluster ; les plans d'insertion de columnstore en cluster réguliers (non partitionnés) ne bénéficient pas d'un tri.
Les insertions dans un index columnstore clusterisé partitionné ne comporteront pas toujours de tri. Il s'agit d'une décision basée sur les coûts qui dépend du nombre estimé de lignes à insérer. Si l'optimiseur estime qu'il vaut la peine de trier les insertions par partition pour optimiser les E/S, l'opérateur d'insertion columnstore aura le DMLRequestSort propriété définie sur true, et un CQScanPartitionSortNew sort peut apparaître dans le plan d'exécution.
La démonstration de cette section utilise un tableau permanent de numéros séquentiels. Si vous n'en avez pas, le script suivant peut être utilisé pour en créer un :
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); La démo elle-même implique la création d'une table indexée columnstore partitionnée en cluster et l'insertion de suffisamment de lignes (de la table Numbers ci-dessus) pour convaincre l'optimiseur d'utiliser un tri de partition pré-insertion :
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; Le plan d'exécution de l'insertion montre le tri utilisé pour s'assurer que les lignes arrivent à l'itérateur d'insertion clustered columnstore dans l'ordre des ID de partition :

Une pile d'appels capturée pendant que CQScanPartitionSortNew tri était en cours est indiqué ci-dessous :
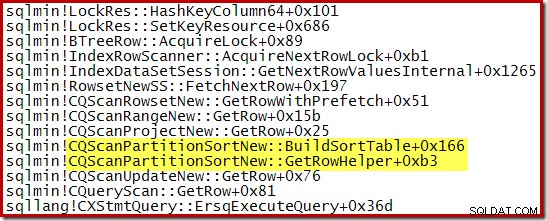
Il y a autre chose d'intéressant dans cette classe de tri. Les tris consomment normalement la totalité de leur entrée dans leur appel de méthode Open. Après le tri, ils rendent le contrôle à leur opérateur parent. Plus tard, le tri commence à produire des lignes de sortie triées une par une de la manière habituelle via des appels GetRow. CQScanPartitionSortNew est différent, comme vous pouvez le voir dans la pile d'appels ci-dessus :il ne consomme pas son entrée pendant sa méthode Open - il attend que GetRow soit appelé par son parent pour la première fois.
Tous les tris sur l'ID de partition qui apparaissent dans un plan d'exécution insérant des lignes dans un index de magasin de colonnes en cluster partitionné ne seront pas un CQScanPartitionSortNew sorte. Si le tri apparaît immédiatement à droite de l'opérateur d'insertion d'index columnstore, il y a de fortes chances qu'il s'agisse d'un CQScanPartitionSortNew trier.
Enfin, CQScanPartitionSortNew est l'une des deux seules classes de tri qui définissent la propriété Soft Sort exposée lorsque les propriétés du plan d'exécution de l'opérateur de tri sont générées avec l'indicateur de trace non documenté 8666 activé :
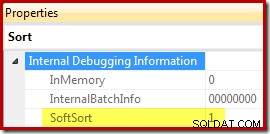
La signification de "sorte douce" dans ce contexte n'est pas claire. Il est suivi en tant que propriété dans le cadre de l'optimiseur de requêtes et semble être lié à des insertions de données partitionnées optimisées, mais déterminer exactement ce que cela signifie nécessite des recherches supplémentaires. En attendant, cette propriété peut être utilisée pour déduire qu'un tri est implémenté avec CQScanPartitionSortNew sans attacher de débogueur. La signification de l'indicateur de propriété InMemory illustré ci-dessus sera couverte dans la partie 2. Il ne le fait pas indiquer si un tri régulier a été effectué en mémoire ou non.
Résumé de la première partie
- CQScanSortNouveau est la classe de tri générale utilisée lorsqu'aucune autre option n'est applicable. Il semble utiliser une variété de tris de fusion internes en mémoire, passant au tri de fusion externe à l'aide de tempdb si l'espace de travail mémoire accordé s'avère insuffisant. Cette classe peut être utilisée pour le tri général et le tri distinct.
- CQScanTopSortNouveau implémente Top N Sort. Où N <=100, un tri par fusion interne en mémoire est effectué et ne déborde jamais sur tempdb . Seuls les n premiers éléments actuels sont conservés en mémoire lors du tri. Pour N> 100 CQScanTopSortNew est équivalent à un CQScanSortNew tri qui s'arrête automatiquement après la sortie de N lignes. Un tri N> 100 peut déborder sur tempdb si nécessaire.
- Le tri Top N vu dans les plans d'exécution est une réécriture d'optimisation post-requête. Si l'optimiseur de requête produit une arborescence de sortie avec un Top adjacent et un tri non distinct, cette réécriture peut réduire les deux opérateurs physiques en un seul opérateur Top N Sort.
- CQScanIndexSortNouveau est utilisé uniquement dans les plans DDL de création d'index. C'est la seule classe de tri standard qui peut dynamiquement acquérir plus de mémoire pendant l'exécution. Les tris de construction d'index peuvent toujours déborder sur le disque dans certaines circonstances, notamment lorsque SQL Server décide qu'une augmentation de mémoire demandée n'est pas compatible avec la charge de travail actuelle.
- CQScanPartitionSortNew n'est présent que dans SQL Server 2014 et est utilisé uniquement pour optimiser les insertions dans un index columnstore cluster partitionné. Il fournit un "tri doux".
La deuxième partie de cet article se penchera sur CQScanInMemSortNew , et les deux tris de procédures stockées OLTP en mémoire compilées en mode natif.