Ceci fait partie d'une série d'opérateurs problématiques internes de SQL Server. Assurez-vous de lire le premier message et le deuxième message de Kalen sur ce sujet.
SQL Server existe depuis plus de 30 ans, et je travaille avec SQL Server depuis presque aussi longtemps. J'ai vu beaucoup de changements au fil des années (et des décennies !) et des versions de cet incroyable produit. Dans ces articles, je vais partager avec vous comment j'examine certaines des fonctionnalités ou certains aspects de SQL Server, parfois avec un peu de perspective historique.
La dernière fois, j'ai parlé du hachage dans un plan de requête SQL Server en tant qu'opérateur potentiellement problématique dans les diagnostics du serveur SQL. Le hachage est fréquemment utilisé pour les jointures et l'agrégation lorsqu'il n'y a pas d'index utile. Et comme les analyses (dont j'ai parlé dans le premier article de cette série), il y a des moments où le hachage est en fait un meilleur choix que les alternatives. Pour les jointures par hachage, l'une des alternatives est LOOP JOIN, dont je vous ai également parlé la dernière fois.
Dans cet article, je vais vous parler d'une autre alternative au hachage. La plupart des alternatives au hachage nécessitent que les données soient triées, donc soit le plan doit inclure un opérateur SORT, soit les données requises doivent déjà être triées en raison des index existants.
Différents types de jointures pour les diagnostics SQL Server
Pour les opérations JOIN, le type de JOIN le plus courant et le plus utile est un LOOP JOIN. J'ai décrit l'algorithme pour un LOOP JOIN dans le post précédent. Bien que les données elles-mêmes n'aient pas besoin d'être triées pour un LOOP JOIN, la présence d'un index sur la table interne rend la jointure beaucoup plus efficace et comme vous devez le savoir, la présence d'un index implique un certain tri. Alors qu'un index clusterisé trie les données elles-mêmes, un index non clusterisé trie les colonnes de clé d'index. En fait, dans la plupart des cas, sans l'index, l'optimiseur de SQL Server choisira d'utiliser l'algorithme HASH JOIN. Nous l'avons vu dans l'exemple la dernière fois, que sans index, HASH JOIN a été choisi, et avec des index, nous avons obtenu un LOOP JOIN.
Le troisième type de jointure est un MERGE JOIN. Cet algorithme fonctionne sur deux jeux de données déjà triés. Si nous essayons de combiner (ou JOIN) deux ensembles de données déjà triés, il suffit d'un seul passage dans chaque ensemble pour trouver les lignes correspondantes. Voici le pseudocode de l'algorithme de jointure par fusion :
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Bien que MERGE JOIN soit un algorithme très efficace, il nécessite que les deux ensembles de données d'entrée soient triés par la clé de jointure, ce qui signifie généralement avoir un index clusterisé sur la clé de jointure pour les deux tables. Étant donné que vous n'obtenez qu'un seul index clusterisé par table, choisir la colonne de clé clusterisée uniquement pour permettre aux MERGE JOINS de se produire n'est peut-être pas le meilleur choix global pour la clé de clustering.
Donc, généralement, je ne vous recommande pas d'essayer de créer des index uniquement dans le but de MERGE JOINS, mais si vous finissez par obtenir un MERGE JOIN en raison d'index déjà existants, c'est généralement une bonne chose. En plus d'exiger que les deux ensembles de données d'entrée soient triés, MERGE JOIN exige également qu'au moins un des ensembles de données ait des valeurs uniques pour la clé de jointure.
Prenons un exemple. Tout d'abord, nous allons recréer les en-têtes et Détails tableaux :
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Ensuite, regardez le plan d'une jointure entre ces tables :
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Voici le programme :

Notez que même avec un index clusterisé sur les deux tables, nous obtenons un HASH JOIN. Nous pouvons reconstruire l'un des index pour qu'il soit UNIQUE. Dans ce cas, il doit s'agir de l'index sur les Headers table, car c'est la seule qui a des valeurs uniques pour SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Maintenant, exécutez à nouveau la requête et notez que le plan fonctionne comme un MERGE JOIN.

Ces plans bénéficient du fait que les données sont déjà triées dans un index, car le plan d'exécution peut tirer parti du tri. Mais parfois, SQL Server doit effectuer un tri dans le cadre de l'exécution de sa requête. Vous pouvez parfois voir un opérateur SORT apparaître dans un plan même si vous ne demandez pas de sortie triée. Si SQL Server pense qu'un MERGE JOIN peut être une bonne option, mais que l'une des tables n'a pas l'index clusterisé approprié et qu'il est suffisamment petit pour rendre le tri très peu coûteux, un SORT peut être effectué pour permettre à MERGE JOIN d'être utilisé.
Mais généralement, l'opérateur SORT apparaît dans les requêtes où nous avons demandé des données triées avec ORDER BY, comme dans l'exemple suivant.
SELECT * FROM Details
ORDER BY ProductID;
GO

L'index clusterisé est analysé (ce qui revient à analyser la table), puis les lignes sont triées comme demandé.
Traitement d'un index groupé déjà trié
Mais que se passe-t-il si les données sont déjà triées dans un index clusterisé et que la requête inclut un ORDER BY sur la colonne de clé clusterisée ? Dans l'exemple ci-dessus, nous avons créé un index clusterisé sur SalesOrderID dans la table Details. Examinez les deux requêtes suivantes :
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Si nous exécutons ces requêtes ensemble, la fenêtre d'analyse du pack de réglages Quest Spotlight indique que les deux plans ont un coût égal ; chacun représente 50 % du total. Alors, quelle est réellement la différence entre eux ?
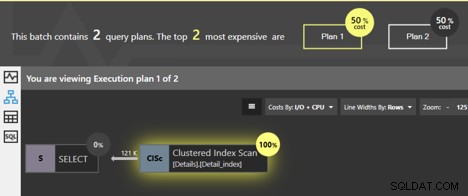
Les deux requêtes analysent l'index clusterisé et SQL Server sait que si les pages du niveau feuille sont suivies dans l'ordre, les données reviendront dans l'ordre des clés clusterisées. Aucun tri supplémentaire n'est nécessaire, donc aucun opérateur SORT n'est ajouté au plan. Mais il y a une différence. Nous pouvons cliquer sur l'opérateur Clustered Index Scan et obtenir des informations détaillées.
Tout d'abord, regardez les informations détaillées pour le premier plan, pour la requête sans ORDER BY.

Les détails nous indiquent que la propriété "Commandé" est fausse. Il n'est pas nécessaire ici que les données soient renvoyées dans un ordre trié. Il s'avère que dans la plupart des cas, le moyen le plus simple de récupérer les données est de suivre les pages de l'index clusterisé, de sorte que les données finiront par être renvoyées dans l'ordre, mais il n'y a aucune garantie. La propriété False signifie qu'il n'est pas nécessaire que SQL Server suive les pages ordonnées pour renvoyer le résultat. Il existe en fait d'autres façons pour SQL Server d'obtenir toutes les lignes de la table, sans suivre l'index clusterisé. Si lors de l'exécution, SQL Server choisit d'utiliser une méthode différente pour obtenir les lignes, nous ne verrons pas les résultats triés.
Pour la deuxième requête, les détails ressemblent à ceci :
 Étant donné que la requête incluait un ORDER BY, il EST nécessaire que les données soient renvoyées dans un ordre trié et que SQL Server suivra les pages de l'index clusterisé, dans l'ordre.
Étant donné que la requête incluait un ORDER BY, il EST nécessaire que les données soient renvoyées dans un ordre trié et que SQL Server suivra les pages de l'index clusterisé, dans l'ordre.
La chose la plus importante à retenir ici est qu'AUCUNE garantie de données triées si vous n'incluez pas ORDER BY dans votre requête. Juste parce que vous avez un index clusterisé, il n'y a toujours aucune garantie ! Même si chaque fois que vous avez exécuté la requête l'année dernière, vous avez remis les données dans l'ordre sans ORDER BY, il n'y a aucune garantie que vous continuerez à remettre les données dans l'ordre. L'utilisation de ORDER BY est le seul moyen de garantir l'ordre dans lequel vos résultats sont renvoyés.
Conseils pour l'utilisation des opérations de tri
Alors, un SORT est-il une opération à éviter dans les diagnostics du serveur SQL ? Tout comme les scans et les opérations de hachage, la réponse est, bien sûr, "ça dépend". Le tri peut être très coûteux, en particulier sur les grands ensembles de données. Une indexation correcte aide SQL Server à éviter d'effectuer des opérations SORT, car un index signifie essentiellement que vos données sont pré-triées. Mais l'indexation a un coût. Il y a un coût de stockage, en plus du coût de maintenance, pour chaque index. Si vos données sont fortement mises à jour, vous devez limiter le nombre d'index au minimum.
Si vous constatez que certaines de vos requêtes lentes affichent des opérations SORT dans leurs plans, et si ces opérateurs SORT figurent parmi les opérateurs les plus coûteux du plan, vous pouvez envisager de créer des index qui permettent à SQL Server d'éviter le tri. Mais vous devrez effectuer des tests approfondis pour vous assurer que les index supplémentaires ne ralentissent pas les autres requêtes qui sont cruciales pour les performances globales de votre application.