Un index, clusterisé ou non, peut être utilisé par l'optimiseur de requête si et seulement si la clé la plus à gauche de l'index est filtrée. Donc si vous définissez un index sur les colonnes (A, B, C), une condition WHERE sur example@sqldat.com , sur example@sqldat.com ou sur example@sqldat.com AND example@sqldat.com ne tirera pas pleinement parti de l'indice (voir note). Ceci s'applique également aux conditions d'adhésion. Tout filtre WHERE qui inclut A considérera l'index :example@sqldat.com ou example@sqldat.com AND example@sqldat.com ou example@sqldat.com AND example@sqldat.com ou example@sqldat.com AND example@sqldat.com AND example@sqldat.com .
Donc, dans votre exemple, si vous créez l'index cluster sur part_no comme clé la plus à gauche, puis une requête recherchant un part_id spécifique ne va pas utiliser l'index et un index séparé non clusterisé doit exister sur part-id .
Passons maintenant à la question de savoir lequel des nombreux index devrait être le cluster une. Si vous avez plusieurs modèles de requête qui ont à peu près la même importance et la même fréquence et se contredisent en termes de clés nécessaires (par exemple, requêtes fréquentes par soit part_no ou part_id ) alors vous prenez d'autres facteurs en considération :
- largeur :la clé d'index clusterisée est utilisée comme clé de recherche par tous d'autres index non clusterisés. Donc, si vous choisissez une clé large (disons deux colonnes uniquidentifier), vous agrandissez tous les autres index, consommant ainsi plus d'espace, générant plus d'E/S et ralentissant tout. Ainsi, entre des clés également bonnes du point de vue de la lecture, choisissez la plus étroite en tant que cluster et rendez les plus larges non clusterisées.
- contestation :si vous avez des modèles spécifiques d'insertion et de suppression, essayez de les séparer physiquement afin qu'ils se produisent sur différentes parties de l'index clusterisé. Par exemple. si la table agit comme une file d'attente avec toutes les insertions à une extrémité logique et toutes les suppressions à l'autre extrémité logique, essayez de mettre en page l'index clusterisé de sorte que l'ordre physique corresponde à cet ordre logique (par exemple, l'ordre de mise en file d'attente).
- partitionnement :si la table est très volumineuse et que vous envisagez de déployer le partitionnement, la clé de partitionnement doit être l'index clusterisé. Un exemple typique est celui des données historiques archivées à l'aide d'un schéma de partitionnement à fenêtre coulissante. Même si les entités ont une clé primaire logique comme 'entity_id', l'index cluster est fait par une colonne datetime qui est également utilisée pour la fonction de partitionnement.
- stabilité :une clé qui change souvent est un mauvais candidat pour une clé en cluster car chacun met à jour la valeur de la clé en cluster et force tous index non clusterisés pour mettre à jour la clé de recherche qu'ils stockent. Étant donné qu'une mise à jour d'une clé en cluster déplacera également probablement l'enregistrement dans une autre page, cela peut entraîner une fragmentation de l'index en cluster.
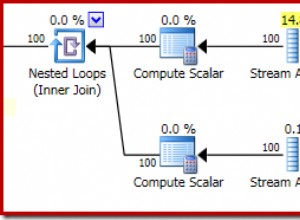
Remarque :pas entièrement effet de levier car parfois le moteur choisira un index non clusterisé à analyser au lieu de l'index clusterisé simplement parce qu'il est plus étroit et a donc moins de pages à analyser. Dans mon exemple si vous avez un index sur (A, B, C) et un filtre WHERE sur example@sqldat.com et la requête projette C , l'index sera probablement utilisé mais pas comme une recherche, comme une analyse, car il est toujours plus rapide qu'une analyse groupée complète (moins de pages).