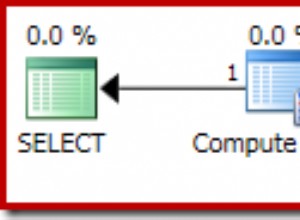
Qu'est-ce qui fait que la requête d'application croisée fonctionne si mal sur ce simple document XML et ralentit de manière exponentielle à mesure que l'ensemble de données augmente ?
C'est l'utilisation de l'axe parent pour obtenir l'ID d'attribut à partir du nœud de l'élément.
C'est cette partie du plan de requête qui pose problème.

Remarquez les 423 lignes issues de la fonction de table inférieure.
L'ajout d'un seul nœud d'élément supplémentaire avec trois nœuds de champ vous donne cela.
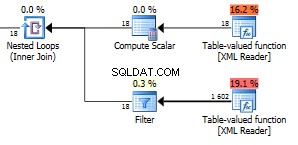
732 lignes renvoyées.
Et si nous doublions les nœuds de la première requête pour un total de 6 nœuds d'éléments ?
Nous sommes jusqu'à un énorme 1602 lignes retournées.
Le chiffre 18 dans la fonction du haut correspond à tous les nœuds de champ de votre XML. Nous avons ici 6 éléments avec trois champs dans chaque élément. Ces 18 nœuds sont utilisés dans une jointure de boucles imbriquées contre l'autre fonction, donc 18 exécutions renvoyant 1602 lignes donnent qu'il renvoie 89 lignes par itération. Il se trouve que c'est le nombre exact de nœuds dans tout le XML. Eh bien, c'est en fait un de plus que tous les nœuds visibles. Je ne sais pas pourquoi. Vous pouvez utiliser cette requête pour vérifier le nombre total de nœuds dans votre XML.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Ainsi, l'algorithme utilisé par SQL Server pour obtenir la valeur lorsque vous utilisez l'axe parent .. dans une fonction de valeurs est qu'elle trouve d'abord tous les nœuds sur lesquels vous déchiquetez, 18 dans le dernier cas. Pour chacun de ces nœuds, il détruit et renvoie l'intégralité du document XML et vérifie dans l'opérateur de filtre le nœud que vous souhaitez réellement. Là, vous avez votre croissance exponentielle. Au lieu d'utiliser l'axe parent, vous devez utiliser une croix supplémentaire. Déchiquetez d'abord sur l'article, puis sur le terrain.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
J'ai également changé la façon dont vous accédez à la valeur textuelle du champ. Utilisation de . fera en sorte que SQL Server recherche les nœuds enfants dans field et concaténer ces valeurs dans le résultat. Vous n'avez pas de valeurs enfants donc le résultat est le même mais c'est une bonne chose d'éviter d'avoir cette partie dans le plan de requête (l'opérateur UDX).
Le plan de requête n'a pas de problème avec l'axe parent si vous utilisez un index XML, mais vous bénéficierez toujours de la modification de la façon dont vous récupérez la valeur du champ.